
https://arxiv.org/abs/1911.09070
EfficientDet: Scalable and Efficient Object Detection
Model efficiency has become increasingly important in computer vision. In this paper, we systematically study neural network architecture design choices for object detection and propose several key optimizations to improve efficiency. First, we propose a w
arxiv.org
Abstract.
모델의 효율성은 컴퓨터 비전 분야에서 점점 더 중요해지고 있습니다. 본 논문에서는 객체 탐지(object detection)를 위한 설계외소를 연구하고, 효율성을 향상하기 위한 몇 가지 핵심 최적화 방법을 제안합니다:
- Weighted Bi-directional Feature Pyramid(BiFPN)를 제안합니다. 이는 쉽고 빠른 multi-scale feature fusion을 가능하게 합니다.
- backbone, feature network, 그리고 box/class prediction networks 모두에 대해 resolution(해상도), depth, width를 동시에 균일하게 확장하는 복합 스케일링 방법(compound scaling method)를 제안합니다.
이러한 최적화와 더 나은 backbone들을 기반으로, EfficientDet이라는 새로운 object detector를 제안합니다.
Introduction.
최근(2020년) 몇 년 동안 더 정확한 object detection를 향한 엄청난 발전이 있었습니다. 하지만 그와 동시에 SOTA object detector들은 연산 비용이 점점 더 비싸지고 있습니다. 이러한 거대한 모델 크기와 비싼 연산 비용은 모델의 크기와 지연 시간(latency)에 대한 제약이 심한 로봇 공학이나 자율 주행 자동차와 같은 많은 실제 애플리케이션에 배포하는 것을 방해합니다. 이러한 현실 세계의 자원 제약을 고려할 때, 모델의 효율성은 object detection에서 점점 더 중요해지고 있습니다.
더 효율적인 detector를 개발하려는 연구들은 많았지만(YOLO family, 기존 모델 압축 등), 이러한 연구들은 더 나은 효율성을 달성하는 목표를 충족할 뿐, 대개 정확도를 희생합니다. "과연 광범위한 자원 제약(예: 30억~3,000억 FLOPs) 전반에 걸쳐 더 높은 정확도와 더 나은 효율성을 모두 갖춘 확장 가능한(scalable) detection architecture를 구축하는 것이 가능한가?" 본 논문은 이 문제를 해결합니다. 1단계 detector 패러다임(YOLO)를 기반으로, backbone, feature fusion, class/box network의 설계 선택을 조사하고 두 가지 주요 과제를 식별했습니다:
- Efficient multi-scale feature fusion: FPN은 multi-scale feature fusion을 위해 널리 사용됩니다. 그리고 최근(2020년) PANet, NAS-FPN, 그리고 다른 연구들이 cross-scale feature fusion을 위한 더 많은 네트워크 구조를 개발했습니다. 서로 다른 입력 feature들을 융합할 때, 대부분의 이전 연구들은 구별 없이 단순히 합쳤습니다. 하지만, 서로 다른 input features들은 서로 다른 resolutions들을 가지고 있기 때문에, 융합된 output feature에 불균일하게 기여한다는 것을 발견했습니다. 이를 해결하기 위해 Weighted Bi-directional Feature Pyramid Network, BiFPN을 제안합니다. 이는 학습 가능한 가중치를 추가하여 서로 다른 input feature들의 중요도를 학습하며, 동시에 top-down 및 bottom-up multi-scale feature fusion을 반복적으로 적용합니다.
- Model scaling: 이전 연구들은 더 높은 정확도를 위해 주로 더 큰 backbone network나 더 큰 입력 이미지 크기에 의존했지만, 정확도와 효율성을 모두 고려할 때 feature network와 box/class prediction network 모두 scaling하는 것도 중요하다는 것을 관찰했습니다. 이에 compound scaling method를 제안합니다. 이는 모든 backbone, feature network, box/class prediction network에 대해 resolution/depth/width를 공동으로 스케일링 합니다.
[CoIn] 논문 리뷰 | Feature Pyramid Networks for Object Detection (Lin et al., 2017)
https://arxiv.org/abs/1612.03144 Feature Pyramid Networks for Object DetectionFeature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representa
hw-hk.tistory.com
Note: Efficient multi-scale feature fusion 부분에서 서로 다른 input features들이 서로 다른 resolutions들을 가지고 있기 때문에, 융합된 output feature에 불균일하게 기여한다는 것이 어떤 의미일까요? 이는 해상도가 다르면 정보의 밀도가 다르기 때문입니다. 높은 해상도를 갖는 feature map은 적은 CNN layers들을 통과했기 때문에, 의미적인 정보는 별로 없지만, 기하학적이고 세밀한 정보는 많습니다. 한편, 낮은 해상도를 갖는 feature map은 많은 CNN layers들을 통과했기 때문에, 많은 의미적인 정보를 갖고 있지만, 기하학적으로는 많이 뭉개졌습니다. FPN에서는 이 두 feature maps들을 동등하게 더해서 output feature를 만듭니다(element-wise addition). 이 둘(bottom-up feature map과 top-down feature map)의 성질이 다르기 때문에, 합칠 때도 가중치를 다르게 두고 합쳐야 한다는 것이 Weighted Feature Fusion이 되는 것입니다.
아래의 그림 1.과 그림 4.는 COCO datasets에서의 성능 비교를 보여줍니다:


