
https://arxiv.org/abs/2502.18845
Sliding Window Attention Training for Efficient Large Language Models
Recent advances in transformer-based Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks. However, their quadratic computational complexity concerning sequence length remains a significant bottleneck for processing l
arxiv.org
Abstract.
최근 transformer 기반 LLM의 발전은 다양한 작업에서 놀라운 능력을 입증했습니다. 그러나 시퀀스 길이에 대해 2차(quadratic)로 증가하는 연산 복잡도는 긴 문서를 처리하는 데 있어 여전히 심각한 병목으로 남아 있습니다. 이에 따라 긴 시퀀스에서 LLM의 효용성을 높이기 위해 sparse attention이나 state space model과 같은 많은 노력들이 제안되었지만, 복잡한 아키텍처와 병렬 학습 기법을 필요로 합니다. 따라서 기본적인 transformer 아키텍처르 유지하면서도 간단하고 효율적인 모델이 요구됩니다.
이를 위해 sliding window attention training을 통해 효율적인 long-context 처리를 가능하게 하는 SWAT을 제안합니다. SWAT은 효율적인 정보 압축과 유지를 위해 softmax를 sigmoid로 대체합니다. 그 후 학습 과정을 안정화하기 위해 balanced ALiBi와 RoPE를 사용합니다. inference 단계에서 SWAT은 모델 성능을 보존하는 동시에 sliding window attention을 통해 선형(linear) 연산 복잡도를 유지하며, 다른 linear recurrent architectures들과 비교하여 상식 추론 벤치마크에서 SOTA를 달성했습니다.
Introduction.
LLM은 텍스트 생성부터 복잡한 추론에 이르기까지 다양한 작업에서 놀라운 능력을 보여줍니다. 하지만 기억을 통해 긴 문맥을 효율적으로 처리할 수 있는 인간과 달리, LLM은 2차(quadratic) 복잡도로 인해 이를 처리하는 데 어려움을 겪습니다. 이는 실제 애플리케이션에 있어 근본적인 문제를 야기하며, 확장 가능한 솔루션에 대한 필요성이 대두되고 있습니다. 이에 긴 시퀀스를 효율적으로 처리하기 위한 여러 접근법이 제안되었습니다:
- Attention score를 선택적으로 계산하여 연산량을 줄이는 sparse attention mechanisms.
- 재귀적인 hidden states를 통해 시퀀스를 효율적으로 처리하려는 linear attention의 변형들.
- SSM을 활용하여 recurrent architecture를 갖춘 모델들
2026.01.04 - [[CoIn]/[Others]] - [CoIn] DeltaNet Explained (Part 1)
[CoIn] DeltaNet Explained (Part 1)
https://sustcsonglin.github.io/blog/2024/deltanet-1/ DeltaNet Explained (Part I) | Songlin YangDeltaNet Explained (Part I) A gentle and comprehensive introduction to the DeltaNet Contents This blog post series accompanies our NeurIPS ‘24 paper - Parallel
hw-hk.tistory.com
그러나 이런 솔루션들은 효율성을 달성하기 위해 모델 성능을 타협하거나, 구현 및 배포의 편의성을 위한 기존 기술들을 충분히 활용할 수 없는 새로운 복잡한 아키텍처와 병렬 학습 기법을 요구하여 구현과 배포를 어렵게 만들기에, 기존 transformer 아키텍처를 기반으로 한 효율적인 접근법이 요구됩니다.
대표적으로 sparse attention 접근법인 sliding window attention(Child et al., 2019)은 추가적인 모델 구성 요소를 더하지 않고 추론 연산 복잡도를 선형(linear)으로 압축할 수 있어 가장 직관적인 해결책이 됩니다. 하지만 이 접근법은 다음과 같은 문제들이 존재합니다:
- 현재 SWA에 대한 연구들은 주로 추론 단계에서 attention sink 문제를 해결하는 데 집중하고 있습니다. attention sink란 모델이 초기 토큰들에 과도한 attention을 할당하여 시퀀스 전반에 걸쳐 attention 가중치가 불균형하게 분포되는 현상입니다(Xiao et al., 2023). 그러나 이들은 학습 과정은 그대로 두어 추론과 학습 간의 격차(gap)를 발생시킵니다.
