
https://arxiv.org/abs/2404.02258
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific positions in a sequence, optimising the allocation along
arxiv.org
Abstract.
Transformer 기반 언어 모델은 입력 시퀀스 전체에 걸쳐 FLOPs를 균일하게 분산시킵니다. 해당 연구에서는 transformer가 시퀀스 내 특정 위치에 FLOPs를 동적으로 할당하도록 학습할 수 있음을 보여주며, 모델 깊이에 걸쳐 서로 다른 레이어에 대해 시퀀스를 따라 최적화합니다. 즉, 전체 시퀀스에 대해서 동일한 양의 FLOPs를 부여하는 것이 아닌, 특정 token에 대해(시퀀스 내의 token들 각각에 대해) 동적으로 FLOPs를 할당할 수 있다는 것입니다.
논문에서 제안한 방법은 특정 레이어에서 self-attention 및 MLP 연산에 참여할 수 있는 token의 수(k)를 제한함으로써 총 compute budget을 강제합니다. 처리될 token은 네트워크가 top-k routing mechanism을 사용하여 결정하며, k가 사전에 정의되기 때문에, 이 절차는 다른 조건부 연산(router를 통해서 routing하는 연산) 기법들과 달리 텐서 크기가 알려진 static computation graph를 사용합니다(router를 사용하여 입력에 맞게 선택하는 token의 개수가 달라지면, 텐서의 크기가 동적으로 바뀌기 때문에 static computation graph를 사용할 수 없다).
그럼에도 불구하고 k개 token은 유동적으로 변하기 때문에(개수만 정해졌지, 정해진 token만을 선택하는 것이 아니기 때문에), 이 방법은 시간 및 모델 깊이 차원에 걸쳐 비균일하게 FLOPs를 소비할 수 있습니다. 따라서 compute budget은 예측 가능하지만, token 수준에서는 동적이며 문맥에 민감(context-sensitive)합니다. 이러한 방식으로 훈련된 모델은 연산을 동적으로 할당하는 법을 배울 뿐만 아니라, 이를 효율적으로 수행합니다. 이 모델들은 동등한 학습 FLOPs 및 실제 소요 시간에 대해 baseline 성능과 일치하지만, forward pass 당 필요한 FLOPs는 훨씬 적습니다.
Introduction.
모든 문제가 해결하는 데 같은 양의 시간이나 노력을 필요로 하지는 않습니다. 마찬가지로, 언어 모델링에서도 모든 토큰과 시퀀스가 정확한 예측을 위해 같은 시간이나 노력을 필요로 하지 않습니다. 그럼에도 불구하고, transformer model은 forward pass에서 token 당 동일한 양의 연산을 소비합니다. conditional computation은 필요할 때만 연산을 소비하여 총 연산량을 줄이는 기법입니다. 다양한 알고리즘들이 언제, 얼마나 많은 연산을 사용해야 하는지에 대한 해결책을 제공합니다. 하지만, 이 까다로운 문제에 대한 일반적인 해결책들은 dynamic computation graph를 사용하는 경향이 있어서 기존 하드웨어 제약 조건과 잘 맞지 않을 수 있습니다. 한편, static computation graph의 사용을 우선시하고, 하드웨어 활용률을 극대화하기 위해 텐서의 크기를 고정하는 conditional computation이 적절합니다.
Note: computation graph란 operation을 나타내는 node와 데이터의 흐름을 나타내는 edge로 이루어진 방향성 그래프를 나타냅니다. 딥러닝에서는 역전파의 자동화를 위해 계산들을 그래프로 나타냅니다. 또한 이렇게 그래프로 나타내는 것은 병렬화에 유리한데, 예를 들어 그래프를 만들고 보니 A 연산과 B 연산이 서로 의존하지 않는다면(연결선이 없으면), GPU의 서로 다른 코어에서 동시에 실행할 수 있습니다. 아니면 graph에서 곱하기 node 다음에 더하기 node가 바로 붙어 있다면, GPU는 이를 한 번의 연산(multiply-Add)으로 합쳐서 처리해 메모리 읽기/쓰기 시간을 줄일 수 있습니다(fusion).
