
https://arxiv.org/abs/1612.03144
Feature Pyramid Networks for Object Detection
Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive. In this paper, w
arxiv.org
Abstract.
feature pyramid는 서로 다른 scale의 객체를 탐지하기 위한 기본적인 구성 요소입니다. 그러나 최근(2016년)의 딥러닝 object detector들은 pyramid 표현 방식이 연산량과 메모리를 많이 소모한다는 이유로 이를 기피해 왔습니다. 본 논문에서는 cNN이 본질적으로 가지고 있는 multi-scale, pyramid 계층 구조를 활용하여, 아주 조그만 추가 비용만으로 feature pyramid를 구축하는 방법을 제안합니다.
모든 scale에서 고수준의 semantic 정보를 담은 feature map을 구축하기 위해, lateral connections(측면 연결)을 갖춘 top-down 아키텍처를 개발했습니다. FPN(Feature Pyramid Network)이라 불리는 이 아키텍처는 여러 application에서 범용 feature extractor로서 상당한 성능 향상을 보여줍니다. 기본적인 Faster R-CNN 시스템에 FPN을 적용했을 때, 별다른 부가적인 기법 없이도 COCO detection benchmark에서 SOTA(2016년)를 달성했습니다.
Introduction.
매우 다양한 scale의 객체를 인식하는 것은 컴퓨터 비전의 근본적인 과제입니다. image pyramid 위에 구축된 feature pyramid(featurized image pyramid, 아래 그림 1.(a))는 이 문제에 대한 표준적인 해결책입니다:
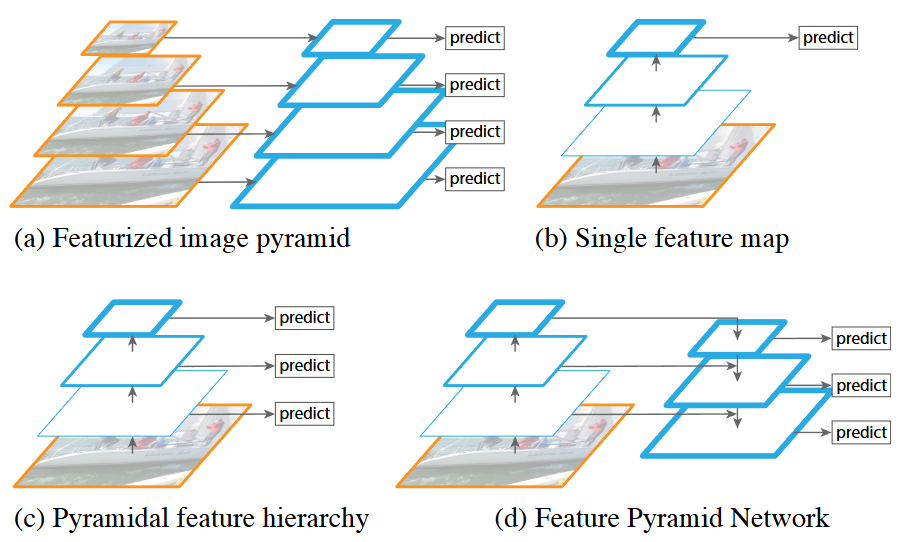
이러한 pyramid는 scale-invariant를 갖습니다. 즉, 객체의 크기 변화는 pyramid 내에서 그 level을 이동하는 것으로 상쇄될 수 있습니다. 직관적으로 이 속성은 모델이 위치(한 장의 이미지의 feature에 대해서)와 pyramid level(다양한 scale에 대해서)을 모두 스캔함으로써 넓은 범위의 크기에 걸쳐 객체를 탐지할 수 있습니다.
featurized image pyramid(위 그림 1.(a))는 수작업 feature들을 사용할 때 사용되었으며, 이들은 대체로 CNN에 의해 계산되는 feature들로 대체되었습니다. CNN은 더 고차원의 semantics들을 표현할 수 있을 뿐만 아니라, scale 변화에 대해서도 더 robust합니다. 따라서 단일 입력 스케일에서 계산된 feature만으로도 인식이 용이해졌습니다(즉, CNN을 사용함으로써 scale-invariant한 성질이 어느 정도 생겨서 pyramid는 사용하지 않게 되었다).
하지만 이러한 robust에서 불구하고, 가장 정확한 결과를 얻기 위해서는 여전히 pyramid가 필요합니다. ImageNet이나 COCO detection chanllenge의 SOTA모델들은 featurized image pyramid 위에서 동작합니다(2016년). image pyramid의 각 level을 featurizatioon하는 것의 주요 장점은 고해상도 레벨을 포함한 모든 level이 의미적으로 강력한 multi-scale feature를 생성한다는 것입니다.