- Attention window 범위 밖의 토큰들은 예측 시 무시되어, 긴 문맥 모델링에서 정보 손실을 초래합니다.
Note: Attention sink란 transformer 모델들이 문장에 맨 첫 번째 토큰에 쓸데없이 엄청난 attention을 쏟아부으며 휴지통처럼 쓰는 현상을 말합니다. 기존의 transformer의 softmax 함수는 모든 토큰에 대한 attention score의 합은 무조건 1이어야 한다는 규칙이 있습니다. 따라서 현재 처리 중인 단어와 관련해서, 앞선 문맥에서 딱히 중요한 정보가 없을 때도 softmax 규칙에 의해 어딘가에는 점수를 줘야 합니다. 그래서 모델은 그냥 맨 앞에 있는 시작 토큰에 남는 점수를 몰아주는 선택을 합니다(시작 토큰은 항상 존재하기 때문에).
Note: 기존의 SWA 관련 연구들은 이 문제를 맨 앞 토큰만은 살려두는 식으로 해결했습니다. SWA를 사용하는 모델들은 학습때는 전체 문맥(full attention)을 다 보며 학습을 했기 때문에, 첫 번째 토큰에 점수를 몰아주는 버릇이 생깁니다. 그 후 긴 문장을 처리하기 위해 SWA를 적용해서 맨 앞 토큰을 잘라버리면, 모델이 점수를 버릴 곳이 없어서 perplexity가 폭발하는 문제가 발생합니다. 따라서 기존의 SWA 관련 연구들은 window를 밀더라도, 맨 앞 토큰 몇 개는 지우지 않는 방식으로 이를 해결했습니다. 그래서 학습 때는 전체를 다 보고 배웠지만, 추론 때는 '최근 토큰 + 맨 앞 토큰'을 보기 때문에, 이런 격차로 인해 모델이 제 성능을 발휘하지 못하는 것입니다.
본 논문에서는 효과적으로 SWA 학습을 달성하고 앞서 언급한 문제들을 해결하기 위해 SWAT 프레임워크를 제안합니다. 우선 SWAT은 softmax 연산을 sigmoid로 대체함으로써, attention sink 문제를 해결하며, 필요한 정보가 많으면 여러 토큰에 동시에 높은 점수를 주는 dense attention이 가능합니다. 즉 window 내의 정보를 더 알차게 담을 수 있는 것입니다. 하지만 이렇게 sigmoid를 쓰면, 모두 다 중요하다고 해버려서 정보가 너무 꽉 차버리는(overloaded) 부작용이 생길 수 있습니다. 이를 막기 위해 거리 기반 페널티를 주는 ALiBi(Attention with Linear Biases, 현재 토큰과 거리가 먼 토큰일수록 attention score에 감점을 주는 방법)를 사용합니다. 한편, SW를 사용하면 위치 정보가 계속 바뀔 수 있기 땜누에, RoPE를 통해 위치에 대한 학습 안정성을 제공합니다. 따라서 해당 논문에서 기여한 바는 다음과 같습니다:
- SWA 추론의 저조한 성능을 분석하고, 이를 softmax 연산의 높은 분산으로 인한 attention sink 문제 탓으로 규명합니다.
- sigmoid 활성화 함수와 균현 잡힌 RoPE를 결합하여 효과적인 정보 보존을 가능하게 하고 SWA 학습을 달성하는 SWAT을 제안합니다.
