
https://arxiv.org/abs/2505.06708
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Gating mechanisms have been widely utilized, from early models like LSTMs and Highway Networks to recent state space models, linear attention, and also softmax attention. Yet, existing literature rarely examines the specific effects of gating. In this work
arxiv.org
Abstract.
Gating mechanism은 LSTM과 같은 초기 모델부터 최근의 state space model, linear attention 그리고 softmax attention에 이르기까지 널리 활용되어 왔습니다. 그러나 기존의 연구에서는 gating의 구체적인 효과에 대해서 연구하지는 않았습니다. 따라서 해당 연구에서는 gating이 추가된 softmax attention들의 변형들을 체계적으로 조사합니다. 이 연구에서 SDPA(Scaled Dot-Product Attention) 뒤에 head별 sigmoid gate를 적용하는 간단한 수정만으로도 성능이 일관되게 향상됨을 증명합니다. 또한 이러한 수정은 학습 안정성을 높이고, 더 큰 학습률을 허용하며, 스케일링 특징을 개선합니다.
다양한 gating 위치와 연산 변형들을 비교함으로써, 이러한 효과가 1) softmax attention의 low-rank 매핑에 비선형성을 도입하는 것과 2) query에 의존하는 sparse gating score를 적용하여 SDPA의 출력을 조절하는 것 때문임을 보여줍니다. 특히, 이 sparse gating mechanism이 attention sink 현상을 완화하고 긴 context에 대해 성능을 향상시킨다는 점을 보여줍니다.
Introduction.
gating mechanism은 신경망 분야에서 잘 확립된 개념입니다. LSTM, GRU와 같은 초기 아키텍처들은 time steps이나 layer 간의 정보 흐름을 제어하고 gradient 전파를 개선하기 위해 gating을 사용했습니다. 이러한 원칙은 현대의 아키텍처에서도 지속되며, SSM과 Attention mechanism을 포함한 최근의 sequence modeling 연구들은 token-mixer 구성 요소의 출력을 조절하기 위해 gating을 사용합니다.
이런 광범위한 사용과 경험적인 성공에도 불구하고, gating mechanism의 기능과 영향력은 초기 직관을 넘어서는 수준까지 탐구되지 않았습니다. 이런 불충분한 이해는 gating의 진정한 기여를 평가하는 것을 방해하며, 특히 다른 아키텍처 요인들과 혼재되어 있을 때 더욱 그렇습니다. 예를 들어, Switch Heads(Csordas et al., 2024a; b)는 top-k개의 attention head experts를 선택하기 위해 sigmoid gating을 사용했지만, 이를 단일 expert로 축소하여 gate가 단순히 값 출력을 조절하기만 하는 경우에도 상당한 성능 이득이 지속된다는 것을 발견했습니다. 이는 gating 자체가 routing mechanism과 별개로 상당한 내재적 가치를 제공함을 시사합니다.

해당 연구에서는 서로 다른 위치에 gating을 도입합니다(그림 1. 왼쪽):
- Query(G4), Key(G3), Value projection(G2) 후
- SDPA 출력 후(G1)
- 최종 dense 출력 레이어 후(G5)
또한 elementwise 및 headwise, head-specific 및 head-shared, additive 및 multiplicative 형태들을 포함하는 다양한 gating의 변형들에 대해 실험합니다. 이 실험을 통해 저자들은 다음과 같은 요소들을 발견했습니다:
- SDPA 출력에 head별 gating을 적용하는 것이 가장 유의미한 성능 향상을 가져온다.
- SDPA 출력 gating은 loss spikes를 거의 제거하여 학습 안정성을 개선하고, 더 큰 학습률을 사용할 수 있게 하며, 모델의 확장성을 개선한다.
해당 논문에서는 이에 대한 요인으로 다음의 두 가지를 발견합니다:
- 비선형성(non-linearity): 두 개의 연속적인 선형 층인 W_V(value projection matrix)와 W_O(dense projection matrix)는 하나의 row-lank linear projection으로 다시 쓸 수 있습니다. 따라서 위치 G1 또는 G2에 gating을 통해 비선형성을 도입하면 이 row-lank linear projection의 표현력을 증가시킬 수 있습니다.