Note: 이때 static computation graph와 dynamic computation graph는 연산의 경로와 데이터의 크기(shape)가 언제 결정되는지에 따라 달라집니다. 그리고 현대의 GPU나 TPU는 거대하고 규격화된 행렬을 한 번에 처리할 때 가장 효율적이기 때문에, 실행해보기 전까지 tensor의 크기를 정할 수 없는 dynamic computation graph는 연산 효율성이 떨어집니다.
여기서 해당 논문의 저자들은 일반적인(vanilla) transformer보다 더 적게, static computation budget만을 사용하여 언어 모델링 문제를 해결하고자 합니다. 네트워크 각 레이어에서 사용 가능한 예산 내에서 어디에 연산을 쓸지 token별로 결정함으로써, 가용 연산을 동적으로 할당하는 법을 학습합니다. 이때 총 연산량은 네트워크의 on-the-fly 결정에 따른 함수가 아니라, 훈련 전에 사용자에 의해 정의되고 변하지 않습니다. 따라서 메모리 사용량 감소나 forward pass 당 FLOPs 감소와 같은 하드웨어 효율성 이득을 미리 예측하고 활용할 수 있습니다.

네트워크 깊이에 걸쳐 동적인 token-wise routing이 이뤄지는 MoE transformer와 유사한 접근 방식을 사용합니다. MoE와 달리, token에 연산을 적용하거나, residual connection을 통해 통과시키는 것 중 하나를 선택합니다. 또한 MoE와 대조적으로, 이 routing을 forward MLP와 MSA(multi-head self-attention)에 모두 적용합니다. 이는 처리하는 key와 query에도 영향을 미치므로, routing은 어떤 token을 업데이트할지 뿐만 아니라 어떤 토큰을 attention에 사용할 수 있게 할지도 결정합니다. 이는 transformer의 깊이를 통과하면서 서로 다른 수의 레이어를 거친다는 점을 강조하기 위해 이 전략을 Mixture-of-Depth(MoD)라고 부릅니다(위 그림 1. 참조).
또한 MoD 기법은 성능과 속도 간의 trade-off를 가능하게 하며, 동등한 학습 FLOPs에 대해 일반 transformer보다 최대 1.5%까지 성능을 향상시킬 수 있습니다. 다른 한편, isoFLOP 최적 일반 transformer와 동등한 학습 손실을 달성하지만, forward pass당 훨씬 적은 FLOPs를 사용하여 step 속도가 더 빠른 MoD transformer를 훈련할 수 있습니다.
Background.
transformer 아키텍처는 매우 성공적이었으며, 해당 아키텍처를 효율적으로 만드는 방법이 다양하게 제안되었습니다. 그 중 하나는 conditional computation입니다. 이는 학습된 메커니즘이 언제, 어떻게 연산을 소비할지 결정하는 방식입니다. 이 중 일부는 early exit에 초점을 맞추며, 이는 주어진 token에 대한 연산을 언제 끝낼지 결정하는 것을 학습하며, 종료 결정이 내려진 후 남은 transformer 레이어들을 건너뛰게 하는 것입니다. MoD는 이와 달리, 토큰이 중간 레이어를 건너 뛸 수 있으며, 이후 모든 중간 레이어를 거친 토큰들과 셀프 어텐션을 통해 업데이트 될 수 있습니다.