Understanding Transformer's Attention.
transformer의 self-attention layer는 일반적으로 입력 시퀀스 길이 N에 대해 O(N^2)의 연산 복잡도를 갖습니다. 순차적인 정보를 보존하면서 이 복잡도를 줄이기 위해, Longformer(Beltagy et al., 2020)에서 sliding window attention이 도입되었습니다. SWA는 각 토큰이 고정된 크기의 window내에 있는 이웃 토큰들의 attention 계산에만 참여하도록 제한합니다. 윈도우 크기 ω ≪ N일 때, 토큰당 연산 비용은 O(ω)로 줄어들며, 전체적으로 O(ωN)의 선형 복잡도를 만들어냅니다.

그림 1.은 SWA 메커니즘을 시각화한 것입니다. 여기서 window 크기는 3(ω=3)이고 깊이는 2(L=2)입니다. 현재 window에서 보이는 토큰들을 active tokens로 정의하며, 보이지 않는 토큰들, 즉 evicted tokens들에 대해서는 residual token과 past token으로 세분화 합니다. residual tokens들은 임베딩 layer에서는 sliding window에 보이지 않지만, 이들의 정보는 transformer layer를 통해 이웃한 ω-1개의 토큰으로 전달되며, 예측을 위해 부분적으로 보존된다고 볼 수 있습니다. 예를 들어, 위 그림 1. 에서 토큰 'a(residual token)'의 정보는 다른 토큰 'a(active token)'에 사용될 수 있습니다. 이론적으로 l-th transformer layer에서 단일 토큰의 정보 범위는 1 + (ω-1) * l 이며, 최대 범위는 1 + (ω-1) * L입니다. 위 그림 1. 에서는 1 + 2 * 2 = 5가 됩니다.
현재 오픈소스 LLM들이 구조적으로는 SWA 추론을 수행할 수 있지만, 안정적으로 개선된 결과를 얻는 데는 실패하고 있습니다.

그림 2.는 PG19 테스트 세트에서 다양한 SW 크기를 사용하여 4가지 오픈소스 LLM의 perplexity(PPL)을 분석한 결과입니다. 실험 결과 LLM들은 학습 시퀀스 길이 내에서 작동할 때만 최적의 성능을 발휘하며, 평가 길이가 늘어남에 따라 PPL이 늘어나는 것을 볼 수 있습니다. 이는 transformer가 본질적으로 학습 길이에 특화된 문맥 패턴을 학습하며, 추론 시 가변 길이 텍스트로 확장하는 데 실패함을 시사합니다.
논문의 저자들은 이 원인으로 두 가지를 지목합니다:
- 모델이 초기 토큰에 지나치게 의존하게 되는 attention sink 현상.
- 과거 토큰이 버려짐으로써 발생하는 정보 손실.
LLM이 시퀀스에 초기 토큰에 과도한 attention을 할당하는 attention sink 현상은 transformer 아키텍처에서 SWA 추론의 중요한 과제로 부상했습니다. Qwen2-7B의 attention pattern과 hidden states 통계를 분석한 결과 토큰 분산과 attention sink의 크기 사이에 강한 상관계가 있음을 발견했습니다. 즉, 첫 번째 토큰에 대한 hidden state 분산이 후속 토큰들보다 훨씬 높은 것입니다. 이는 attention sink가 정규화를 통한 분산 전파를 통해 나타난다는 증거입니다. 이때 Qwen2와 같은 모델들은 RoPE를 통해 명시적인 상대 위치 임베딩을 수행하고 있지만, 여전히 softmax 정규화 매커니즘을 통해 암시적인 절대 위치 정보를 학습합니다.