- 희소성(sparsity): 비선형 gating 변형들이 일관되게 성능을 향상시키긴 하지만, 그 이득의 폭은 다양했습니다. 이에 gating score의 뚜렷한 희소성(sparsity)이 또 다른 결정적인 요인임을 밝혀냈으며, 이는 SDPA 출력에 입력 의존적(input-dependent) 희소성을 도입합니다. 게다가 sparse gating은 attention sink 현상을 제거합니다. 이는 초기 토큰들이 attention 점수를 불균형하게 독차지하는 현상으로, softmax 정규화로 인한 잉여 attention의 축적으로 설명할 수 있습니다. 경험적으로, SDPA 출력에 query dependent sparse gating이 적용되었을 때, dense 모델과 MoE 모델 모두에서 attention sink가 발생하지 않는 것을 검증했습니다.
요약하면, 이 연구는 표준 attention layer 내 gating이 모델의 성능과 행동 방식에 미치는 영향을 연구한 것이며, gating 변형들을 평가함으로써, 그것들이 비선형성과 희소성을 도입하고 attention sink를 제거하는 능력이 있음을 밝혀냈습니다.
Gated-Attention Layer.
입력 X가 주어졌을 때, transformer의 attention layer 연산은 다음의 네 단계로 나눌 수 있습니다:
1) QKV Linear Projection: 입력 X는 학습된 가중치 행렬 W_Q, W_K, W_V 를 사용하여 query Q, key K, value V 로 선형 변환됩니다:
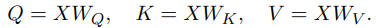
2) Scaled Product Dot-Product Attention(SDPA): query와 key 사이의 attention 점수를 계산한 뒤, softmax 정규화를 수행합니다. 출력들은 value들의 가중 합(weighted sum)입니다:

여기서 ()안에 있는 값들은 scaled 내적 유사도 행렬을 나타내며, softmax는 attention 가중치가 음수가 아니고 각 행의 합이 1이 되도록 보장합니다.
3) Multi-head Concatenation: multi-head attention에서는 위 과정이 h개의 head에 대해 병렬로 반복되며, 각 head는 고유한 projection matrices들을 갖습니다. 모든 head의 출력은 하나로 연결(concatenation)됩니다:

4) Final Output Layer: 연결된 SDPA 출력은 출력 layer W_O를 통과합니다:

gating mechanism은 다음과 같이 공식화될 수 있습니다:
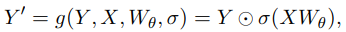
Y는 조절(modulate)될 입력, X는 gating score를 계산하는 데 사용되는 또 다른 입력, W_θ는 gate의 학습 가능한 파라미터, σ는 활성화 함수(예: sigmoid), Y'은 gating된 출력입니다. gating score σ()는 Y의 feature들을 선택적으로 보존하거나 지움으로써 Y로부터의 정보 흐름을 제어하는 dynamic filter 역할을 효과적으로 수행합니다.
연구는 아래의 핵심 측면에 중점을 둡니다:
- Position: 그림1. 에 묘사된 바와 같이 서로 다른 위치에 gating을 적용하는 효과를 연구합니다:
- Q, K, V projection 직후 (그림1. 의 G2, G3, G4 위치에 해당)
- SDPA 출력 직후 (G1)
- 최종 연결된 multi-head attention 출력 직후 (G5)
- Granularity: gating 점수에 대해 두 가지 수준의 밀도를 고려합니다:
- headwise: 단일 scalar gating score가 attention head의 전체 출력을 조절합니다.
- elementwise: gating socre가 Y와 동일한 차원을 갖는 벡터이며, 이를 통해 차원별로 fine-grained 조절이 가능합니다.
- head specific or shared: attention의 multi-head 특성을 감안하여 다음을 추가로 고려합니다:
- head-specific: 각 attention head가 자신만의 고유한 gating score를 가져, 각 head에 대한 독립적인 조절이 가능합니다.
- head-shared: W_θ와 gating score가 모든 heads 간에 공유됩니다.
- multiplicative or additive: gating score를 Y에 적용하는 방식에 대해 다음을 고려합니다:
- multiplicative gating: gating된 출력 Y'는 Y'=Y · σ() 로 계산됩니다.
- addtive gating: Y'=Y + σ()
- activation function: 주로 두 가지 일반적인 활성화 함수인 SiLU와 sigmoid를 고려합니다. SiLU는 출력 범위가 제한되지 않으므로 addtive gating에만 사용하며, sigmoid는 [0,1] 범위의 점수를 제공합니다. 추가로, gating 효과의 근본 mechanism을 분석하기 위해 Identity mapping(항등 매핑)이나 RMSNorm도 고려합니다.
