
https://arxiv.org/abs/2407.12067
MaskVD: Region Masking for Efficient Video Object Detection
Video tasks are compute-heavy and thus pose a challenge when deploying in real-time applications, particularly for tasks that require state-of-the-art Vision Transformers (ViTs). Several research efforts have tried to address this challenge by leveraging t
arxiv.org
Abstract.
비디오를 이용하는 작업들은 computation-heavy 하기 때문에 실시간 애플리케이션에 배포하는 데 어려움이 있으며, 특히 ViT를 필요로 하는 작업에서는 더욱 그렇습니다. 여러 연구들이 video frames들의 상당 부분이 시간 흐름에 따라 거의 변하지 않아 프레임 깁반 처리 시 중복 연산이 발생한다는 점에 착안하여 이 문제를 해결하고자 했습니다. 일부 연구들은 프레임 간의 pixel 또는 semantic의 차이를 활용하지만, 이는 메모리 오버헤드를 상당히 증가시키는 반면 latency 단축 효과는 제한적이었습니다. 이와 대조적으로, 본 논문에서는 이미지의 의미적 정보와 프레임 간의 시간적 상관관계를 활용하여, 베이스라인 모델 대비 성능 저하가 거의 없거나 전혀 없이 FLOPs와 지연 시간을 획기적으로 줄이는 video frame region masking 전략을 제안합니다. 구체적으로, 이전 프레임에서 추출한 특징(feature)을 활용함으로써 ViT 백본이 영역 마스킹의 이점을 활용하여, 입력 영역의 최대 80%를 생략하고 FLOPs를 3.14배, 지연 시간을 1.5배 개선할 수 있었습니다.
Introduction.
CV 모델을 통해 해결해야하는 문제들이 점점 많아지며, ViT는 이러한 작업에 매우 효과적입니다. 하지만 높은 연산량은 자원이 제한적이고 latency에 민감한 애플리케이션, 특히 높은 FPS로 샘플링된 고해상도 이미지를 처리해야 하는 경우 심각한 문제를 야기할 수 있습니다. 특히 센서에서 CV 백엔드로 이미지 프레임을 전송할 때 발생하는 에너지 소비와 대역폭 요구량에 대한 우려가 있습니다.
ViT의 연산 비용을 줄이기 위해 단순화된 어텐션 계산, latency 효율적인 아키텍처 설계, 입력 pruning 등 다양한 노력이 이뤄지고 있으며, 비디오 프레임의 시간적 중복성은 이와는 별도의 방향성을 제시하며, 훨씬 큰 폭의 연산 감소 잠재력을 보여줍니다. 특히 비디오의 상당 부분은 연속된 프레임 간에 변화가 거의 없기 때문에, 프레임을 개별적으로 처리할 경우 중복 연산이 발생합니다. 비디오의 시간적 중복성을 활용하는 기존 연구들은 주로 delta 기반 접근 방식을 사용하는데, 이는 이전 프레임과의 차이가 특정 delta 임계값을 초과할 때만 픽셀이나 영역을 처리하는 방식입니다. 이러한 접근법은 고정된 카메라에는 효과적이지만, 움직이는 카메라로 입력을 캡처할 때는 프레임 정렬(alignment)을 위한 노력이 필요하며, delta를 계산하기 위해 여러 중간 feature map을 저장해야 하므로 메모리 사용량이 크게 증가합니다. 즉, 중간 계층에서 영역 선택을 위한 추가 연산의 오버헤드로 인해 ViT에서는 latency를 효과적으로 줄이지 못하는 경우가 많습니다.
따라서 고정 및 이동 카메라 모두에서 잘 작동하며, 재학습 없이 추론 단계에 원할하게 통합될 수 있는 프레임 기반 비디오 객체 탐지 방법은 MaskVD를 제안합니다. 이는 region masking을 통해 이전 프레임에서 추출된 특징을 효율적으로 재사용하도록 탐지 백본을 조정합니다. 이는 아래의 그림 1. 에서 볼 수 있듯이 기존 방법과 유사한 성능을 유지하면서 지연 시간과 FLOPs를 크게 줄여줍니다:

해당 논문을 통해 기여하는 점은 다음과 같습니다:
- 이미지의 semantic information과 프레임간의 시간적 상관관계를 고려하여, 중요한 영역만 처리함으로써 탐지 성능을 향상시키는 동시에 연산 비용을 절감하는 region masking 전략을 제안합니다. 이 마스킹 전략은 CNN과 ViT 모두에 동일하게 적용할 수 있으며, 입력 마스크에 기반한 패치 선택은 중간 계층에서 재선택이 필요하지만, 해당 방법은 탐지 파이프라인의 입력 단계에서만 수행됩니다. 또한, 현재 프레임을 처리하기 전에 마스크를 결정할 수 있으므로, 마스킹된 영역에 대한 픽셀 판독 및 데이터 전송 에너지를 절약할 수 있습니다.
- 해당 탐지 파이프라인에서는 트랜스포머 백본을 위해 이전 프레임에서 추출된 특징을 활용하며, 윈도우 트랜스포머 블록에 대해 단일 텐서만을 저장함으로써 성능 저하 없이 기존 방법 대비 메모리를 획기적으로 줄였습니다(중간 feature map이 없으며, 이전 프레임에 대한 feature를 재사용함으로써 메모리 효율적으로 동작함).
Related Work.
(... DeltaCNN과 STGT, Eventful-Transformer, STTS 등 효율적인 추론을 위한 논문들 소개 ...)
Approach.
Preliminaries.
ViT 모델은 입력 이미지를 토큰이라 불리는 N개의 겹치지 않는 패치로 분할하고, 각 토큰을 길이 L의 임베딩 벡터로 임베딩합니다. 학습 가능한 위치 임베딩(positional embedding)이 각 토큰 임베딩에 더해진 후, 일련의 transformer encoder blocks들을 통과합니다. 각 blocks들은 Multi-head attention layer와 그 뒤를 잇는 FFN으로 구성됩니다. 토큰들은 각각 [N+1, d] 차원을 갖는 Q, K, V 행렬로 매칭이되며, d = L/H이며, H는 MSA의 헤드 개수입니다. 각 헤드는 아래의 식과 같은 self-attention 계산을 수행합니다. FFN은 일반적으로 GELU 활성화 함수를 갖는 2계층 네트워크 입니다:

ViTDet은 plain transformer backbone을 통해 탐지 작업에서 SOTA 성능을 입증했으며, ViTDet의 backbone은 Window Multi-Head Attention(W-MSA)으로 구성되는데, 이는 토큰들을 겹치지 않는 윈도우로 분할한 후, 위 식으로 주어지는 self-attention을 로컬 윈도우 안으로 제한하여 연산 비용을 낮춥니다. W-MSA blocks들 사이에는 윈도우 간의 정보 전파를 돕기 위해 몇 개의 global multi-head self-attention blocks이 교차 배치됩니다.
Constructing Input Mask.
static mask의 목적은 데이터셋 내에서 객체가 더 빈번하게 등장하는 영역을 식별하는 것입니다. 탐지 작업의 경우, 이 정보는 학습 데이터셋의 GT Bbox에서 쉽게 얻을 수 있습니다. 아래의 알고리즘 1. 을 이용하여 객체들의 누적 heatmap을 얻는 데 이 정보를 사용합니다:

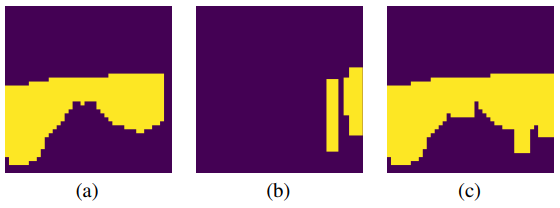
아래의 그림은 예시입니다:

그림 2(a).에 나타난 KITTI 학습 세트의 누적 heatmap에서 알 수 있듯이, 자율 주행 작업에서 객체는 주로 도로를 따라 나타납니다. 또한 하늘과 같이 절대 객체가 나타나지 않는 영역도 존재합니다. H의 픽셀별 값들은 누적되어 영역별 점수 2(b).를 얻을 수 있습니다. 영역 크기는 ViTDet 모델 백본의 패치 크기에 맞춰 16x16 픽셀로 선택되며, 마스크의 정적 유지 비율(k_s)에 기초하여, 영역 점수가 높은 상위 k개의 패치가 추가 처리를 위해 선택됩니다.
static mask가 객체가 자주 나타나는 영역에 대한 일반적인 개념을 제공한다면, 비디오 작업에서 객체는 이전 프레임에서 나타났던 영역에 다시 나타날 확률이 거의 확실히 높습니다. 따라서 우리는 현재 프레임에 대한 dynamic mask를 구성하기 위해 이전 프레임에서 탐지된 객체의 Bbox를 사용합니다. 프레임 간에 객체가 약간 이동하더라도, 실험에서 입증된 바와 같이 이러한 위치 변화는 16 픽셀 영역 크기로 충분히 커버할 수 있습니다.
그 후, combined input mask를 얻기 위해 static mask와 dynamic mask에 의해 선택된 영역들의 합집합을 취합니다. 이 마스크는 완전히 처리되는 프레임(오류 누적을 막기 위해 마스크 없이 처리되는 프레임)을 제외한 모든 프레임에 대해 탐지 모델의 입력으로 적용됩니다. 새로운 객체를 고려하고 탐지된 Bbox 로부터 마스크의 오류가 누적되는 것을 방지하기 위해, 주기적으로 전체 프레임을 마스킹 없이 처리합니다. 예를 들어, 주기 P에 대해 매 P 프레임 윈도우의 첫 번째 프레임은 마스크 없이 처리되고, 그 뒤의 (P-1)개의 프레임을 마스킹 됩니다. 프레임 t에 대한 마스크는 프레임 (t-1)의 정보로부터 추정됩니다. 아래의 그림은 combined input mask의 예시입니다:
Masked Processing in Detection Backbone.

Transformer backbone 입력 마스크는 마스킹된 프레임에서 토큰이 재계산되어야 할 우치를 결정합니다. 위 그림 4. 와 같이, 입력 마스크를 기반으로 토큰들이 수집(gather)되어 토큰 위치 정보와 함께 encoder block으로 전달됩니다. 마지막으로 처리된 프레임의 출력은 참조 출력(reference output)으로 저장됩니다. 각 프레임에 대해 처리된 토큰들은 이 참조 출력의 해당 위치로 분산(scatter)됩니다. 본질적으로, 처리된 토큰과 연관된 위치에 대해서는 새로운 값이 업데이트되고, 나머지 위치에 대해서는 참조 값이 유지됩니다. 전체 프레임 이 처리될 때(매 P 프레임마다) 모든 위치가 새로 고침됩니다. 토큰이 중요도에 따라 재배열되는 분류(classification) 작업과 달리, 탐지 작업에서는 토큰의 위치를 보존하는 것이 중요하다는 점에 유의해야 합니다.
global attention block을 사용할 때는 백본의 모든 연산이 입력에서 제거된(dropped) 토큰과 함께 원활하게 수행될 수 있습니다. 하지만 window attention block은 토큰이 dropped 된 상태에서 윈도우 분할 시 차원 불일치 문제에 직면합니다(global attention은 입력 이미지를 2D 격자가 아니라, 긴 1열 sequence로 취급하기 때문에, 토큰의 개수에 대한 제약이 없습니다. 하지만 window attention은 입력 이미지를 2D 격차인 window로 잘라서 attention을 취해야하기 때문에, 만약 어떤 window에는 token의 개수가 5개이고, 어떤 window는 256개이면 attention이 불가능합니다).