이에 대해 자세히 설명하면, transformer의 attention은 softmax 함수를 사용합니다. 이 식에서는 입력 값이 조금만 커져도, 결과 값은 지수적으로 커지는 것입니다. 이때 causal attention 구조상, 첫 번째 토큰은 자기 자신만 볼 수 있고, 뒤따르는 모든 토큰들에게 '보임'당합니다. 이런 causal 구조로 인해, 첫 번째 토큰은 자기 뒤에 오는 모든 토큰들의 예측 과정에 참여하며, 모든 토큰들에 대한 오차 신호를 모두 다 받아서 자신의 값을 업데이트 합니다. 즉, 다른 토큰들에 비해 업데이트의 빈도와 강도가 압도적으로 높습니다. 이 과정에서 첫 번째 토큰의 hidden state 값들은 다른 토큰들과 다른 독특한 통계적 분포를 띄게 되며, 분산(값의 변동 폭)이 매우 커지는 경향이 생깁니다.
softmax는 큰 값에 민감하므로, 분산이 커서 값이 튀는 '첫 번째 토큰'에게 매우 큰 점수를 몰아주게 되며, layer가 거듭되어도 계속 높은 상태로 유지되게 됩니다. 한편, RoPE는 수학적으로 1번 위치, 2번 위치 등 명시적으로 위치 정보를 벡터의 회전을 이용해 알려주는 방식인데, 모델이 학습하다 보니, 1번 위치에 있는 토큰(시작 토큰)은 항상 분산이 크다는 패턴을 발견하고, RoPE를 통해 위치 정보를 사용하는 것이 아닌, 분산이 큰 토큰을 기준으로 위치 정보를 활용하기 시작했습니다. 이때 SWA는 window를 사용하기 때문에, window를 밀어버리면, 첫 번째 토큰이 사라지고, 위치 정보를 완전 잃어버리는 것입니다.
이는 그림 2.를 통해서도 잘 알 수 있습니다. 그림 2.의 경우 window size가 평가하는 sequence length에 비해 작은 상황, 즉 첫 번째 토큰을 빼고 attention을 수행해야하는 상황에서는 성능이 급격히 나빠집니다. 만약 RoPE가 제 기능을 하고 있다면, 첫 번째 토큰이 없어져도 상관이 없어야 합니다. RoPE가 상대적인 위치를 항상 알려주고 있기 때문입니다. 하지만, 모델의 성능이 나빠졌다는 것은, RoPE가 주는 위치 정보만으로는 부족하며, 첫 번째 토큰을 기준으로 위치 정보를 얻었다는 것을 보여줍니다.
이런 attention sink 문제 외에도, softamx는 sliding window 추론 중에 심각한 정보 손실을 초래합니다. 아래는 softmax가 attention 점수를 만들어내는 예시입니다:

위 예시에서도 볼 수 있듯이, softmax의 지수적 특성은 logits 간의 차이를 극적으로 증폭시켜, 확률 질량의 대부분이 가장 높은 점수를 받은 토큰에 집중되게 하는 반면, 다른 토큰들은 심하게 억제됩니다. 요약하자면, softmax의 이런 sparsification은 전체 문맥(full-context) transformer에는 유익하지만, 이런 공격적인 filtering이 sliding window내의 과거 정보를 유지하는 모델의 능력을 저해하는 요소가 됩니다.
Note: softmax가 왜 full context transformer에 유익할까? full context에서는 sparsification이 주는 강한 filtering 효과가 매우 중요하기 때문입니다. full context 상황에서는 매우 많은 정보가 들어오며(context length가 너무 길기 때문에), 매우 긴 context에서도 중요한 정보만을 선택적으로 찾을 수 있습니다. 하지만 SWA 상황에서는 window의 크기가 매우 작기 때문에, window내의 정보들을 강한 filtering 하는 것은 가뜩이나 없는 정보들을 날려버리는 꼴이 될 수 있습니다.
Sliding Window Attention Training.
전통적인 transformer 학습은 전체 토큰 시퀀스를 처리하는 것을 포함하며, 이를 통해 모델이 global attention 매커니즘을 통해 long-range dependencies를 포착할 수 있게 합니다. 한편, SWA는 제한된 문맥 내에서 작동하므로 정보를 지속적으로 보존하기 위한 새로운 접근 방식이 필요합니다.

