
https://sustcsonglin.github.io/blog/2024/deltanet-2/
DeltaNet Explained (Part II) | Songlin Yang
DeltaNet Explained (Part II) An algorithm that parallelizes DeltaNet computation across the sequence length dimension Contents This blog post series accompanies our NeurIPS ‘24 paper - Parallelizing Linear Transformers with the Delta Rule over Sequence L
sustcsonglin.github.io
2026.01.04 - [[CoIn]/[Others]] - [CoIn] DeltaNet Explained (Part 1)
[CoIn] DeltaNet Explained (Part 1)
https://sustcsonglin.github.io/blog/2024/deltanet-1/ DeltaNet Explained (Part I) | Songlin YangDeltaNet Explained (Part I) A gentle and comprehensive introduction to the DeltaNet Contents This blog post series accompanies our NeurIPS ‘24 paper - Parallel
hw-hk.tistory.com
Parallel Scan for DeltaNet: A Failed Attempt
앞선 글에서 DeltaNet이 합성 태스크(diagnostic synthetic tasks)에서 매우 우수한 성능을 보인다는 것을 확인했습니다. 그렇다면 이제 최신 LLM으로 확장하기만 하면 될까요? 그렇게 간단하지는 않았습니다. 기존의 DeltaNet은 순수 RNN으로 취급되어서 O(N)의 순차적 단계(steps)가 필요했는데, 이는 대규모 병렬 처리 능력을 갖춘 GPU와 같은 현대 하드웨어에서는 비효율적입니다. 따라서 하드웨어 효율적인 학습을 가능하게 하기 위해 시퀀스 길이에 따라 DeltaNet을 병렬화할 수 있는 전략을 찾아야 했습니다. 먼저 실제로 적용되지는 않았지만 흥미로운 전략인 Parallel Scan에 대해서 먼저 논의합니다. 이 기법은 순차적인 연산을 트리 구조로 바꾸어 O(logN) 시간에 처리할 수 있게 해줍니다.
우선 Delta Update에서 행렬 곱의 형태로 변환해야 합니다. 아래는 DeltaNet의 원래 상태 업데이트 방정식입니다:
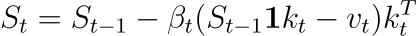
이를 행렬 곱의 형태로 변환하기 위해, 식은 단계 별로 전개할 수 있습니다:

이때 식을 간단히 하기 위해 다음과 같이 정의합니다:

그러면 업데이트 식은 다음과 같이 됩니다:
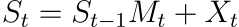
이를 통해 기존의 복잡한 Delta Rule 수식을 선형 점화식(Linear Recurrence) 형태로 정리했습니다. 이렇게 S_next = S_prev x A + B 형태로 만들면, 일반적인 병렬 스캔(Parallel Scan) 알고리즘을 적용할 수 있는 표준 형식이 됩니다. 여기서 M_t는 이전 상태를 현재 상태로 전이시키는 행렬이고, X_t는 현재 시점의 새로운 정보입니다.
이때 사용하는 결합 연산자는 행렬 곱(⊗)과 행렬 합(⊕)이 이항 연산자 역할을 수행합니다. 이때 두 연산자는 아래의 속성을 모두 만족합니다:

병렬화(parallel scan)을 하려면 계산 순서를 바꿔도 결과가 같은 결합 법칙이 성립해야 하며, 위 속성들에 대한 수식들은 행렬 곱이나 덧셈이 결합 법칙을 만족하는 연산자임을 보여줍니다. 그리고, 이 프레임워크에 따라 상태 쌍(pair)을 다음과 같이 정의합니다:

그리고 이 쌍들을 결합하는 결합 연산자를 정의합니다:

연산자 \bullet 은 시간 i와 시간 j를 합쳐서 한 번에 계산하는 효과를 내며, 업데이트의 시간적 의존성을 보존합니다. 즉, 두 단계를 결합할 때 이전의 업데이트 항 X_i는 나중의 전이 행렬 M_j에 의해 변환되어야 하며, 나중의 업데이트 항 X_j는 변경되지 않고 그대로 더해집니다.
이 결합 연산자를 사용하면 parallel scan을 통해 모든 상태를 병렬로 계산할 수 있습니다. 알고리즘은 두 단계로 작동합니다:
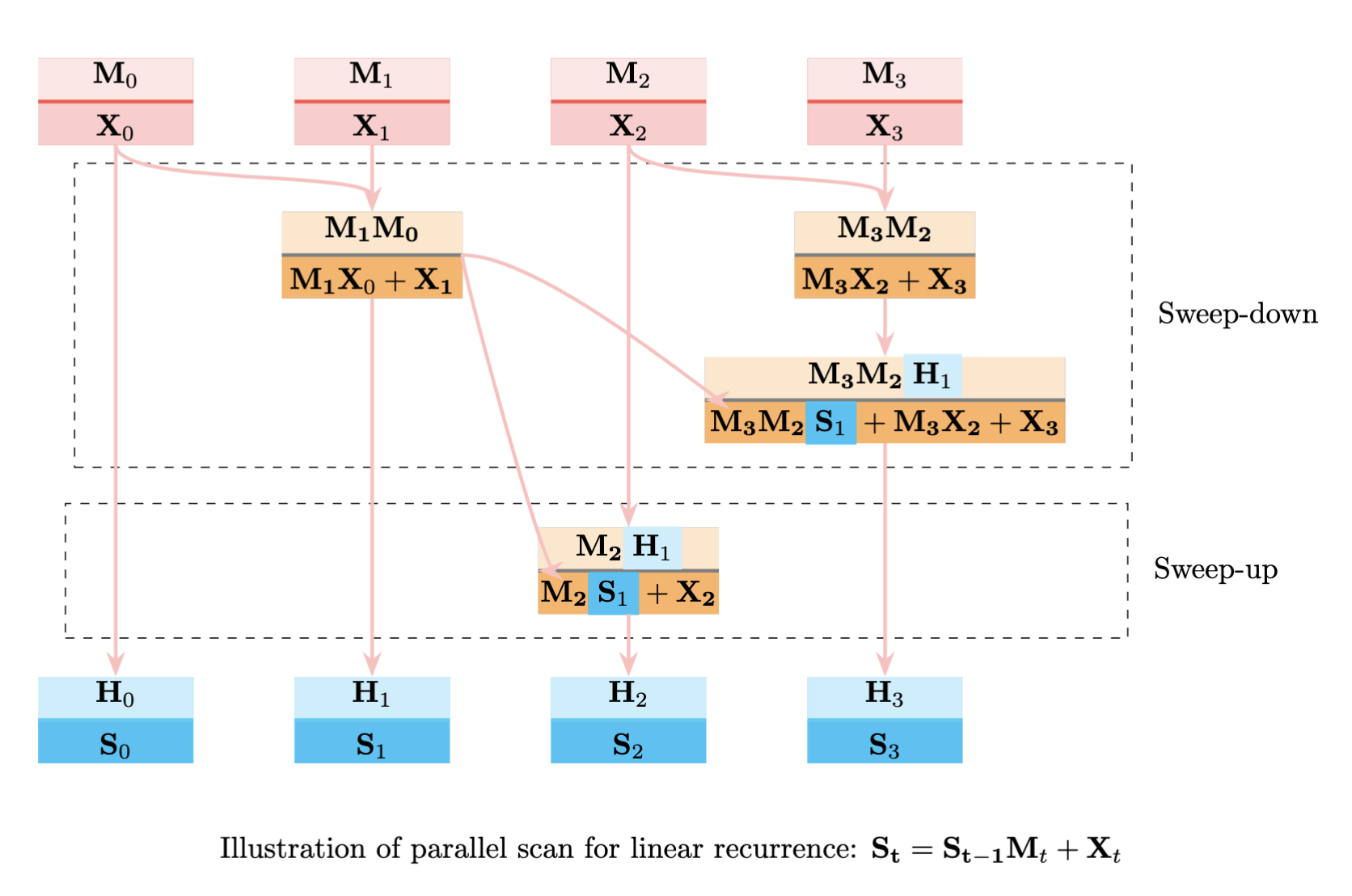
Sweep-Down Phase 에는 먼저 인접한 쌍들을 결합하여 부분 결과들을 병렬로 계산합니다(예: 0단계와 1단계에 대해 다음을 계산합니다):

마찬가지로 2단계와 3단계에 대해:

그런 다음 이 결과들을 결합합니다:
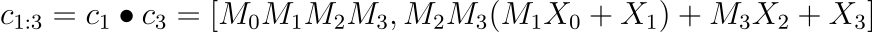
Sweep-Up phase 에는 부분 결과들을 사용하여 중간 상태들을 계산합니다. 이러한 병렬화는 DeltaNet의 순차적 상태 업데이트를 효율적인 병렬 계산으로 변환하여, 수학적 동등성을 유지하면서 순차적 의존성 체인을 O(N)에서 O(logN)으로 줄여줍니다. 이는 전형적인 Blelloch scan 알고리즘으로, 토너먼트 대진표처럼 인접한 두 개씩 묶어서 올라갔다가(Sweep-down), 다시 내려오면서(Sweep-up) 모든 시점의 누적 값을 계산합니다. 이를 통해 긴 시퀀스도 빠르게 처리할 수 있습니다.
이렇게 병렬화 할 수 있음에도 불구하고 DeltaNet에 대한 parallel scan은 두 가지 주요 문제에 직면합니다: 계산 복잡도(computation complexity)와 메모리 요구 사항(memory requirement)입니다.
첫 번째 문제는 시간 복잡도에 있습니다. DeltaNet의 경우, M_t를 dense 행렬로 취급할 때 행렬 곱의 3차의 비용(행열이 dxd라면 dxd 행렬간의 곱은 O(d^3)의 시간 복잡도를 갖습니다) 때문에 parallel scan은 O(logN*N*d^3)가 됩니다. 언뜻 보기에는 M_t가 가진 단위 행렬과 low rank 구조를 활용하면 d^3에 해당하는 시간복잡도보다 더 가볍게 행렬 곱을 수행할 수도 있어 보입니다(M_t가 identity 행렬과 벡터들의 외적을 이용해 만들어진 행렬의 덧셈이기 때문에, 이를 이용하면 더 빠르게 행렬 곱을 수행할 수 있다는 주장). 두 인접한 행렬을 곱한다면 다음과 같은 식을 얻을 수 있습니다:
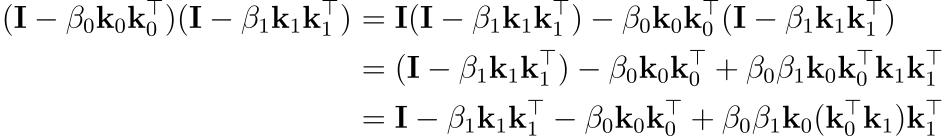
위 계산은 단위 행렬과 low rank의 구조를 활용함으로써 벡터 내적 k^Tk와 벡터간의 외적만 계산하면 되기 때문에, 복잡도를 O(d^3)에서 O(d^2)로 줄여줍니다. 마찬가지로 다음 쌍에 대해서도 비슷하게 계산됩니다. 이제 c_{1:4}와 같이 넓은 범위를 계산하기 위해 이 결과들을 결합하려 하면, 곱셈은 점점 복잡해집니다:
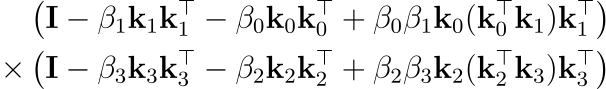
첫 번째 괄호 안의 각 항은 두 번째 괄호 안의 각 항과 곱해져야 합니다. 각 행렬은 처음에는 O(1)개의 rank-1 항의 합이었지만, 이 곱셈은 항의 개수가 제곱으로 증가(quadratic growth)하는 결과를 낳습니다. parallel scan의 Log N 레벨을 거치고 나면, 결국 O(N^{logc})개의 항을 갖게 됩니다(c는 행렬당 초기 항의 개수). 비록 각 항이 rank-1 이라 할지라도, 항의 개수가 기하급수적으로 증가하기 때문에, 위 구조를 유지하는 것은 현실적이지 않습니다. 따라서 현대 하드웨어에서 dense matrix 연산의 효율성을 고려할 때, 이들을 O(d^3) 복잡도를 가진 dense matrix로 취급하는 것이 더 합리적인 접근이 됩니다.
정리하면, M_t = I - uv^T의 형태를 갖기 때문에, 굳이 dxd 형렬 전체를 만들지 않고 벡터 연산만으로 곱셈 결과를 표현할 수 있습니다. 즉 M_t 들의 곱을 반드시 O(d^3)의 시간복잡도로 풀지 않아도 됩니다. 하지만 두 덩어리를 합칠 때 (A + B + C)(D + E + F)꼴이 되면서 항이 3x3 = 9개로 늘어납니다. 스캔 단계가 깊어질수록 항의 개수가 감당할 수 없이 폭발합니다. 따라서 항을 일일이 관리하는 비용이 더 커지므로, 그냥 다 계산해서 숫자 꽉 찬 dxd 행렬로 만들고 일반 행렬 곱셈을 하는 것이 낫다는 것입니다. 하지만 이는 다시 연산량이 너무 많아진다는 문제로 돌아갑니다.
두 번째 주요한 문제는 공간 복잡도입니다. parallel scan은 각 단계에서 모든 중간 dxd 행렬을 HBM(고대역폭 메모리)에 저장해야 합니다. 행렬 값을 상태로 가지는 선형 RNN의 경우, 이러한 저장 비용이 매우 큽니다(O(Nd^2), 만약 시퀀스 길이 N = 2048, 모델 차원 d = 2048일 때, O(Nd^2)는 수십 GB에 달해 메모리가 터지거나, 데이터를 읽느라 연산 속도가 느려집니다). 순환(recurrent) 방식의 계산은 이러한 저장을 업앨 수 있지만, parallel scan은 모든 state가 SRAM(캐시 메모리)에 들어가야 하기 때문에, 해결책은 없습니다. I/O 비용이 이 계산을 지배한다는 점을 고려하면, parallel scan은 실제로 바람직하지 않을 수도 있습니다.
그래서 다음과 같은 논의 끝에:


이전에 언급했던 chunkwise algorithm을 고안했습니다. 이는 메모리 효율성을 계선하고 tensor core 활용도를 높이는 또 다른 유형의 결합 스캔입니다.
A Chunkwise Algorithm for DeltaNet
Linear Attention의 효율성은 전체 행렬을 메모리에 저장하는 대신, 벡터를 사용하여 state를 간결하게 유지할 수 있는 능력에서 나옵니다. 이것이 가능한 이유는 외적의 합을 행렬 곱으로 다시 쓸 수 있기 때문입니다:
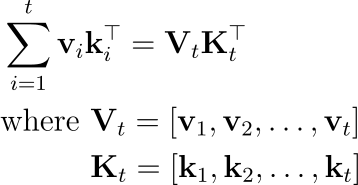
즉, t시점까지의 v와 k의 외적 합은 행렬 V와 K의 곱과 같습니다. 이 행렬 곱 형태는 tensor core가 장착된 최신 GPU에서 고도로 최적화되어 있습니다. 그리고 이 성질을 이용해 연산 속도를 높이는 것이 chunkwise algorithm의 기초입니다. 이 특정을 활용하여 모든 중간 hidden states들을 저장하는 대신, 크기 C의 일정한 간격으로 상태를 checkpoints로 저장할 수 있습니다. 이를 통해 S_0, S_C, ... 와 같은 드문드문한 states들만 얻습니다. 즉, 전체 시퀀스 길이(N)가 2048이고 청크 크기(C)가 128이면, 2048개의 상태를 다 저장하는 게 아니라 2048/128 = 16개의 상태만 저장하여 메모리를 아낍니다.
그리고 상태 업데이트와 출력 계산을 행렬 형태로 표현하면 다음과 같습니다:

S_{t+1}은 다음 청크에 대한 state로, 이는 이전 청크 state S_t에 현재 청크의 정보 총합 V^TK을 더하여 다음으로 넘깁니다. 또한, O_t는 현재 청크의 출력으로 다음의 두 부분의 합으로 계산됩니다: 1) QS^T는 이전 청크들에서 넘어온 과거 정보 S_t를 현재 쿼리 Q로 조회합니다. 2) (QK^T⊙M)V는 현재 청크 내부에서의 attention입니다. QK^T는 일반적인 attention score이고, M은 causal masking을 위한 마스크입니다. 즉, 청크 내부의 토큰끼리 서로 주고받는 영향입니다. 이를 그림으로 나타내면 다음과 같습니다:
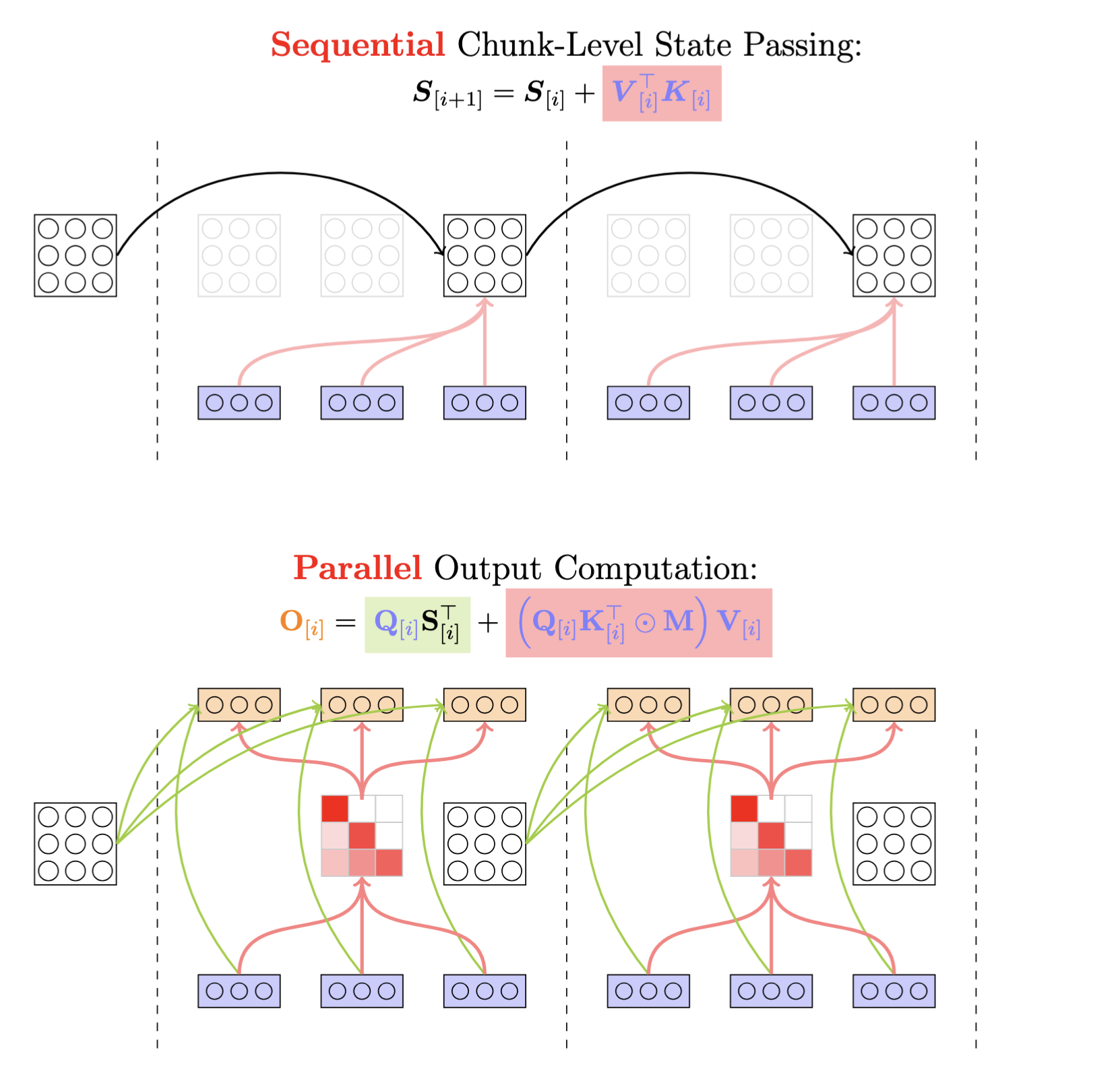
다시 정리해보면, 모든 시점의 상태를 저장하지 않고 청크 단위로만 상태(S)를 저장함으로써 메모리를 절약할 수 있으며, 청크 내부 계산은 GPU 효율성을 위해 행렬 곱(Matmul)으로 처리합니다. 또한 과거 정보를 반영하는 부분과(1) 현재 정보를 처리하는 부분(2)을 나누어, tensor core 활용을 극대화함으로써 속도를 향상할 수 있었습니다.
이는 Linear Attention에 관한 내용으로, 앞서 설명한 내용에 따르면 DeltaNet 전이 행렬들의 누적 곱은 수많은 중간 결과를 저장해야 하며, 간결한 표현이 불가능해 보였습니다. 하지만, DeltaNet의 전이 행렬은 Householder matrices와 매우 유사하며(특히 β=2일 때), 이들의 누적 곱에 대한 간결한 표현법이 존재합니다.