2026.01.01 - [[CoIn]/[Others]] - [CoIn] 논문 리뷰 | Root Mean Square Layer Normalization (RMSNorm)
[CoIn] 논문 리뷰 | Root Mean Square Layer Normalization (RMSNorm)
https://arxiv.org/abs/1910.07467 Root Mean Square Layer NormalizationLayer normalization (LayerNorm) has been successfully applied to various deep neural networks to help stabilize training and boost model convergence because of its capability in handling
hw-hk.tistory.com
Note: RMS를 gating의 일종으로 해석할 수도 있습니다. gating이란 입력(X)에다가 0~1 사이의 값을 곱해서 신호의 세기를 조절하는 것을말합니다. RMSNorm의 수식은 이와 매우 비슷한 구조를 갖습니다:

또한 곱해주는 값이 입력 의존적이며, X를 제곱하고 루트를 씌우는 과정에서 비선형성이 도입됩니다.
Experiments.
Gated Attention for MoE models.
먼저 MoE-15A2B 모델에서 다양한 gate attention layer의 결과를 비교합니다:

위에 있는 표1. 을 통해서 다음을 관찰할 수 있습니다:
- SDPA 및 value 출력 gating이 효과적입니다. SDPA 출력(G1) 또는 value map(G2)에 gate를 삽입하는 것이 가장 효과적이며, 다른 변형보다 낮은 PPL(perplexity)과 더 나은 전반적인 벤치마크 성능을 달성합니다.
- head-specific gating이 중요합니다. G1과 G2에 headwise gating을 적용하는 것은 매우 적은 추가 파라미터를 도입하지만 상당한 개선을 가져옵니다. 서로 다른 attention head간에 gating 점수를 공유하는 경우, 벤치마크 개선 폭은 헤드별 게이팅으로 달성한 것보다 작습니다. 이는 서로 다른 attention head에 대해 서로 다른 gating score를 적용하는 것의 중요성을 강조합니다.
- multiplicative gating이 선호됩니다. additive SDPA gating은 baseline보다는 개선을 보이지만 multiplicative gating보다는 성능이 떨어집니다.
- sigmoid activation이 더 낫습니다. 가장 효과적인 gating 구성(5)에서 활성화 함수를 SiLU로 교체(15)하면 개선 폭이 줄어듭니다.
Augmenting Attention Layer with Gating Mechanisms.
SDPA 출력 sigmoid gating을 검증하기 위해 dense 모델에 대한 실험 또한 수행합니다. 이전 연구들은 네트워크 깊이 증가, 큰 학습률, 큰 배치 크기가 모델 성능과 분산 학습 효율성을 크게 향상시킬 수 있지만, 종종 학습 불안정성을 초래한다는 것을 밝혀냈습니다. 하지만, gating mechanism을 적용하면 학습 중 loss spikes 발생이 명백히 감소함을 관찰했으며(Chowdhery et al., 2023; Takase et al., 2023), 이는 gating이 학습 안정성을 향상시키는 유망한 역할을 함을 시사합니다. 이에 따라, 해당 연구에서는 gating의 안정화 효과를 더 조사하기 위해 layer 수 증가, 더 높은 최대 학습률, 더 큰 배치 크기로 실험을 진행합니다:

표 2.는 다음을 보여줍니다:
- gating은 다양한 설정 전반에 걸쳐서 효과적입니다. 다양한 모델 구성((1) vs. (2), (5) vs. (8)) , 학습 데이터((3) vs. (4)) 및 하이퍼파라미터((11) vs. (13))에 걸쳐 SDPA 출력 gating을 적용하는 것은 일관되게 이점을 제공합니다.
- gating은 안정성을 개선하고 용이하게 합니다. 3.5T 토큰 설정에서, gating은 학습 안정성을 개선하여 loss spike를 크게 줄입니다(그림 1. 오른쪽). 최대 LR을 늘릴 때 baseline은 수렴 문제에 직면하는 반면((6), (12)), gating이 있는 모델에서 최대 LR을 늘리면 눈에 띄는 개선이 나타납니다.