위 그림 4. 에서 볼 수 있듯이, SWA 학습은 LLM을 위한 두 가지 별개의 학습 패러다임, 즉 short sequence attention과 long sequence attention을 가능하게 합니다. 기존의 transformer 학습에서는 시퀀스 길이가 윈도우 크기보다 작습니다. 새로운 토큰들은 모든 토큰, 심지어 텍스트의 맨 처음 토큰(SOS)들로부터 정보를 획득하고 통합할 수 있습니다. 따라서 모델은 각 토큰 임베딩에 필수적인 정보를 유지하고 정보 추출 능력을 향상할 수 있으며, 이는 softmax 함수에 의해 더욱 강화됩니다.
SWA 학습은 각 윈도우 이동마다 신중한 과거 context 관리가 요구됩니다. 특히, 윈도우가 슬라이딩 된 후 오래된 토큰 임베딩은 버려집니다. 하지만 tranformer의 상위 layer에서는 새로운 토큰의 임베딩이 여전히 일정한 가중치로 오래된 토큰의 임베딩 정보를 유지하고 있습니다. 따라서 모델은 슬라이딩 윈도우로 인한 정보 손실을 방지하기 위해 상위 level에서 모든 과거 임베딩을 유지하려는 경향을 보이며, 이는 모델의 정보 압축 능력을 강화합니다.
Note: (내 생각) 그렇다면 model의 layer가 깊어지면 깊어질수록 transformer가 다룰 수 있는 context의 길이가 결정되며, 높은 layer는 한정된 양의 space에서 과거의 정보들을 압축해서 저장해야 한다는 부하가 걸릴 수도 있다.
SWAT은 sigmoid 활성화 함수와 통합된 위치 임베딩을 결합한 attention mechanism입니다. 입력은 차원이 d인 query, key, value로 구성되며, softmax 정규화를 사용하는 대신, scaled dot products에 sigmoid 활성화 함수를 적용하여 attention score를 구하며, 이를 통해 토큰 간의 상호 억제(mutuaal suppression)를 방지합니다:

sigmoid 활성화 함수의 dense attention 패턴에 bias를 도입하고, sliding window 내에서 토큰 표현들을 더 잘 구분하기 위해, 기존 ALiBi 메커니즘의 양방향 확장판인 balanced ALiBi를 제안합니다. ALiBi는 transformer가 위치를 이해하는 방식을 거리의 관점으로 재해석한 것입니다. attention score를 계산할 때, 두 토큰 사이의 거리에 비례해서 점수를 깎는 것입니다. 이는 윈도우 내의 입력 subsequence에 대해, attention score에 위치 의존적인 편향을 추가하는 것으로 해석할 수 있습니다:

여기서 m과 n은 sequence 내 토큰의 인덱스를 나타내며, s는 기울기(slope)를 나타냅니다. slope는 거리에 따른 페널티를 얼마나 줄 것인가를 결정하는 민감도 입니다. directional inductive bias를 강제하기 위해, 즉 거리가 멀어지면 중요도가 떨어지는 것을 강제하기 위해 음의 기울기만 사용하는 기존 ALiBi와 달리, SWAT에서는 서로 다른 attention head에 걸쳐 양의 기울기와 음의 기울기를 모두 사용합니다. h개의 head를 가진 모델의 경우, h/2개의 head에는 양의 기울기를 할당하고, 나머지 헤드에는 음의 기울기를 할당합니다. 기울기의 크기는 ALiBi와 유사하게 등비수열을 따르지만, 양방향 모두에 적용됩니다:

k는 각 방향에 대해 1부터 h/2까지의 범위를 가집니다. 이러한 양방향 기울기 설계는 attention head들이 서로 다른 시간적 방향에 특화되도록 하며, forward-looking head들은 최근 문맥에 집중하고 backward-looking head들은 과거 정보를 보존하게 합니다. 즉, forward-looking head들은 음의 기울기를 갖고 있기 때문에, 거리가 떨어질수록 점수가 계속 깎입니다. 이는 가까이 있는 토큰들에 대해서만 계산하도록 유도합니다. 한편, backward-looking head들은 양의 기울기를 갖고 있기 때문에, 거리가 멀어질수록 점수가 올라갑니다. 즉, 과거에 있는 정보들을 처리하는데 집중할 수 있으며, 이는 과거 정보들을 압축해야할 필요가 있는 SWA에서 중요합니다.