Related Work.
기존(2020년)의 객체 탐지기들은 주로 RoI(관심 영역) 제안 단계(RP)가 있는지(two-stage detectors), 없는지(one-stage detectors)로 분류됩니다. two-stage detectors들이 더 유연하고 정확한 경향이 있는 반면, one-stage detectors들은 사전 정의된 anchor를 활용하여 더 간단하고 효율적입니다. 최근(2020년) one-stage detector들은 그 효율성과 단순성 덕분에 상당한 관심을 받고 있으며, 본 논문에서는 주로 one-stage detector 설계를 따릅니다.
한편, 객체 탐지의 주요 어려움 중 하나는 multi-scale(다양한 크기)의 feature를 효과적으로 표현하고 처리하는 것입니다. 초기 detector들은 종종 backbone network에서 추출된 pyramid 형 feature hierarchy를 기반으로 직접 예측을 수행했습니다. 이런 연구 중 하나인 FPN은 multi-scale feature를 결합하기 위해 top-down pathway를 제안합니다.
또한 더 나은 정확도를 얻기 위해, 더 큰 backbone network를 채택하거나, 입력 이미지 크기를 늘려 baseline detector를 scale up하는 것이 일반적입니다. 이러한 scaling 방법들은 대부분 단일 차원 또는 제한된 scaling 차원에만 초점을 맞춥니다. 본 논문에서 제안하는 compound scaling method는 네트워크의 width, depth, resolution을 공동으로 확장하여 성능을 올렸습니다.
BiFPN.
multi-scale feature fusion은 서로 다른 해상도의 feature들을 aggregate하는 것을 목표로 합니다. formal하게는, multi-scale feature list P_in이 있을 때, 목표는 서로 다른 feature들을 효과적으로 aggregate하여 새로운 feature list P_out을 출력할 수 있는 변환 함수 f를 찾는 것입니다.

위 그림 1.(a)는 기존의 top-down FPN을 보여줍니다. 이는 level 3-7의 input feature P_in을 받습니다. 여기서 P_in^i는 입력 이미지의 1/(2^i) 해상도를 가진 feature level을 나타냅니다. 예를 들어, 입력 해상도가 640 x 640이라면, P_in^3은 80 x 80 해상도를 가진 feature level 3을 나타내며, P_in^7은 5 x 5 해상도를 가진 feature level 7을 나타냅니다. 기존 FPN은 다음과 같은 top-down 방식으로 multi-scale feature들을 aggregation합니다:

여기서 Resize() 는 주로 해상도 매칭을 위한 upsampling 또는 downsampling 연산이며, Conv는 feature 처리를 위한 CNN 연산입니다.
기존의 top-down FPN은 본질적으로 단방향 정보 흐름이라는 한계가 있습니다. 이 문제를 해결하기 위해, PANet은 그림 2.(b)와 같이 추가적인 bottom-up pathway를 추가했습니다. 최근(2020년) NAS-FPN은 더 나은 scale간 특성 네트워크 토폴로지를 찾기 위해 NAS를 채택했으나, 탐색 과정에서 수천 시간의 GPU 시간이 필요하며 발견된 네트워크가 불규칙하여 해석하거나 수정하기 어렵습니다(그림 2.(c) 참조).
이 3가지 네트워크의 성능과 효율성을 연구한 결과, PANet이 FPN과 NAS-FPN보다 더 나은 정확도를 달성하지만(아마도 양방향(td, bu)으로 feature들을 fusion하는 것이 FPN보다 더 나은 성능을 기록한 이유가 되며, NAS 자체의 불안정함 때문에 NAS-FPN의 성능이 낮게 기록되며, GPU 최적화가 잘 안된다), 더 많은 파라미터와 연산 비용이 든다는 것을 발견했습니다. 따라서 모델 효율성을 향상하기 위해, 본 논문은 scale 간 연결에 대해 몇 가지 최적화를 제안합니다:
- 입력 edge가 하나뿐인 노드를 제거합니다. 만약 어떤 노드가 feature fusion 없이 하나의 입력 edge만을 가지고 있다면, 서로 다른 feature를 융합하는 것을 목표로 하는 feature network에 대한 기여도가 낮을 것입니다. 즉, 입력 edge가 하나만 있다면 그 node의 input feature를 강화할 뿐, feature fusion은 전혀 발생하지 않고 계산 낭비가 된다는 의미입니다.
- 동일한 level에 있는 경우 원래 입력에서 출력 노드로 향하는 추가 edge를 더합니다. 이는 많은 비용 추가 없이 더 많은 feature를 fusion하기 위함입니다.
- dottom-up 및 top-down 경로 하나만 갖는 PANet과 달리(dottom-up과 top-down 중 하나만 갖는다는 의미가 아니라, 두 경로 set가 하나라는 뜻), 양방향 경로를 하나의 feature network layer로 취급하고, 동일한 layer를 여러 번 반복합니다. 이는 더 고차원적인 feature fusion을 가능하게 합니다.
서로 다른 해상도의 feature들을 fusion할 때, 일반적인 방법은 먼저 해상도를 동일하게 resize한 다음 단순히 sum하는 것입니다. 그러나 서로 다른 입력 feature들이 서로 다른 해상도에 있기 때문에, output feature에 불균등하게 기여한다는 것을 관찰했습니다. 그리고 이 문제를 해결하기 위해, 각 입력에 추가적인 가중치를 더하고 네트워크가 각 input feature의 중요도를 학습하도록 합니다. 이 아이디어를 바탕으로 세 가지 weighted fusion 접근 방식을 고려합니다:
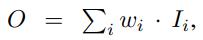
- unbounded fusion: 여기서 w_i는 scalar(feature 당), vector(channel 당) 또는 tensor(pixel 당)가 될 수 있는 학습 가능한 가중치입니다. scalar 가중치가 최소한의 연산 비용으로 다른 접근 방식들과 비슷한 정확도를 달성할 수 있음을 발견했지만, scalar 가중치가 제한되지 않으므로(unbounded), 잠재적으로 학습 불안정성을 유발할 수 있습니다. 따라서 각 가중치의 값 범위를 제한하기 위해 weight normalization을 사용합니다.

