
https://arxiv.org/abs/2410.13842
D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
We introduce D-FINE, a powerful real-time object detector that achieves outstanding localization precision by redefining the bounding box regression task in DETR models. D-FINE comprises two key components: Fine-grained Distribution Refinement (FDR) and Gl
arxiv.org
Motivation.
기존 DETR의 경우 bbox를 예측하는 regression의 경우 IoU loss를 사용하거나 bbox의 좌표들에 대한 L1 loss를 이용해서 학습합니다. 하지만, 이는 bbox를 정확히 예측하는 데에 있어서 충분한 정보를 제공하지 못합니다. target을 기준으로 IoU loss나 L1 loss를 사용하는 경우, target(GT)의 bbox의 좌표값인 x1, x2, y1, y2는 "진짜 bbox의 좌표는 이 값!" 이라는 가정을 사용합니다. 이는 이미지에 blur가 발생하거나 저해상도 문제로 인해 각 bbox의 좌표의 신뢰도가 달라질 수 있다는 점을 간과합니다.
이때, L1 loss를 사용하면 이로 인한 loss는 |(target 좌표) - (prediction 좌표)|이기 때문에 gradient는 ±1입니다. 즉, 어느 edge를 더 강하게 이동시켜야하는지 등의 디테일이 떨어집니다. IoU loss의 경우, IoU가 0이면 gradient를 흘릴 수 없으며, IoU를 늘리기 위해서만 행동할 뿐, 각 edge를 어떻게 움직여야한다. 와 같은 디테일한 정보를 학습할 수는 없습니다.
해당 논문에서는 각 edge별로 loss를 주어서 디테일한 bbox 학습을 하며, target의 bbox의 좌표를 Dirac delta 분포(하나의 값)로 사용하지 않고, 일종의 확률 분포로서 다루어서 부드럽게 학습할 수 있도록 합니다.
https://en.wikipedia.org/wiki/Dirac_delta_function
Dirac delta function - Wikipedia
en.wikipedia.org
한편, DETR의 느린 수렴 속도를 해결하기 위해 해당 논문의 저자는 Knowledge Distillation (지식 증류, KD)를 사용합니다. 하지만 일반적인 logit mimicking이나 feature Imitation과 같은 KD 방법론들은 detection 성능을 떨어뜨린다고 알려져있습니다(Zheng et al., 2022). 따라서 해당 논문의 저자는 localization, 즉 bbox의 좌표를 예측하는데에 있어서만 증류를 사용합니다.
Preliminaries.
이전에도 bbox의 좌표를 일종의 분포로서 다루는 방법론들이 있었습니다. GFocal(Li et al., 2020;2021)은 그 대표적인 예시입니다. bbox의 좌표가 일정한 bin에 속할 확률을 모델이 예측합니다. 사용한 bbox distance d = {t, b, l, r}은 다음과 같습니다:

dmax는 분포의 최대값, N은 bin의 개수, P(n)은 예측한 좌표값이 n번째 bin에 속할 확률입니다. 예를 들어, dmax는 10, N=5 이라고 했을 때, P(n) = [0.05, 0.1, 0.15, 0.6, 0.1] 이라고 가정합니다. 그러면 dmax는 해당 모델이 예측할 수 있는 최대 좌표를 의미합니다. N은 구간의 개수로, 각 구간은 [0,2], [2,4], [4,6], [6,8], [8,10] 입니다. 이때 P(n) = [0.05, 0.1, 0.15, 0.6, 0.1] 이기 때문에 각 구간에 속할 확률은 P([0,2]) = 0.05 ... 과 같이 해석할 수 있습니다.
이때 distance를 구하면, 10*(1/5)*0.05 + 10*(2/5)*0.1 + ... = 7.2 입니다. 따라서 위의 예시의 경우 distance를 7.2로 예측할 수 있습니다. 이렇게 top, bottom, left, right bbox에 대한 확률 분포로서 distance를 구할 수 있습니다.
Method.
Overview.