Note: 이건 제 생각인데, 이는 기본적으로 attention layer들이 독립적이어야 가능할거 같습니다. 만약 어떤 transformer의 layer n과 layer n+1이 서로 의존적으로 묶여있어서, layer n을 통과하고 나온 feature들이 layer n+1로 들어가야 가장 효율적으로 추론할 수 있도록 fitting이 되어있다면, layer n을 건너뛰고, layer n+1로 들어가는 것은 효율적이지 못한 결과로 이어질 수 있습니다. 이를 해결하기 위해서는 애초에 이런 방식(어떤 layer는 skip하고, 어떤 layer는 추론하는 방식)으로 전체 모델을 학습해서 각 layer들이 독립적으로 동작하도록 해야 합니다. 즉, router만 학습하는 것은 좋은 결과로 이어지지 않을 것 같다는 생각이 듭니다.
(... 공유 가중치를 갖은 transformer layer를 적응형 step 수만큼 반복하는 방법, router를 학습하여 무거운 경로로 계산할 지, 가벼운 경로로 계산할지 선택하는 방법 등 ...)
conditional computation의 성공적인 형태 중 하나는 Shazeer et al., 2017이 도입한 MoE layer입니다. 이는 연산을 절약하거나 추가로 소비하려는 다른 conditional computation과 달리, conditional logic을 이용하여 총 compute budget을 일정하게 유지하면서 토큰을 여러 experts MLP 중 하나로 routing합니다.
Implementing Mixture-of-Depth Transformers.
구현에 있어서 전략은 다음과 같습니다:
- sequence 내에서 block의 연산에 참여할 수 있는 토큰의 수를 제한함으로써, 동등한 vanilla transformer보다 적은 static compute budget을 설정합니다. 예를 들어, 일반 transformer는 sequence의 모든 토큰이 self-attention에 참여하도록 허용하는 반면, 그 수를 스퀀스 내 토큰의 50%로 제한할 수 있습니다.
- 블록별 router를 사용하여 각 토큰에 대해 scalar 가중치를 생성합니다. 이는 해당 토큰이 블록의 연산에 참여하거나 혹은 우회하기를 바라는 router의 선호도를 나타냅니다.
- top-k의 scalar 가중치를 식별하여 블록의 연산에 참여할 토큰들을 선택합니다. 정확히 k개의 토큰만이 블록의 연산에 참여하므로, 연산 그래프와 텐서 크기는 훈련 내내 정적으로 유지됩니다. 단지 router에 의해 결정된 토큰들의 참여 여부만이 동적이고 문맥에 따라 달라질 뿐입니다.
Defining a compute budget.
forward pass 당 총 compute budget을 강제하기 위해 capacity라는 개념을 사용합니다. capacity는 주어진 연산에 대한 입력을 구성하는 토큰의 총 수를 정의합니다. 예를 들어, 각 vanilla transformer block의 self-attention과 MLP는 T(=sequence length)의 용량을 갖습니다. 반면, MoE transformer는 각 experts마다 T보다 적은 용량을 사용하여 총 연산을 각 전문가에게 더 균등하게 분배합니다. 하지만 MoE는 block당 여러 epxerts들을 사용하기 때문에, 그들의 총 capacity는 vanillla trasnformer와 거의 같습니다.
일반적으로 조건부 연산을 사용하는 transformer의 총 FLOPs를 결정하는 것은 routing 결정의 결과가 아니라 바로 token capacity입니다. 이는 static graph 구현이 최악의 경우를 고려하여 결정되기 때문입니다. 예를 들어, 실제로 해당 연산으로 routing되는 토큰이 비교적 적더라도 연산의 입력은 용량의 크기만큼 패딩되거나, 용량이 초과되면 토큰이 연산에서 제외될 수 있습니다.
따라서 연산의 용량을 낮춤으로써 vanilla transformer에 비해 forward pass 당 더 작은 연산 예산을 사용하려는 목표를 달성할 수 있습니다. 그러나 무계획적으로 더 작은 compute budget을 사용하면 성능 저하가 발생합니다. 따라서 논문의 저자는 특정 토큰들은 다른 토큰만큼 많은 처리가 필요하지 않을 수 있으며, 이러한 토큰들은 학습을 통해 식별될 수 있다고 가정합니다. 따라서 네트워크가 용량을 채울 올바른 토큰을 선택하는 법을 배운다면 성능을 유지할 수 있을 것입니다.