그럼에도 불구하고, image pyramid의 각 level을 featurization하는 것은 명백한 한계가 있습니다. 이는 inference time입니다. 추론 시간이 상당히 증가하여, 이 방식은 실제 applicatioon에 적용하기 어렵습니다. 게다가 image pyramid에 대해 심층 신경망을 end-to-end로 학습시키는 것은 메모리 측면에서 불가능에 가깝습니다(2016년). 따라서 image pyramid는 활용되더라도 test time에만 사용되는데, 이는 학습과 테스트 시 추론 간의 불일치를 초래하며, Fast 및 Faster R-CNN은 기본 설정에서는 featurized image pyramid를 사용하지 않습니다.
그러나 image pyramid만이 multi-scale feature를 계산하는 유일한 방법은 아닙니다. CNN은 layer별로 feature hierarchy를 계산하며, subsampling layer 덕분에 이 feature hierarchy는 내재적인 multi-scale pyramid 형태를 갖습니다. 이 network 내부의 feature hierarchy는 서로 다른 공간 해상도의 feature map을 생성하지만, 서로 다른 depth로 인한 큰 의미론적 격차를 발생시킵니다.
Note: 이는 CNN layer의 초반 부분은 low-level feature를 가지며, 후반으로 갈 수록 high-level feature를 가진다는 것을 의미합니다. 또한 CNN layer의 초반 부분은 고해상도(작은 물체)에 대한 feature를, 후반 부분은 저해상도(큰 물체)에 대한 feature를 가진다는 것을 의미합니다. 즉 CNN layer를 쌓으면 그거 자체가 pyramid라는 것입니다.
SSD(Single Shot Detector)는 CNN의 feature pyramid를 마치 featurized image pyramid(그림 1.(a))인 것처럼 사용하려 했던 시도 중 하나입니다(그림 1.(c)). 이상적으로 SSD 스타일의 pyramid는 forward pass에서 계산된 서로 다른 layer의 multi-scale feautre map을 재사용하므로 비용이 들지 않습니다. 하지만 SSD는 low-level feature를 사용하는 것을 피하기 위해, 초기 layer의 재사용이 아닌 네트워크의 높은 곳(예: VGG Net의 conv4_3)에서부터 시작하여 새로운 layer를 추가하는 방식으로 pyramid를 구축합니다. 따라서 SSD는 feature hierarchy의 고해상도 맵을 재사용할 기회를 놓치는 것입니다. 한편, 논문의 저자들은 이러한 고해상도 맵이 작은 객체를 탐지하는 데 중요하다고 생각했습니다.
Note: 고해상도 feature map을 통해 작은 객체를 탐지하기 위해서 low-level feature를 바로 detection에 사용하기엔 low-level feature는 CNN layer를 얼마 통과하지 못한 feature이기 때문에 의미론적으로 강하지 못합니다. 즉, suboptimal한 성능이 나올 수 있습니다. 따라서 SSD는 네트워크의 높은 곳, 즉 충분히 semantic이 존재하는 feature로부터 detection을 시작하는 것입니다
본 논문의 목표는 CNN feature hierarchy의 pyramid 형태를 자연스럽게 활용하면서, 동시에 모든 scale에서 강력한 semantic을 갖는 feature pyramid를 생성하는 것입니다. 이 목표를 달성하기 위해, top-down pathway와 lateral connection을 통해 저해상도의 의미론적 강력한 feature들을 고해상도의 의미론적으로 약한 feature와 결합하는 아키텍처를 사용합니다(그림 1.(d), 위 Note에서 말한 내용과 비슷한 이유로 인해 low-level feature를 사용할 수 없으니, high-level feature를 결합하여 고해상도에서도 충분히 의미론적으로 충분한 feature를 만들어주는 것입니다). 그 결과물은 모든 level에서 풍부한 의미 정보를 가지며, 단일 입력 이미지 scale로부터 빠르게 구축될 수 있습니다. 다시 말해, 표현 능력, 속도, 메모리를 희생하지 않고 featurized image pyramid를 대체할 수 있는 network 내부 feature pyramid를 생성하는 것입니다.

하향식 연결과 skip connectioon을 채택한 유사한 아키텍처들이 최근(2016년) 연구에서 인기를 끌고 있으며, 이들의 목표는 예측이 이루어질 하나의 고해상도, 고수준 feature map을 생성하는 것입니다(그림 2. 상단). 이와 대조적으로, 해당 논문의 방법은 아키텍처를 feature pyramid로 활용하여, 예측이 각 level에서 독립적으로 이루어지도록 합니다(그림 2. 하단). 이를 FPN이라 부르며 다양한 benchmark로 성능을 평가합니다(당시 SOTA).