https://www.semanticscholar.org/paper/The-WY-representation-for-products-of-householder-Bischof-Loan/c736a2e7bcf73f8c8418c329f2f4dc01d6179442
www.semanticscholar.org
에서 소개된 WY representation이라 불리는 이 방법을 사용하면, 누적 곱을 다음과 같이 쓸 수 있습니다:
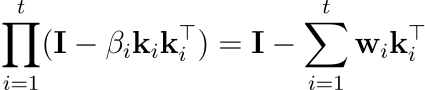
이를 증명하면 다음과 같습니다:
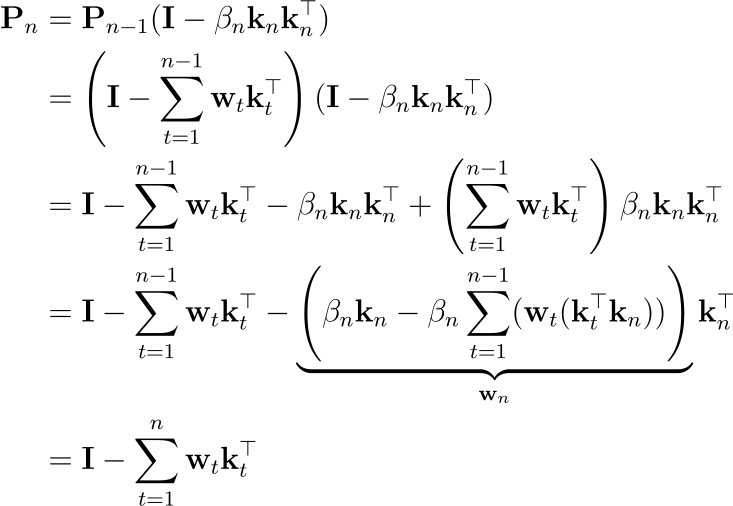
정리하면, DeltaNet은 S_t = S_{t-1}(I - βkk^T) + ... 의 형태입니다. 괄호 안의 항을 계속 곱해 나가면 항의 개수가 폭발적으로 늘어나는 문제가 있었습니다. 이때 수학적 기법(WY Decomposition)을 통해, 아무리 곱해도 결과는 항상 "단위 행렬(I) 빼기 어떤 행렬(WK^T)" 꼴로 유지된다는 것을 발견했습니다. 즉, 복잡한 연산 과정을 압축된 벡터 w 하나로 표현할 수 있게 되어 메모리와 연산 효율을 잡을 수 있게 된 것입니다.
마찬가지로, 수학적 귀납법을 통해 Sn이 u와 k의 외적 합으로 정리할 수도 있습니다:
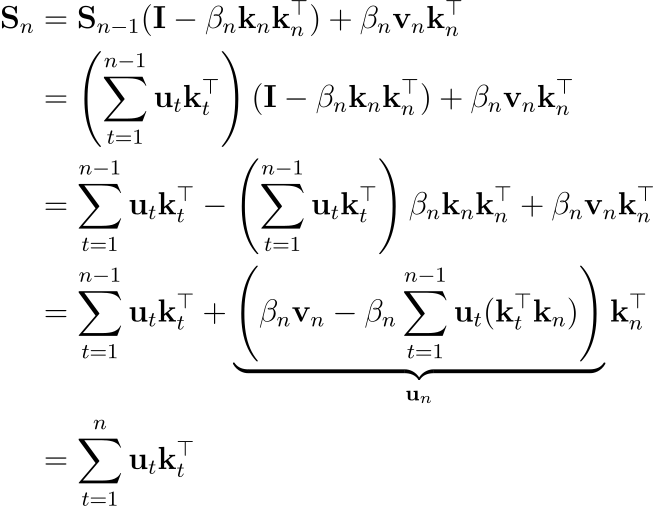
이 외적의 합 구조는 앞서 설명했던 Linear Attention의 업데이트 형태와 매우 유사함을 알 수 잇습니다. 즉, DeltaNet도 chunkwise하게 계산할 수 있다는 것입니다. Linear Attention과 유사하게, 크기 C 간격으로 상태를 저장하는 checkpointing을 사용할 수 있습니다.
우선 DeltaNet의 recurrence를 풀어보면 다음과 같습니다:

이는 과거 시점 i에서 들어온 정보(X_i)는, 그 이후인 i+1 부터 현재 t까지의 모든 전이 행렬(M)들의 곱만큼 변형되어 살아남는다는 것을 반영한 식입니다. 예를 들어, S4의 경우 다음과 같습니다:

이를 summation과 product로 일반화하여 표현하면 다음과 같습니다:

Linear Attention과 유사하게, 크기 C의 규칙적인 간격으로 상태를 저장하는 checkpointing을 사용할 수 있으며, 청크 i 내부의 임의의 위치 r에 대해, 다음과 같은 식을 갖습니다:
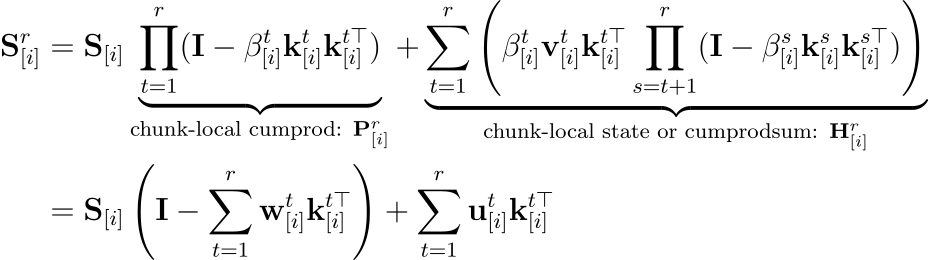
S_[i]는 이 청크가 시작될 때의 초기 상태를 의미하며, chunk-local comprod(P_[i])는 청크 시작부터 현재 r까지의 모든 망각(forgetting) 행렬들의 곱을, chunk-local state(H_[i])는 청크 내부에서 새로 생성된 정보들이 현재 r까지 오면서 감쇠되고 남은 합을 의미합니다. 이를 앞서 언급한 WY representation을 적용하여, 단순한 외적의 합 형태로 변환할 수 있습니다. 이때 w와 u는 다음과 같이 구할 수 있습니다:

여기서 w와 u는 WY representation을 사용해 계산되지만, 시퀀스의 처음이 아니라 각 청크의 첫번째 위치부터 시작하여 계산되며, 이는 청크 간의 병렬 계산을 가능하게 합니다. 이제 출력값을 구하면 다음과 같습니다:

기본적으로 출력 o는 현재 상태 S에 쿼리 q를 곱한 것입니다. 이때 Sr_[i]를 앞서 구한 식을 이용해 전개하면 위와 같이 풀 수 있습니다. 이는 (초기 상태의 영향) + (청크 내부 변화의 영향) 으로 해석할 수 있으며, 마지막에 k^Tq는 attention score를 의미합니다. 즉, 출력값은 과거의 기억을 조회한 값에다가 현재 청크 내부의 어텐션 결과를 더한 것입니다. 마지막으로, GPU에서 tensor core를 이용해 한 번에 계산하기 위한 행렬 형태입니다:

정리하면, 복잡한 RNN 식을 WY representation 으로 풀어서 덧셈의 형태로 만들었고, 이를 청크 간(global)과 청크 내부(local)의 연산으로 분리했습니다. 최종적으로 행렬 곱 형태로 정리함으로써, GPR에서 병렬 처리가 가능하면서도 RNN의 forgetting 기능을 수행할 수 있게 만들었습니다.
chunkwise parallel form은 DeltaNet의 대부분의 연산을 Linear Attention과 유사하게 효율적인 행렬 곱으로 변환해 줍니다. 하지만 핵심적인 계산 병목은 바로 업데이트 벡터 U와 W를 재귀적으로 구성해야 한다는 점입니다. 다시 말해, 앞선 수식에서 W를 구하는 경우, w1을 구해야 w2를 구하고, w2를 구해야 w3를 구하는 구조였습니다. 이는 GPU에 맞지 않습니다. 따라서 재귀적인 계산 과정을 효율적인 행렬 곱을 활용할 수 있는 형태로 재구조화 시킴으로써 이를 해결할 수 있습니다. 이를 그래프 이론을 통해 이해할 수 있습니다.
그래프 이론에서, 가중치가 있는 방향 그래프의 인접 행렬 A는 직접적인 연결 관계를 포착합니다. 이때 A_{i,j}는 노드 j에서 i로 가는 간선의 가중치를 나타냅니다. 이때 (I - A)^{-1}를 계산하면, 각 원소 [i,j]는 j에서 i로 가는 모든 가능한 경로의 가중치 합을 나타냅니다. 즉, W를 구하는 과정에서의 줄줄이 계산하는 과정을 그래프의 path라고 생각하면, A가 B에 영향을 주고, B가 C에 영향을 주면, 결국 A가 C에 간접 영향을 준다는 원리를 이용하여 모든 영향력을 한 번에 계산하는 행렬 (I - A)^{-1}을 만들겠다는 의미입니다.
다음은 재귀 업데이트 식입니다:
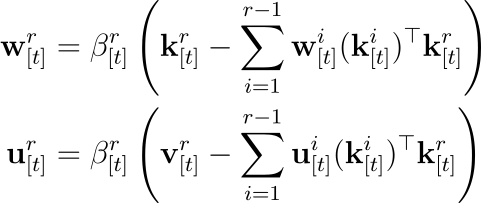
노드는 시퀀스의 각 위치를 나타내며, 방향 간선은 i<r 인 위치 i에서 r로 연결됩니다. 간선 가중치 βkk^T는 key의 유사도와 학습률을 통한 상호작용을 인코딩합니다. 이 그래프 구조는 인접 행렬 A로 표현될 수 있으며, 다음과 같습니다:

A는 strictly lower triangular(대각선 성분이 0인 하삼각 행렬, K 행렬을 자기 자신과 곱하면 KK^T 모든 토큰 쌍의 유사도가 한 번에 나오며, 여기서 과거가 미래에 주는 영향만 남기기 위해 하삼각 행렬 부분만 취합니다)이므로 (I-A)^{-1} 또한 대각선이 1인 하삼각 행렬이 됩니다. 이 특별한 구조 덕분에 일반적인 역행렬 연산 대신 forward substitution 등을 통해 효율적으로 역행렬을 구할 수 있습니다. 따라서 역행렬 T는 다음과 같습니다:
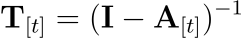
이는 일반적인 고비용의 역행렬 계산을 피하게 해주어 계산 효율성을 크게 높여주며, 위치들간의 모든 누적된 영향 결로를 포착하고 있는 T를 구한 후, 마지막 곱셈을 수행합니다:
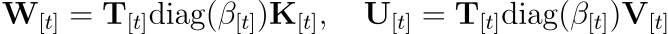
이렇게 하여 하드웨어 효율적인 형태로 누적된 영향력을 이용해 업데이트를 계산합니다. 정리하면, 청크 내부에서 w1 -> w2 -> w3 순서로 구해야 해서 GPU 병렬화가 막힙니다. 그래서 이 순서 의존성을 그래프로 해석한 후, 모든 관계를 인접 행렬 A(KK^T의 하삼각)로 만듭니다. 이 행렬의 역행렬 T = (I-A)^{-1}}를 구한 후, 원래 입력값 K,V에 T를 곱해버리면, 순차적으로 계산할 필요 없이 행렬 곱 한 번에 모든 시점의 W와 U가 나옵니다. 덕분에 DeltaNet은 Recurrence 구조를 갖고 있음에도 불구하고, 100% tensor core를 이용한 병렬 학습이 가능해집니다.
저자들은 triton을 사용하여 DeltaNet의 순환 버전과 청크 단위 병렬 버전을 모두 구현했습니다. 실험에서는 모델 차원을 d = 2048로 고정한 상태에서, 시퀀스 길이(L)와 헤드 차원(d_{head})을 변화시키며 성능을 비교했습니다. 공정한 비교를 위해 배치 크기를 조절하여 총 시퀀스 요소 수를 16,384개로 일정하게 유지했습니다.
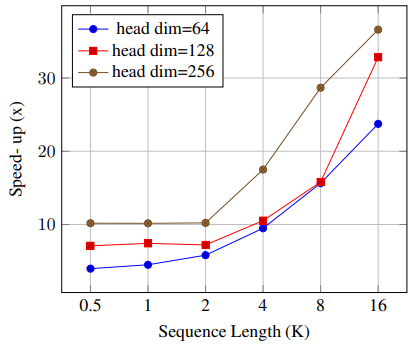
위 그림에서 볼 수 있듯이, 청크 단위 병렬 접근법은 순환 방식의 baseline보다 일관되게 더 뛰어난 성능을 보입니다. 더 중요한 점은 시퀀스가 길어질수록, 그리고 헤드 차원이 커질수록 이 성능 격차가 더 뚜렷해진다는 것입니다. 그 이유를 이해하기 위해, recurrence 구현의 두 가지 근본적인 한계를 살펴보겠습니다:
우선 병렬화 전략입니다. 순환 구현은 시퀀스를 step-by-step으로 처리하며, GPU 코어를 바브게 돌리기 위해 주로 두 가지 병렬화 소스에 의존합니다: batch 차원(여러 시퀀스 동시 처리)과 헤드 차원(여러 attention head 동시 계산)입니다. 이 전략은 시퀀스 길이가 적당하고 배치 크기가 클 때는 잘 작동했지만, 현대의 학습 시나리오에서는 문제에 직면합니다. 오늘날의 모델은 점점 더 긴 시퀀스나 큰 파라미터를 다루며, 메모리 효율을 위해 작은 배치 크기를 써야 할 때가 많습ㅂ니다. 이러한 변화는 FlashAttention2 논문에서도 강조되었는데, 시퀀스 레벨의 병렬화가 학습에 필수적이라고 지적했습니다.
시퀀스 차원에 대한 병렬화 능력이 없다면, 순환 구현은 근본적인 병목에 부딪힙니다. (배치 크기 x 어텐션 헤드 수)가 적을 때, 최신 GPU를 완전히 가동할 만큼 충분한 일감을 제공하지 못하는 것입니다.
두 번째 한계는 하드웨어 활용도와 관련이 있습니다. 최신 GPU는 행렬 곱 연산을 가속화하기 위해 설계된 특수 tensor core를 포함하고 있으며, 이는 동일한 FLOP을 가진 다른 연산에 비해 반정밀도(half-precision) 계산 시 최대 16배의 속도 향상을 제공합니다. 순환 구현은 비록 이론적인 총 FLOP 수는 적지만, 이러한 하드웨어 가속기를 효과적으로 활용하는 데 어려움이 있습니다. 이는 특히 문맥 검색과 같이 상당한 메모리 용량이 필요한 작업에 필수적인 '큰 헤드 차원'을 사용할 때 문제가 됩니다.
반면 청크 단위 구현은 계산을 재구조화하여 tensor core활용을 극대화함으로써, 이론적 FLOP 수가 더 높음에도 불구하고 더 나은 실제 성능을 달성합니다. 이 분석은 현대의 하드웨어 효율적 딥러닝의 중요한 원칙을 보여줍니다: 단순한 FLOP 수치가 항상 실제 소요 시간과 직결되지 않는다는 것입니다. 특수 하드웨어 가속기를 활용하고 높은 GPU 활용률을 유지하는 능력이 이론적인 연산 횟수보다 더 중요한 경우가 많습니다. 그리고 청크 단위 구현은 이러한 하드웨어 현실에 계산 방식을 맞춤으로써 성공을 거두었습니다.

마지막으로 1.3B 파라미터 규모에서 DeltaNet의 학습 처리량을 다른 모델들과 비교했습니다. DeltaNet은 경쟁력 있는 처리량을 달성했으며, GLA(Gated Linear Attention)보다 아주 약간 느린 수준입니다. 이 작은 성능 차이는 DeltaNet의 더 표현력 있는 전이 행렬을 얻기 위한 합리적인 trade-off 입니다.