요약하면, SDPA element-wise gating이 attention mechanism을 증강하는 가장 효과적인 방법임을 밝혀냈으며, 이 방법을 dense transformer에 적용하면 게이트가 더 큰 배치 크기와 학습률로도 안정적인 학습을 가능하게 하여 성능 향상으로 이어짐을 추가로 입증했습니다.
Analysis: Non-Linearity, Sparsity and Atteniton-Sink-Free.
Non-linearity Improves the Expressiveness of Low-Rank Mapping in Attention.
SDPA 출력에 group norm을 활용한 이전 연구들(Sun et al., 2023; Ye et al., 2024)에서 영감을 받아, concatenation 전에 각 attention heads의 출력에 독립적으로 RMSNorm을 적용했습니다:
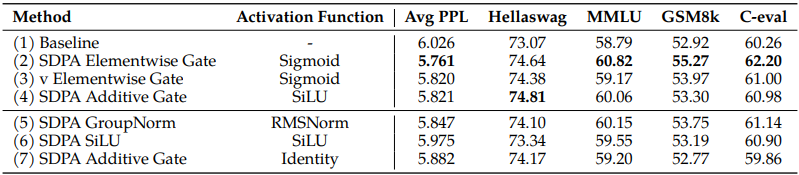
표 3. 의 (5)에서 볼 수 있듯이, 추가 파라미터를 거의 도입하지 않는 RMSNorm을 적용하는 것만으로도 PPL이 유의미하게 감소했습니다. multi-head attention attention에서, k번째 head에 해당하는 i번째 토큰의 출력은 다음과 같이 표현될 수 있습니다:

위 식을 통해 W_V와 W_O를 모든 X_j에 적용되는 하나의 low-rank linear projection으로 병합할 수 있습니다. GQA(Grouped Query Attention)를 사용하면 동일 그룹 내 헤드들이 W_V를 공유하므로 표현력이 더욱 감소합니다. 두 linear mapping 사이에 비선형성을 추가하면 표현력을 향상시킬 수 있기 때문에, low-rank를 완화하기 위해 두 가지 방법을 고려합니다:

G2위치에 gating을 추가하는 것은 위의 식에 해당하며, G1 위치에 gating이나 group norm을 추가하는 것은 두 번째 식에 해당합니다. 위 식에 따르면, W_O 이후인 G5에 gating이나 정규화를 추가하는 것은 W_V와 W_O 사이의 비선형성 결핍을 해결하지 못하기 때문에 효과가 없다는 것을 설명해줍니다.
G1에서 additive gating의 경우, gating 출력이 SiLU를 통과하므로 약간의 비선형성을 도입하게 되며, 이는 multiplicative gating보다는 작지만 성능 향상이 관찰되는 이유를 설명합니다. 이러한 통찰을 바탕으로 두 가지 추가 실험을 진행합니다:
- 추가 파라미터 도입 없이 G1 위치에 SiLU만 추가(표3. (6)). 이런 간단한 수정은 PPL을 소폭 감소시키지만, 대부분의 벤치마크 점수는 변하지 않습니다.
- additive gating에서 SiLU를 제거하여 gating 추 X_j의 출력이 G1 위치에서 직접 더해지도록 함(표3. (7)). 이는 additive gating의 이득을 더욱 감소시킵니다.
정리하면, 효과적인 gating 변형과 관련된 성능 향상은 W_V와 W_O 사이에 비선형성이 도입되었기 때문일 가능성이 있으며, G1과 G2 위치 모두에 gating을 적용하여 비선형성을 도입할 수 있지만, 이 두 적용 방식은 서로 다른 성능 향상을 보입니다.
Gating Inroduces Input-Dependent Sparsity.