Routing around transformer blocks.
토큰을 다음 두 가지 계산 경로 중 하나로 routing하는 설정을 고려합니다:
1) self-attention 및 MLP
2) residual connection
후자는 계산적으로 저렴하며 입력값에 의해 완전히 결정되는 block 출력을 생성하며, 전자의 경로는 계산적으로 비쌉니다. 경로 (1)의 capacity를 T보다 작게 설정한다면, forward pass 당 총 FLOPs는 vanilla transformer보다 적을 것입니다. 예를 들어, block의 capacity를 T/2로 설정하면, self-attention 행렬 곱셈을 vanilla transformer에 비해 25% 수준의 비용으로 할 수 있습니다((T/2)^2 vs. T^2). MLP도 유사한 계산으로 FLOPs 절감량을 계산할 수 있습니다.
직관적으로, block의 capacity를 공격적으로 줄일수록 forward pass 당 총 FLOPs는 감소하거, 그에 비례합니다. 그러나 downstream 성능 또한 얼마나 공격적으로 block capacity를 줄이는지, 그리고 어떤 routing 알고리즘을 구현하는지에 영향을 받습니다. 이 두 극단 사이 어딘가에 vanilla transformer보다 빠르면서 성능은 그만큼 좋거나 더 나은, 그러면서도 step speed가 더 빠른 최적의 모델이 있을 것이라 가정합니다.
Routing schemes.
단순하게는, layer 또는 block dropout과 유사하게 확률(stochasticity)을 사용해 토큰을 routing할 수 있습니다. 이를 routing 방식의 대조군으로 제시하며, 이것이 vanilla transformer에 비해 성능이 상당히 떨어진다는 것을 보여줄 것입니다. 따라서 학습된 routing이 더 적절합니다. 직관적으로 네트워크는 어떤 토큰이 다른 토큰보다 더 많거나 적은 처리를 필요로 하는지 학습할 수 있어야 합니다. transformer가 예측을 수행하는 데 필요한 것보다 더 많은 연산을 소비한다는 가정이 맞다면, 각 block의 capacity를 얼마나 공격적으로 줄일 수 있는지, 따라서 각 block을 우회하는 토큰을 얼마나 많이 허용할 수 있는지는 경험적인 질문이 됩니다.

이때 두 가지 routing 방식을 고려합니다:
1) token-choice
2) expert-choice
token-choice routing에서는 router가 계산 경로 전반에 걸쳐 토큰 별 확률 분포를 생성합니다. 그런 다음 토큰들은 그들이 선호하는 경로로 보내지며, auxiliary loss을 통해 모든 토큰이 같은 경로로 수렴하지 않도록 합니다. 토큰 선택 routing은 토큰들이 가능한 경로들 사이에서 적절하게 나뉜다는 보장이 없기 때문에 load balancing 문제를 겪을 수 있습니다.
expert-choice routing은 이를 뒤집습니다. 토큰이 선호하는 경로를 선택하는 대신, 각 경로가 토큰들의 선호도에 기초하여 top-k개의 토큰을 선택합니다. 이는 k개의 토큰이 각 경로로 보내지는 것이 보장되므로 완벽한 load balancing을 보장합니다. 그러나 일부 토큰은 여러 경로에서 top-k에 들거나 어느 곳에도 들지 못할 수 있어, over-processing되거나 under-processing되는 결과를 낳을 수 있습니다.