- softmax-based fusion: 각 가중치에 softmax를 적용하여 모든 가중치가 0에서 1 사이의 확률 값을 가지도록 정규화하는 것입니다. 이는 각 입력의 중요도를 나타냅니다. 하지만 ablation study에 따르면 추가적인 softmax는 GPU 하드웨어에서 상당한 속도 저하를 초래하기 때문에, 이를 최소화하기 위해 다음의 fast normalized fusion을 제안합니다.

- fast normalized fusion: 여기서 w_i ≥ 0은 각 w_i 뒤에 ReLU를 적용하여 보장하며, epsilon = 0.0001은 수치적 불안정성을 피하기 위한 작은 값입니다. 비슷하게, 각 정규화된 가중치 값은 0과 1 사이로 떨어지지만, 여기에는 softmax 연산이 없으므로 훨씬 더 효율적입니다. ablation study에 따르면 이 fast fusion은 softmax-based fusion과 매우 유사한 동작 및 정확도를 가지면서도, GPU에서 최대 30% 더 빠르게 실행됩니다.
최종 BiFPN은 bi-directional scale 간 연결과 fast normalized fusion을 모두 사용합니다. 그림 2.(d)에 표시된 BiFPN의 level 6에서 융합된 두 가지 feature들은 다음과 같습니다:

여기서 P^td_6은 top-down 경로의 level 6 중간 feature이고, P^out_6은 bottom-up 경로의 level 6 feature입니다. 다른 모든 feature들도 유사한 방식으로 구성되며, 특히 효율성을 더욱 향상하기 위해 feature fusion에 depthwise separable convolution을 사용하고, 각 CNN뒤에 batch normalization과 활성화 함수를 추가합니다.
https://sjkoding.tistory.com/75
Depthwise (Separable) Convolution의 설명 및 Pytorch 예시
- 부제: ConvNeXt이해하기 3편 - Xception에서 제시된 컨셉으로 유명해졌다. 쉽게 이해할 수 있다. 먼저 Depthwise convolution을 알기 전에 일반적인 Convolution 연산을 알아보자. 기본적인 개념으로 Input channel
sjkoding.tistory.com
EfficientDet.

위 그림 3. 은 EfficientDet의 전체 아키텍처를 보여주며, 이는 one-stage detector 패러다임을 따릅니다. ImageNet에서 사전 학습된 EfficientNet을 backbone network로 사용합니다. BiFPN은 feature network 역할을 하며, backbone network로부터 level 3-7 feature들을 받아 botton-up, top-down 양방향 feature fusion을 반복적으로 적용합니다. 이렇게 fusion된 feature들은 class 및 box network에 입력되어 각각 class와 bbox 예측을 생성합니다.
정확도와 효율성을 모두 최적화하는 것을 목표로, EfficientDet 모델을 확장하고자 합니다. 이전 연구들은 주로 더 큰 backbone network를 사용하거나, 더 큰 입력 이미지를 사용하거나, 더 많은 FPN layer를 쌓는 방식으로 확장했습니다. 하지만 이러한 방법들은 단일 또는 제한된 스케일링 차원에만 초점을 맞추기 때문에 대개 비효율적입니다(기존의 연구들은 깊이, 너비, 해상도를 동시에 최적화하기 너무 어려워서(경우의 수가 너무 많아서), 하나의 측면만 확장했었습니다. 하지만 이렇게 한 가지 요소만 키우면 성능 향상 폭은 줄어드는데 계산량만 폭증할 수 있습니다). 따라서 객체 탐지를 위한 복합 스케일링 방법을 제안합니다. 이는 단순한 복합 계수(compound coefficient) φ를 사용하여 backbone, BiFPN, class/box network, 해상도의 모든 차원을 동시에 확장합니다(확장 계수는 논문에 자세히 나와있음).
Experiments and Ablation Study.
(...)