G2 및 G1 위치에 gating된 모델을 분석하여, 모든 layer에 대한 평균 gating score를 표 4.에 제시합니다:
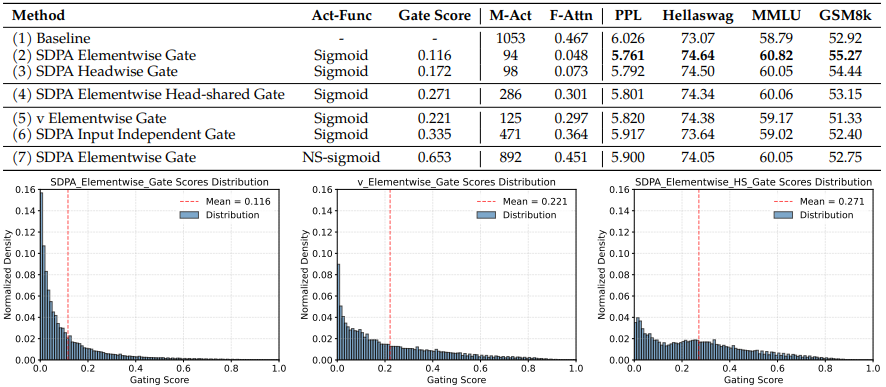
주요 관찰 내용은 다음과 같습니다:
- 효과적인 gating score는 sparse합니다. SDPA 출력 gating은 가장 낮은 평균 gating 점수를 갖습니다. 또한 SDPA 출력 gating 점수 분포는 0 근처에 높게 집중되어 있어 상당한 희소성을 나타내며, 이는 우수한 성능과 일치합니다. **sparsification이 성능 향상과 직접적인 연관?**
- head-specific sparsity는 중요합니다. attention head 간에 공유된 gating 점수를 강제하면 전체 gating 점수가 증가하고 성능 이득이 감소합니다. 이러한 관찰 결과는 개별 attention head가 입력의 서로 다른 측면을 포착한다는 이전 연구 결과(Voita et al., 2019; Wang et al., 2021; Olsson et al., 2022; Wang et al., 2023)와 일치합니다.
- query-dependency가 중요합니다. G2의 점수는 SDPA 출력 gating인 G1보다 높으며, 성능은 더 떨어집니다. 이는 gating 점수의 sparsity가 key나 value에 의해서 결정되는 것보다 query에 의존적일 때 더 효과적임을 시사합니다. SDPA 출력 gating score는 현재 query에 해당하는 hidden state로부터 유도되는 반면, value gating score는 과거의 key 및 value와 연관된 hidden state로부터 유도됩니다. 이는 gating 점수의 sparsity가 query에 대해 관련 없는 문맥 정보를 필터링해 낼 수 있음을 의미합니다.
- less sparse gating is worse. gating score sparsity의 중요성을 추가로 검증하기 위해, gating 공식에서 희소성을 줄였습니다. 구체적으로 sigmoid 함수를 수정된 희소하지 않은(NS, Non-Sparse) 버전으로 대체합니다:

- 이는 gating 점수를 [0.5,1] 사이로 제한하며, 이는 비선형성은 도입하되 gating 점수의 sparsity는 제거됩니다. 표 4. (7)에서 볼 수 있듯, NS-sigmoid gating의 이득은 SDPA 출력 sigmoid gating보다 떨어집니다.
Note: sparsification은 gate가 '이 정보는 지금 질문(쿼리)랑 상관없어!' 라고 판단하면서 점수를 아예 0에 가깝게 만들어버릴 수 있습니다. 이렇게 되면 불필요한 문맥(context) 정보가 걸러지고, 정말 중요한 핵심 정보(signal)만 남아서 다음 레이어로 전달됩니다. 모델 입장에서는 훨씬 선명하고 깨끗한 정보를 처리하게 되니 정답을 맞출 확률이 올라갑니다. 한편, softmax가 sparsity에 더 좋다고 말하기도 합니다:
[CoIn] 논문 리뷰 | Sliding Window Attention Training for Efficient Large Language Models (Fu et al., 2025)
https://arxiv.org/abs/2502.18845 Sliding Window Attention Training for Efficient Large Language ModelsRecent advances in transformer-based Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks. However, their quadratic
hw-hk.tistory.com
SDPA Output Gating Reduces Attention-Sink.