Softmax를 sigmoid로 교체한 후에는 정규화를 통해 얻던 암시적인 위치 정보가 소실되어 학습 불안정성을 초래합니다. 게다가, balanced ALiBi가 attention score를 통해 위치적 분산을 제공하기는 하지만, 그 위치 신호는 여전히 약하며, 이를 해결하기 위해, 명시적 위치 정보를 강화하고자 RoPE를 추가로 사용합니다:
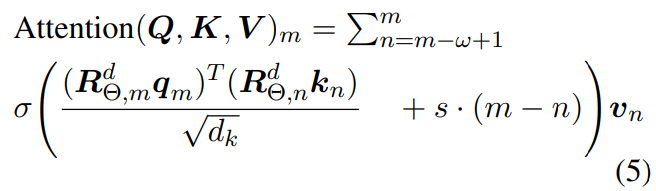
이러한 sigmoid 활성화, balanced ALiBi, RoPE의 결합을 통해 Vanilla Transformer의 sparsification을 보완할 수 있으며, 학습의 안정성을 보장하고, 단일 토큰 임베딩에 포함된 정보를 강화합니다.
SWAT의 아키텍처는 표준 attention layer와 거의 동일하기 때문에, ALiBi 계산에 따른 추가적인 오버헤드를 제외하면 동일한 attention 길이 하에서 토큰당 연산 비용을 거의 같습니다. 이때 sliding window의 사용으로 인한 전체 연산은 선형(Linear)가 되며, 따라서 추론 연산 복잡도는 다음과 같습니다:

Experiments.

표1. 은 다양한 모델들과 SWAT의 성능을 비교한 표이며, SWAT (-)은 ALiBi에서 음의 기울기를, (+)는 양의 기울기를, (-+)는 절반은 음의 기울기, 절만은 양의 기울기를 갖고 학습한 SWAT을 말합니다.
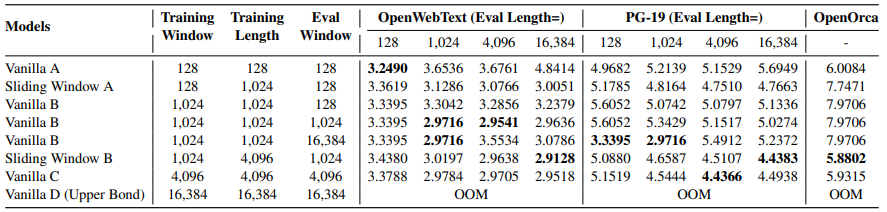
표2. 는 다양한 슬라이딩 윈도우 크기와 시퀀스 길이가 미치는 영향입니다. 동일한 모델 구조에서, SWA 학습은 더 긴 시퀀스 길이에서 성능이 높았으며, vanilla transformer는 학습 길이와 평가 길이가 일치할 때만 최적으로 동작하는 반면, SWA는 일관된 성능을 보입니다.

표3. 은 모델의 구성 요소의 다양한 조합이 긴 문맥 성능에 미치는 영향을 이해하기 위한 실험 결과입니다. No.1 과 No.2를 비교했을 때, vanilla tranformer에서 softmax를 sigmoid로 직접 대체하는 것은 심각한 성능 저하를 초래하는데, 이는 아마도 (토큰 간) 상호 억제 없이 토큰 임베딩에 정보가 과부화되기 때문입니다. 따라서 ALiBi를 사용해 위치 정보를 기반으로 토큰 임베딩의 차이를 구별하면 학습이 안정화될 수 있습니다(No.10, No.11).