저자들은 몇 가지 이유로 expert-choice routing을 선택하기로 결정합니다. 우선 (1) auxiliary load balancing loss를 없앱니다. 강제로 반반 나누지 않아도, 알아서 정확히 k개가 선택되기 때문입니다. token-choice routing 방식은 토큰이 경로를 선택하는 방식입니다. 만약 모든 토큰이 연산을 하고 싶다고 선택을 한다면, 연산 block은 과부하가 걸리며, 건너뛰기 경로는 텅 비게 됩니다. 이를 막기 위해, 학습 과정에서 한쪽으로 쏠리지 말라고 강제하는 loss를 추가해야 하는데, 이는 학습을 복잡하게 만들며 성능을 저하시킬 수 있습니다. 하지만 MoD 방식은 경로가 토큰을 선택하는 방식으로, 토큰들이 어떤 경로를 선택하든 상관없이, 무조건 정확히 k개의 토큰만 연산 블록으로 들어갑니다.
또한 top-k 연산이 router 가중치의 크기에 의존하기 때문에, 이 routing 방식은 상대적인 routing 가중치가 어떤 토큰이 블록의 연산을 가장 필요로 하는지 결정하는 데 도움을 줄 수 있습니다. 즉, 토큰끼리 경쟁을 시켜서, 진짜 중요한 토큰을 선택하게 하기 위함입니다. token-choice routing에서는 각 토큰은 자기 자신 내부에서만 고민합니다. 예를 들어, 중요하지 않는 토큰 A가 연산하고 싶은 생각이 51%여서 연산을 수행하며, 중요한 토큰 B가 연산하고 싶은 마음이 49%여서 연산을 안 할 수도 있습니다. 한편, MoD 방식은 라우터가 부여한 가중치가 높은 순서대로 top-k를 선택합니다. 이렇게 하면 가장 중요한 토큰들이 확실하게 연산 블록에 포함됩니다.
마지막으로, 오직 두 개의 경로만으로 routing하기 대문에, 단일 top-k 연산 만으로 토큰들을 두 개의 상호 배타적인 집합으로 효율적으로 나눌 수 있어, 위에서 언급한 over-processing 또는 under-processing을 방지할 수 있습니다. 즉, 일반적인 MoE 방식에서 expert-choice routing을 사용하면, experts들이 각자 top-k를 뽑다보니 어떤 토큰은 모든 experts들에 선택되어 over-processing되며, 어떤 토큰은 아무에게도 선택 받지 못해 under-processing될 수 있습니다. 하지만 MoD 상황은 다릅니다. 경로가 단 두 개뿐이기 때문에, 토큰들을 임의의 경로에 대해 중복 선택되거나 아무 데도 못 가는 토큰 없이 깔끔하게 나눌 수 있습니다.
Routing implementation.
각 토큰은 router에 의해 처리되어 scalar 가중치를 생성하고, top-k개의 가중치가 transformer block을 통과할 토큰을 선택하는데 사용됩니다. 주어진 레이어 l에 대해 길이 S인 sequence의 토큰 임베딩 집합이 있다고 가정하면, X^l = {x^l_i | i is an integer, 1 ≤ i ≤ S} 입니다. 주어진 토큰 임베딩에 대한 router 가중치는 linear projection의 결과로 생성된 scalar값입니다.
이때 목표는 이 라우터 가중치들을 사용하여 각 토큰에 대한 블록 연산의 출력을 결정하는 것입니다. P_β(R^l)를 라우터 가중치 집합 R^l의 β-백분위수라고 가정합니다. 여기서 β = 1 - C/S이며, C는 배치 요소당 사용자 정의 capacity(주어진 함수에 의해 처리될 시퀀스 내 토큰의 수를 정의하는 S보다 작은 정수)입니다. 주어진 토큰에 대한 블록의 출력은 다음과 같습니다:

여기서 \tilde{X}^l은 라우터 값 r^l_i > P_ β(R^l)인 토큰들의 집합(즉, top-k 토큰들)이며, f는 셀프 어텐션과 후속 MLP를 포함합니다. 이때 주어진 토큰 x^{l+1}_i의 출력은 셀프 어텐션 연산 때문에 다른 토큰들 x^l_{i ≠ j}에 의존합니다. \tilde{X}^l의 원소 개수(cardinality)는 C (또는 k), 즉 사용자 정의 capacity입니다. 따라서 MoD 트랜스포머는 블록 연산 f에 대한 입력이 평소보다 적은 토큰(C < S)으로 구성되어 셀프 어텐션과 MLP 비용을 줄여주므로, 베이스라인 대비 연산 절감 효과를 얻습니다.