gating이 입력 의존적인(input-dependent) 방식으로 SDPA 출력에 희소성을 도입한다는 관찰에 기반하여, 이 메커니즘이 현재 query 토큰과 관련 없는 문맥을 걸러내어(filter out), 결과적으로 attention sink를 완화할 수 있다고 가설을 세웁니다. 이를 검증하기 위해, attention score의 분포와 첫 번째 토큰에 할당된 attention score의 비율을 분석합니다:
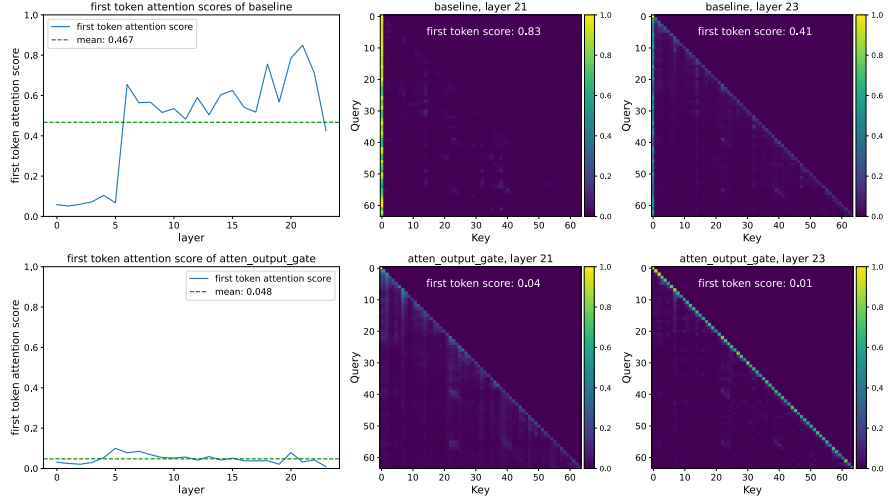
이를 통해 다음을 관찰할 수 있습니다:
- SDPA 출력(G1)에서의 head-wise 및 element-wise query dependent sigmoid gating은 첫 번째 토큰에 할당된 attention score를 크게 줄입니다.
- heads간의 공유된 gating 점수를 강제하거나 value projection 후(G2) 에만 gating을 적용하는 것은 massive activation을 줄여주기는 하지만, 첫 번째 토큰에 대한 attention score를 줄이지는 못합니다. 이는 head-specific gating의 중요성을 환기하며, massive activation이 attention sink의 필수 전제 조건이 아님을 시사합니다.
- gating의 입력 의존성을 줄이거나, sparsity를 줄이기 위해 NS-sigmoid를 사용하는 것은 거대 활성화와 attention sink를 모두 심화시킵니다.
종합하면, 이러한 관찰들은 SDPA 출력의 input dependency, head-specific gating이 상당한 sparsity를 도입하여 attention sink를 완화함을 나타냅니다. 나아가, SDPA 출력의 sparsity는 모델 내의 massive activation을 줄이며, sparsity가 늘어날수록 activation을 줄어듭니다.
Note: massive activation이란 신경망의 뉴런들이 뱉어내는 출력값(activation)이 비정상적으로 커지는 현상을 말합니다. 이는 주로 FFN을 통과하며 값이 커지고, 이것이 residual connection을 타고 다음 레이어로 계속 전해지면서 점점 커지게 됩니다. 일반적으로 LLM은 학습 속도와 메모리 효율을 위해 BF16이나 FP16과 같은 low precision format을 사용하는데, 여기에서 표현할 수 있는 숫자의 정밀도나 범위의 한계로 인해 학습이 불안정해지는 것입니다.
SDPA Output Gating Facilitates Context Length Extension.
Attention-sink-free 패턴에 기반하여, long-context 설정에서 SDPA gating 효과를 평가합니다:
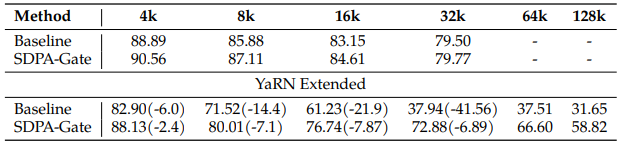
이를 통해 다음을 관찰했습니다:
- 32k 설정 하에서, gating이 있는 모델은 baseline을 약간 능가합니다. 이는 학습 길이 내에서는 attention-sink 현상이 모델의 long context 성능을 해치지 않을 수 있음을 시사합니다.
- YaRN을 사용해 context 길이를 128k로 확장했을 때, baseline과 gating 모델 모두 원래의 32k 범위 내에서 성능 하락을 겪습니다.
- 64k와 128k context length에서, gating attention 모델은 baseline을 상당히 능가합니다
이러한 관찰로부터, gating 추가가 모델이 context length 확장에 적응하는 데 도움을 준다고 세울 수 있으며, baseline 모델들이 attention score 분포를 조절하기 위해 attention-sink에 의존한다는 것입니다.