이를 해결하기 위해, 그림 5. 와 같이 window block의 입력단에서 토큰들을 원래 차원으로 scatter 합니다. 또한, 각 window attention block의 입력단에 마지막으로 처리된 프레임의 참조 텐서를 유지하고, block 입력단의 토큰들은 이 참조 텐서 위에서 업데이트됩니다. attention value 계산 후, 토큰들은 입력 마스크로부터 얻은 토큰 위치에 따라 다시 gather 됩니다. 즉, scatter에서는 global block을 지나온 듬성듬성한 토큰들을 가져온 후, 이걸 이전 프레임의 결과물(reference tensor)이라는 바탕화면 위에 제 자리를 찾아 끼워 넣습니다. 이렇게 되면 구멍 난 곳 없이 꽉 찬 이미지가 됩니다. 그 후, 계산이 끝나면 아까 관리하기로 했던 중요한 토큰 위치의 값만 뽑아내어 다시 듬성듬성한 리스트의 형태로 돌아가서 다음 연산을 준비합니다.
그 후 저자들은 window attention을 더 빠르게 만들기 위해, masking 돼서 안 쓸 window의 Q, K, V를 아예 빼버리고, 남은 window들만 계산하는 것을 고려했습니다. 즉, 100개의 윈도우 중 20개만 남기고 80개를 버리면, 계산량이 1/5로 줄어드니까 속도도 5배 빨라질 것이라 생각했습니다. 하지만 그냥 100개 다 계산하는 것보다 20개만 뽑아서 계산하는 것이 더 느렸습니다. 이는 GPU 하드웨어의 특성 때문이었습니다. 데이터를 메모리 이곳저곳에서 찾아서 모으로(gather), 다시 흩뿌리는(scatter) 작업은 GPU 입장에서는 매우 번거로운 작업입니다. 하지만, 거대한 직사각형 행렬을 한 번에 곱하는 연산에는 최적화가 잘 되어있기 때문에, 저자들은 window를 솎아내지 않고, 마스킹되어서 비어있는 윈도우 자리에 이전 프레임의 결과(reference tensor)를 복사해서 채워 넣습니다.
한편, non-window 방식이 latency의 측면에서 좋은 방법이 됩니다. non-window(global attention) 방식은 차원 불일치 문제가 없기 때문에, masking을 통해 token의 개수가 줄어들어도 상관 없이 계산을 진행할 수 있습니다. 하지만, masking된 token을 아예 빼버리고 계산을 진행하기 때문에, 과거의 reference tensor를 사용하는(차원 불일치 문제를 해결하기 위해 어쩔 수 없이 사용하는 것이긴 하지만) window 방식에 비해 성능이 낮습니다. 즉, 원래 global attention이 계산량이 많아서 느리지만, masking을 적용할 시, global attention은 token을 진짜로 버리고 계산하니까 오히려 빨라지는 것입니다. 하지만, 과거 값을 사용하긴 하는 window 방식과 달리, masking된 값을 아예 사용하지 않기 때문에 성능은 낮아지는 것입니다.

표 1.과 같이, 최고의 성능을 원한다면 windowed 방식을, latency의 측면에서 좋은 성능을 원한다면 non-windowed 방식을 사용하는 것이 좋습니다.
16x16 픽셀 영역을 마스킹하는 영역 마스킹 접근 방식은 CNN 기반 탐지 backbone으로 확장되어도 정확도를 향상시킬 수 있습니다. 입력 또는 활성화 희소성이 GPU 상의 CNN에 대해 속도 향상을 제공하지 않으므로, DeltaCNN에서 pixel 단위 희소성을 활용하기 위해 고안된 특화된 커널을 사용하여, 영역 마스킹은 마스킹된 부분에서 프레임 간의 delta 값을 0으로 만들어 연산을 크게 줄이고 속도 향상을 제공합니다. CNN 모델은 개선된 mAP-50을 달성하기 위해 마스킹된 입력으로 fine-tuning이 필요하다는 점에 유의해야 합니다.
Experimental Results.
위의 표 1.은 프레임이 완전히 처리되는 주기(P)와 static mask의 유지 비율(k_s을 변화시키며 패치 유지 비율, 즉 처리되는 패치의 비율을 설정합니다. (... 다 좋다는 얘기 ...)

표 2. 에서는 유사한 패치 유지 비율에 대해 static mask만 사용한 경우, dynamic mask만 사용한 경우, 그리고 combined mask를 사용한 결과를 비교합니다. static mask만을 사용하면 mAP가 크게 떨어지며, dynamic mask만을 사용하면 ImageNet-VID에서는 잘 동작하지만, KITTI에서는 mAP가 떨어지는데 이는 아마도 더 높은 프레임 간 움직임 때문일 수 있습니다. combined mask는 가장 효과적인 패치 선택 방법을 제공합니다.

그림 6. 은 비디오 추론 가속화를 위해 프레임 간의 시간 중복성을 활용하는 데 중점을 둔 SOTA 방법들, 즉 Eventful-Transformer 및 STGT와 논문의 모델을 비교한 표입니다. (... 좋다는 얘기 ...)

그림 7. 은 token-dropping 방법과 비교한 내용으로, EViT에서 사용된 attention 기반 토큰 제거 방식은 해당 논문에서 제안한 마스킹 방법과는 독립적이며, 마스킹 방법과 결합하여 더 나은 성능을 달성할 수 있다는 점도 유의미합니다.
Note: token-pruning은 token의 latent feature를 분석한 후 pruning(routing)을 수행하는 것이기 때문에, 비교적 rule-base인 masking 방법보다는 upper bound가 높아보이는데, 우선 video같은 경우 중복되는 부분이 너무 많다는 것은 자명하기 때문에, 그렇게 latent한 정보를 사용하는 것이 효율적이지는 않나보다,,,