이때, 함수 f의 출력에 router 가중치를 곱합니다. 이는 router 가중치를 gradient 경로 상에 배치하여, 언어 모델링 작업 과정에서 gradient descent의 힘을 받도록 합니다. 이는 top-k selection이 gradient가 흐르지 않는 연산이기 때문입니다. 따라서 router 의 가중치를 출력에 곱함으로써 수학적으로 미분이 가능하도록 하는 것입니다. 한편, block 연산을 우회하는 토큰들에 대해서도 router 가중치를 계산 경로에 포함시키는 버전을 실험했을 때는 좋은 성능을 기록하지 못했으며, block 연산에 대해서만 하는것이 구현적으로 간단하며, 충분하다고 합니다.
Sampling.
expert-choice routing은 많은 장점이 있지만, 하나의 뚜렷한 문제가 존재합니다. 바로 top-k 연산이 non-causal이라는 점입니다. 즉, 어떤 토큰의 routing 가중치가 sequence 내에서 top-k개에 속하는지 여부는 그 토큰 뒤에 오는 토큰들의 routing 가중치 값에 따라 달라지는데, 이는 (decoder에서) autoregressively하게 생성(sampling)할 때는 이 미래 정보에 접근할 수 없습니다. 이 문제를 해결하기 위해 다음과 같은 방법을 테스트 합니다:
- 간단한 auxiliary loss를 도입합니다. 원래 router는 점수(0-1)을 냅니다. 학습 중에 전체 문장을 보고 top-k에 든 토큰과 못 든 토큰을 구분한 후 BCE loss를 통해 router를 학습합니다. 예를 들어, top-k에 든 token이면 target = 1로 하는 BCE loss값을, top-k안에 안 든 token이면 target = 0으로 하는 BCE loss값을 이용해 학습하는 것입니다. 그렇게 되면 router의 출력은 양극화가 되며, 생성(sampling)을 할 때는, 남들과 비교할 필요 없이 내 점수가 0.5(threshold)를 넘느냐만 확인하면 됩니다. 하지만 router에 언어 모델링에 가장 도움이 되는 점수를 주는 것 뿐만 아니라, 0.5 기준 맞추기라는 task가 하나 더 부여되어, 원래 성능이 아주 약간(0.2~0.3%) 떨어질 수 있습니다.
- 아니면 보조 MLP를 이용합니다. main router는 언어 모델링에 최적화된 점수를 계속 계산하며, 보조 예측기(작은 MLP)는 main router와 똑같은 입력을 받으며, 지금 들어온 토큰이 top-k안에 들어올지 안 들어올지를 예측하도록 별도로 학습됩니다. 이때 보조 예측기에 대한 gradient를 main router나 backbone에 전가하지 않습니다(stop gradient). 생성(sampling)할 때, main router의 점수는 무시하고, 보조 예측기에게 top-k에 들어갈지 물어본 후, routing을 수행합니다. main router는 생성(sampling) 시 출력에 가중치를 곱하는 역할만 수행합니다.
특히, 두 번째 방법은 아주 작은 연산량의 추가로 빠르게 99%의 정확도에 도달할 수 있습니다.
Results.

그림 3. 은 전체적인 실험 결과를 보여줍니다. 우선 최적의 MoD transformer는 최적의 baseline보다 더 낮은 loss를 달성하며, 더 많은 파라미터를 가질 수 있습니다. 또한 확률적(stochastic) routing을 사용하는 MoD transformer는 baseline 및 일반 MoD transformer보다 훨씬 성능이 낮은것으로 보아, 학습된 routing은 필수적입니다.