Fine-grained Distribution Refinement (FDR).
이 방법은 가장 처음 initial bbox를 예측한 다음, 각 decoder의 layer마다는 initial bbox에서 얼마나 더 움직여야하는지, 그 잔차(residual)을 학습합니다. 그리고 그 잔차에 대한 거리를 사전 학습부분에서 다뤘던 확률 분포로서 다룹니다. 이렇게 각 layer마다 bbox의 regression을 반복적으로 수행하면서 점점 정확한 bbox을 예측해가는 것입니다.
initial bbox를 b0라고 했을 때, 초기 distance d0는 b0의 중심 c0로부터의 top, bottom, left, right edge의 거리로 초기화합니다. 이때 l-th layer에 대해 bbox는 다음과 같이 예측됩니다:

Pr()은 n번째 bin에 속할 확률 분포로서, Pr은 각각 Prt, Prb, Prl, Prr에 해당하는 top, bottom, left, right에 대한 edge distance의 확률 분포입니다. 한편, 사전 학습에서 봤던 균등한 두깨(폭)의 bin과 달리 해당 논문에서는 W(n)으로 bin의 두깨(폭)를 설정합니다. W(n)은 다음과 같이 정의됩니다:
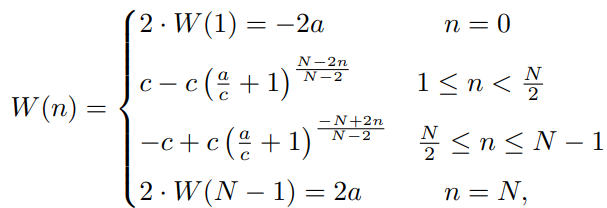

bbox를 예측하는 경우 bin의 폭을 설정하는 것은 매우 중요합니다. 예를 들어, 정말 미세하게 예측하고자, bin의 폭을 매우 얇게(N이 크게) 설정한다면, 미세한 조절을 가능하겠지만, 최종 prediction의 logit 차원이 매우 커지게 됩니다. 하지만 그렇다고 bin의 폭을 두껍게 설정하면, bbox의 distance가 큰 폭으로 크게 크게 밖에 조절할 수 없을 것입니다. 즉, GT bbox와 거리가 매우 많이 차이가 난다면 bin의 폭을 크게 설정해서 큰 폭으로 한 번에 움직이고, GT bbox와 거의 겹쳐져서 조금씩만 조절하면 될 때는 bin의 폭을 작게 설정하여 조금씩만 움직이게 하는 것이 중요합니다.
이를 달성하기 위해, bin의 폭을 n에 따라서 달라지도록 설정하는 함수가 W()입니다. W()는 예측하는 n이 중간(N/2)에 멀리 떨어지면(0이나 N에 가까우면) bin의 폭이 크게 크게 달라지고(기울기가 크다), bin의 폭의 값이 -2a나 2a로 큰 값이 설정됩니다. 반면 n이 중간에 가깝다면 bin의 폭이 거의 달라지지 않고(기울기가 작다), bin의 폭의 값이 거의 0에 가까운 값으로 설정됩니다.
한편, l-th layer의 Pr은 다음과 같이 정의됩니다:

l-1-th layer의 출력 logit에 대해 l-th layer의 출력 logit을 더해줌으로써 Pr()을 출력합니다. 즉, l-th layer는 l-1-th layer에 대해서 어느 정도를 "더" 움직여야 하는지(잔차)에 대해서 학습하는 것입니다. 예를 들어, 이미 l-1번째 layer에서 GT bbox와 거의 겹친다면 l번째 layer에서는 "더 움직일 것"이 없기 때문에 l번째 출력 logit은 0이 되도록 학습할 것입니다. 반면에 l-1번째 layer에서 GT bbox로 가기 위해서는 top방향으로 10만큼, bottom방향으로는 -2, left방향으로는 0, right방향으로는 -3만큼 더 움직여야 한다면 l번째 layer의 출력 logit은 이에 해당하는 차이만큼에 대해 출력하도록 학습될 것입니다.
이런 residual regression에 대한 loss는 다음과 같습니다:

ϕ는 initial bbox와 GT의 distance입니다. ϕ와 가장 가까운 오른쪽 bin, ϕ와 가장 가까운 왼쪽 bin입니다. 아래는 ϕ의 정의입니다:

하나 하나 해석해보겠습니다. 우선 가장 바깥에 있는 sigma에 따르면 각 layer에서 나오는 loss들을 모두 더해줌으로써 최종 loss를 구한다는 것을 알 수 있습니다. 그리고 그 안에 있는 sigma에 따르면 K번째 prediction에서 나오는 loss들을 모두 더해줌으로써 loss를 구한다는 것을 알 수 있습니다. 그리고 IoU score를 구함으로써 IoU가 높은 경우 더 정확하게 예측할 수 있도록 가중치를 부여합니다.
w<-는 ϕ와 n->사이의 거리가 커지면, 이 값이 분자이기 때문에 커지게 됩니다. 즉, ϕ와 n<-가 가까우면 w<-는 커집니다.
반대로 w->는 ϕ와 n<-사이의 거리가 커지면, 이 값이 분자이기 때문에 커지게 됩니다. 즉, ϕ와 n->가 가까우면 w->는 커집니다.
즉, CE loss에 대한 가중치로 ϕ와 n<-, n->의 거리를 사용하는 것입니다. 예를 들어, ϕ가 n->과 더 가까우면 w->는 커지기 때문에, n->과 Pr(n)간의 CE loss에 대한 가중치가 커집니다. 더 가까운 bin에 대해서 더 정확하게 맞추는 것이 중요하기 때문입니다.
CE(Pr(n), n)은 n번째 bin에 해당하는 dirac delta 분포와 Pr(n)에 대한 분포의 CE loss를 말합니다.
Global Optival Localization Self-Distillation (GO-LSD).
GO-LSD는 FSD에서 나오는 확률 분포를 distillation합니다. 더 깊은 층에서 나오는 Pr()을 얕은 층에서 나오도록 학습 시킴으로써, 얕은 층은 기존의 깊은 층에서 예측하는 분포를 만들고, 깊은 층은 더욱 더 깊은 예측을 수행하도록 합니다. 이를 그림으로 나타내면 다음과 같습니다:

이때 모든 예측 분포에 대해서 distillation을 수행하면 옳지 않은 정보까지 그대로 학습할 수도 있습니다. 따라서 layer들을 거듭하면서 GT와 한 번이라도 matching이 되는 경우의 prediction의 확률 분포를 M집합으로, 한 번도 matching이 되지 않은 prediction의 경우의 확률 분포를 U집합으로 Union합니다. 정확한 distillation loss는 다음과 같습니다:

Km과 Ku는 각각 M집합과 U집합의 원소 개수입니다. 즉, 가장 마지막 layer L의 출력을 이용해서 증류하기 때문에 sigma가 L-1까지 되어있음을 볼 수 있습니다. 그리고 각 layer l에 대해서, L번째 layer의 출력과 똑같아지도록 KL loss를 달아줍니다. 이때 Km에 대해서는 IoU에 대한 가중치를, Ku에 대해서는 confidence에 대한 가중치를 부여합니다.
이를 해석해보자면,
matching이 한 번이라도 된 경우에는 GT와 prediction의 IoU가 높다면, 가중치를 더 주어서 더욱 더 중요하게 distillation해야하는 sample이라는 것을 뜻합니다. 반면에, IoU가 낮다면 그렇게까지 중요하게 증류하지 않아도 되는 정보라는 것을 뜻합니다.
한편, matching이 한 번도 안된 경우에, GT와 prediction의 그나마 Classification confidence가 크다면 증류해야하는 sample이지만, cls confidence마저 낮다면 증류하지 않아도 되는 sample임을 뜻합니다.
개인적으로 unmatching이 된 sample의 경우는 왜 distillation해야하는지 모르겠습니다. confidence를 가중치로 두어서 쓸모없은 정보는 증류하지 않는다고 하지만, 이때 Pr은 bbox regression에 대한 정보인데 이에 대한 정보의 증류의 가중치를 confidence를 이용하는 것은 앞뒤가 안 맞는 느낌입니다...
Results.

표 1. 은 기존의 real-time object detection 모델과 제안한 모델의 성능을 비교한 모습입니다. 가장 좋은 성능을 보임을 알 수 있습니다.

표 5. 는 다른 KD 방법론과 제안한 GO-LSD 방법론을 적용했을 때의 성능 차이를 보여줍니다. 이를 통해 GO-LSD 방법론이 우수함을 증명합니다.