Related Work.
(...)
Feature Pyramid Networks
낮은 level에서 높은 level까지의 의미(semantic)를 가진 CNN의 pyramid형 feature hierarchy를 활용하여, 전체적으로 높은 수준의 의미(high-level semantics)를 가진 feature pyramid를 구축하는 것이 목표입니다. 결과물인 feature pyramid network는 범용적인 목적(feature extractor)를 가지며, 본 논문에서는 RPN과 Fast R-CNN에 초점을 맞춥니다.
임의의 크기를 가진 단일 scale 이미지를 입력으로 받아, convolution 방식으로 여러 level에서 비례적인 크기의 feature map을 출력합니다. 이 과정은 backbone CNN architecture와 독립적이며, 본 논문에서는 ResNet을 사용한 결과를 제시합니다. pyramid의 구축은 bottom-up pathway, top-down pathway, 그리고 lateral connection을 포함합니다:
- Bottom-up pathway: 상향식 경로는 backbone CNN의 feedforward 계산 과정입니다. 이 과정은 2의 scaling step(2배씩 이미지가 줄어드는)을 가지는 여러 scale의 feature map으로 구성된 feature hierarchy를 계산합니다. 한편, 동일한 크기의 출력 맵을 생성하는 layer들이 여러 개 존재하는데, 이러한 layer들을 동일한 network stage에 있다고 말합니다. 각 stage마다 하나의 pyramid level을 정의하며, 각 stage의 마지막 layer의 출력을 pyramid를 생성하기 위한 feature map의 reference로 선택합니다.
- Top-down pathway: 하향식 경로는 상위 pyramid level에서 공간적으로는 더 거칠지만(coarser) 의미론적으로는 더 강력한 feature map을 upsampling하여 고해상도 특징을 생성합니다. 이러한 feature들은 lateral connection을 통해 bottom-up pathway의 feature들과 결합되어 강화됩니다.
- Lateral connection: 각 lateral connection(측면 연결)은 상향식 경로와 하향식 경로에서 온 동일한 spatial size의 feature map들을 병합합니다. 상향식 feature map은 의미론적 수준은 낮지만, subsampling된 횟수가 적기 때문에 위치 정보(localization)가 더 정확하게 보존되어 있습니다.

위 그림 3. 은 top-down pathway를 구성하는 building block을 보여줍니다. 거친 해상도(높은 semantic 정보)의 feature map이 있을 때, 공간 해상도를 2배로 upsampling합니다(단순함을 위하 NN(nearest neighbor) upsampling을 사용합니다). 그 후 upsampling된 map은 해당하는 bottom-up map과 element-wise addition을 통해 병합됩니다.
마지막 feature map인 C_5에 1x1 conv layer를 붙여 가장 거친 해상도의 map을 생성하며, 병합된 각 map에 3x3 conv layer를 추가하여 최종 feature map을 생성하는데, 이는 upsampling으로 인한 aliasing effect를 줄이기 위함입니다(upsampling을 NN으로 하면, jagging이 발생하기 때문에, 그대로 사용할 수는 없고, 3x3 conv를 한 번 더 통과시킴으로써 이를 완화하는 것입니다. 아래 글 中 NN interpolation):
[Digital Image Processing] 09. Geometric Processing
해당 글은 건국대학교 김은이 교수님의 디지털 영상 처리 수업 내용을 정리한 글입니다. Geometric Operations 일반적인 영상 처리는 I(x,y)에서 I'(x,y)로 픽셀 값만 변하지만, 기하학적 처리는 I(x,y)에서
hw-hk.tistory.com
이 최종 feature map set를 {P_2, P_3, P_4, P_5}라고 부르며, 이는 각각 동일한 공간 크기를 갖는 {C_2, C_3, C_4, C_5}에 대응됩니다. pyramid의 모든 level이 전통적인 featurized image pyramid처럼 shared classifiers/regressors를 사용하기 때문에, 모든 feature map의 feature dimension을 d로 고정합니다. 한편, 추가 layer들에는 비선형성(예: ReLU)가 없는데, 이는 경험적으로 결과에 미미한 영향을 주는 것으로 밝혀졌습니다. 이 연구의 핵심은 simplicity이며, 없어도 robust한 설계가 가능하기 때문에, 비선형성을 추가하지 않았습니다.
Application and Experiments on Object Detection.
(...RPN과 Object detection에 적용했을 때, 좋은 성능...)