실험에서는 전체 시퀀스의 12.5%에서 95%까지의 capacity를 사용하여, 하나 건너 하나씩 routing하는 것이 가장 좋은 성능을 기록했으며, 전체 시퀀스의 12.5%까지 capacity를 줄였을 때까지 점진적인 개선이 관찰되었습니다. 따라서 네트워크는 전체 capacity의 self-attention 및 MLP 연산 기회가 빈번하게 주어지는 한, 상당한 용량 감소에 대해 강건한 것으로 보입니다.

그림 4. 는 최적의 MoD transformer와 최적 baseline의 동일한 forward pass당 FLOPs입니다.
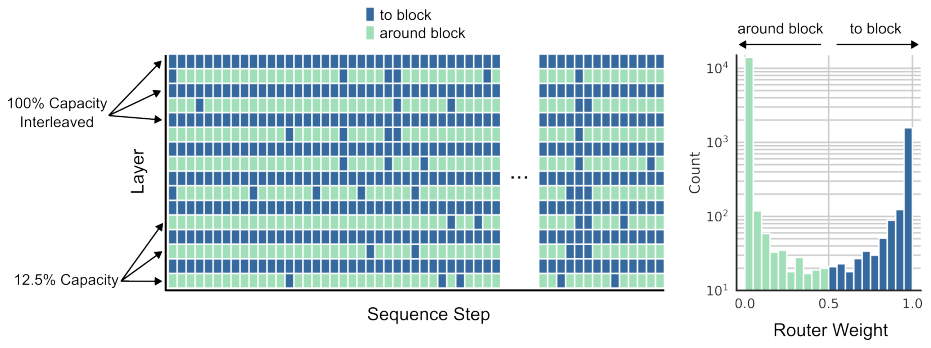
그림 5.는 routing block과 함께 훈련된 MoD transformer의 routing 결정을 시각화한 것입니다.

그림 6.은 auto-regressive 상황에서의 성능을 비교한 것입니다. non-causal하게 sampling을 해야하는 상황으로 인한 두 가지 해결방법들에 대해 성능을 확인할 수 있습니다. 또한 top-k prediction은 거의 99% 성능에 달하는 것까지 알 수 있습니다.
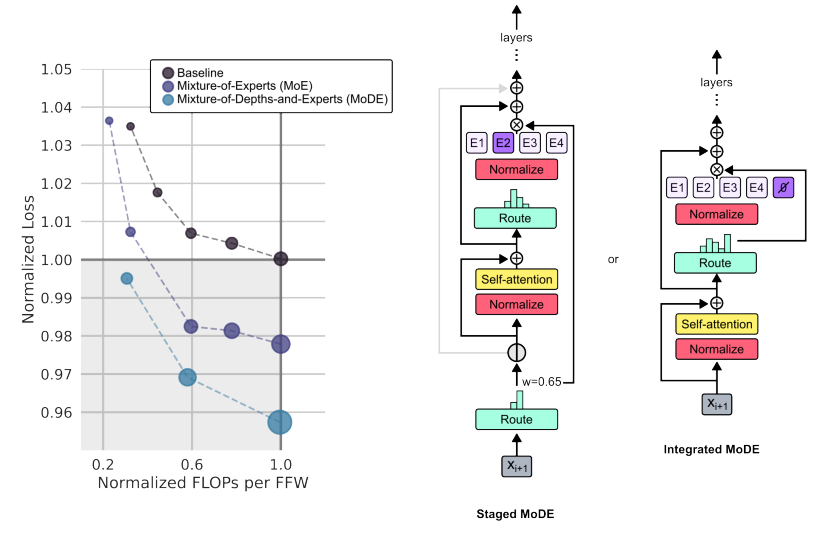
그림 7.은 MoE와 MoD를 합친 MoDE의 성능과 두 가지 변형을 그림으로 나타낸 것입니다.