
https://arxiv.org/abs/2409.04431
Theory, Analysis, and Best Practices for Sigmoid Self-Attention
Attention is a key part of the transformer architecture. It is a sequence-to-sequence mapping that transforms each sequence element into a weighted sum of values. The weights are typically obtained as the softmax of dot products between keys and queries. R
arxiv.org
Abstract.
본 논문에서는 attention mechanism에서의 activation function의 선택에 대해서 탐구합니다. 거의 모든 transformer 모델에서 softmax가 기본 선택지이지만, 본 논문에서는 element-wise sigmoid attention 이 강력한 대안임을 보여줍니다. 본 논문에서는 sigmoid attention에 대한 이론적 분석을 제공하며 이것이 universal function approximator(보편 함수 근사기)임을 증명하고 softmax에는 없는 regualrity 속성을 가지고 있음을 증명합니다.
Note: 추후 자세한 설명이 나오겠지만 미리 설명하자면, deep learning에서 Universal function approximator란 그 모델의 크기만 충분하다면, 어떤 함수든 오차 없이 거의 똑같이 그려낼 수 있다는 수학적 보증입니다. 기존에는 softmax를 써야만 transformer가 똑똑하게 작동한다는 믿음이 있었지만, 이는 sigmoid를 써도 softmax만큼이나 복잡한 문제를 풀 수 있다는 뜻입니다. 한편, regularity는 수학적으로 Lipschitz continuity와 관련있는데, 쉽게 말해 "입력이 조금 변했을 때, 출력이 얼마나 안정적으로 변하는가?" 에 대한 성질이며, 본 논문에서는 sigmoid가 softmax보다 더 안정적이라고 주장합니다.
경험적으로 language modeling, image classification, and speech recognition을 포함한 다양한 작업에서 sigmoid attention이 softmax attention보다 성능이 우수함을 발견했습니다. 더 나아가, sigmoid attention이 분배 함수(partition function, softmax의 분모 부분) 계산을 필요로 하지 않기 때문에 softmax attention보다 더 효율적입니다. 마지막으로, initialization 및 normalization 체계를 포함하여 sigmoid attention으로 모델을 학습시키기 위한 일련의 모범 사례를 제공합니다.
Introduction.
Transformer architecture는 sequence modeling의 de facto standard입니다. 그 핵심 구성 요인 self-attention mechanism은 모델이 입력 sequence 내의 서로 다른 요소들의 중요도에 가중치를 부여할 수 있게 해줍니다. 구체적으로, 표준 attention mechanism은 attention score를 정규화하기 위해 softmax 함수를 사용하며, 이는 점수들의 합이 1이 되도록 보장합니다. 이러한 확률적 해석은 직관적이기는 하지만, attention score들 사이의 coupling(결합, 연관)을 유발합니다. 즉, 한 요소의 가중치를 증가시키면 필연적으로 다른 요소들의 가중치는 감소하게 됩니다.
본 연구에서는 softmax attention의 지배적인 위치에 도전하고 그 대안인 sigmoid attention의 특성을 조사합니다. sigmoid attention에서는 각 attention score가 sequence 전체에 걸친 정규화 제약(합이 1이 되는 제약)을 강제하지 않고, sigmoid 함수를 사용하여 독립적으로 계산됩니다. 이러한 attention score의 decoupling은 모델이 여러 요소에 동시에 주의(attend)를 기울이거나, 필요할 경우 sequence 전체를 무시할 수 있게 해줍니다. 본 논문의 contribution은 다음과 같습니다:
- sigmoid attention에 대한 이론적 토대를 제공합니다. 본 논문에서는 sigmoid attention을 사용하는 transformer가 연속적인 sequence-to-sequence 함수의 universal function approximator임을 증명합니다. 또한 attention map의 규칙성을 분석하고 sigmoid attention이 입력에 대해 Lipschitz continuous임을 보여주는데, 이는 softmax attention이 정규화 항(분모) 때문에 갖지 못하는 속성입니다.
- 본 논문에서는 다양한 도메인에 걸쳐 FLASHATTENTION2(Dao et al., 2022; Dao, 2023)를 확장하여, sigmoid attention에 대한 광범위한 경험적 평가를 수행합니다. sigmoid attention이 language modeling(WikiText-103, One Billion Word), image classification(ImageNet), speech recognition(LibriSpeech)에 대한 표준 benchmark에서 softmax attention과 대등하거나 더 뛰어난 성능을 일관되게 보여줌을 확인했습니다.
Sigmoid Attention.
X를 n개의 vector로 구성된 입력 sequence라고 하고, 여기서 각 vector의 차원은 d라고 하면, 세 개의 학습 가능한 가중치 행렬 W_q, W_k, W_v를 정의하여, 이들은 다음과 같이 Q, K, V를 계산하는데 사용합니다:

Self-attention(Bahdanau et al., 2015; Vaswani et al., 2017)은 다음과 같이 간결하게 작성될 수 있습니다:

여기서 softmax 함수는 입력 행렬의 각 행(row)를 정규화합니다. 이때 softmax를 다음과 같이 교체합니다:
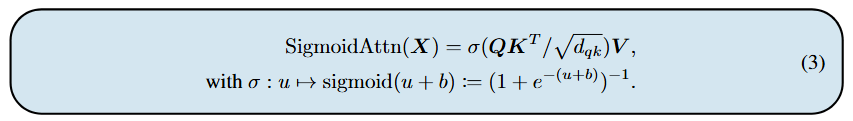
여기서 σ는 입력 행렬에 element-wise로 적용되며, 활성화 함수 σ는 하이퍼파라미터 b를 갖습니다. Appendix E에서 b = -log(n)이라는 결과를 낳는, order-optimal의 bias term을 선택하는 직관적인 방법을 논의할 것이며, 이러한 b의 선택은 SigmoidAttn이 어떠한 sequence 길이에서도 동작할 수 있게 해줍니다. 실제로 (y_1, ..., y_n)을 SigmoidAttn(x)의 출력 sequence라고 하면, 다음과 같은 식을 얻을 수 있습니다:
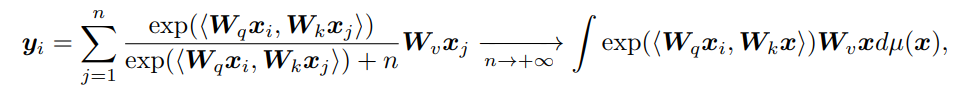
위 식을 통해 sequence length n이 무한 길이 극한에서도 유의미한 값을 가질 수 있음을 알 수 있습니다.
Note: 위 식을 풀어서 해설하면 다음과 같습니다. 우선 sigmoid(z) = exp(z)/(1+exp(z))이며, Appendix E에서 논의한 bias = -log(n)을 대입하면, sigmoid(z-log(n)) = exp(z-log(n))/(1+exp(z-log(n)))입니다. 지수 법칙에 의해 풀어쓰면, 위 식은 (exp(z)/n)/(1+exp(z)/n)가 되며, 분모와 분자에 n을 곱해주면 좌변의 식이 나옵니다.
Note: 한편, sigmoid attention은 softmax와 달리 Σ=1이라는 제약이 없으므로, sequence length가 늘어나면 V의 가중합이 매우 커지게 됩니다. 따라서 sequence length n에 대한 제약이 필요하며, 이를 -log(n)을 통해 달성할 수 있습니다. 이는 n → ∞로 보냈을 때 좌변이 어떻게 변하는 지를 보면 알 수 있습니다. 분모에서 n → ∞로 보내면, exp(..)는 상대적으로 매우 작기 때문에, 분모는 n만 남게 되어, Σexp(..)/n이 됩니다. 이때 Σ와 1/n을 결합해 ∫로 바꿔주면 우변이 되며, 이는 n이 무한대여도(sequence length가 길어져도) n개의 단어에 대해 각각 점수를 매겨 더한다는 개념이 유지됨을 알 수 있습니다.
multi-head 버전은 다음과 같이 구할 수 있습니다:
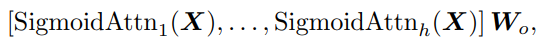
Theoretical Properties of Sigmoid Attention.
Are Transformers with Sigmoid Attention Universal Approximators?
Yun et al. 2020은 고전적인 transformer가 sequence-to-sequence 함수를 임의의 정밀도까지 근사할 수 있음을 증명했으며, 이러한 속성을 Universal Approximation Property, UAP라고 합니다. UAP는 모델 아키텍처의 일반화 가능성과 표현 능력에 대한 증명을 제공하기 때문에 매우 중요한 특성이며, SigmoidAttn은 transformer 아키텍처를 변형하는 것이므로, 이러한 변형이 모델의 표현 능력에 악영향을 미치지 않으며 UAP가 그대로 유지된다는 것을 이론적으로 보장하는 것이 매우 중요합니다.
Note: UAP는 충분한 파라미터만 주어진다면, 이 모델은 세상에 존재하는 어떤 복잡한 규칙(함수)이든 오차 없이 똑같이 구현할 수 있다는 수학적 증명입니다. UAP는 이 모델이 태생적인 한계가 없다는 것을 보장해줍니다. 과거 1980년대에 단순한 MLP는 UAP를 가진다는 것이 증명되었지만, self-attention, softmax, residual connection 등의 복잡한 구조를 갖는 transformer도 UAP를 갖는지 의문이 생겼습니다. Yun et al. (2020)은 transformer(softmax를 사용하는 transformer)도 head와 layer 수만 충분하다면 모든 seq-to-seq 함수를 완벽하게 근사할 수 있다는 것을 수학적으로 증명한 연구입니다.
다음은 Theorem 3.1 (UAP for SigmoidAttn)입니다:

block set T_σ^h,d,r은 각각 T는 Transformer 네트워크들의 집합을, σ는 softmax 대신 sigmoid attention을 사용한다는 것을, h, d, r은 각각 attention head의 수, 각 head의 차원 크기, FFN의 은닉층 크기를 의미합니다. 이때, 풀고자 하는 완벽한 정답 함수를 f라고 했을 때, 두 조건을 만족해야 합니다:
- compact support Ω: 이는 쉽게 설명하면, 입력 데이터의 값이 무한대까지 가지 않고, 일정한 한계선 안에 있어야 함을 의미합니다. 예를 들어, 이미지 픽셀 값은 0-255사이의 값이라는 조건입니다.
- permutation-equivariant: transformer의 가장 큰 특징으로, 입력 데이터의 순서를 섞으면(permutatioon), 출력 결과물도 정확히 그 섞인 순서대로 똑같이 섞여서 나와야 한다(equivariant)는 뜻입니다.
이때 임의의 아주 작은 오차 ε에 대해서 T_σ^4,1,4(sigmoid를 쓰는 # head = 4, head dim = 1, FFN dim = 4인 Transformer layer만 사용해도, layer만 충분하다면 오차 내의 함수 g(x)를 만들어낼 수 있다는 것입니다.
이는 고전적인 transformer의 UAP를 보여주는 Yun et al. (2020)과 완전히 대응되며, 원본 증명의 개요는 Appendix C에 제공됩니다.
Yun et al. (2020)에서 contextual mapping은 개별 transformer block을 수정하여 조립됩니다. 즉, 각 block은 특정 입력 토큰에 반응하도록 조정되며, 이러한 block들의 sequence를 쌓음으로써, transformer는 accumulator로서 동작하며, 주어진 입력 token sequence를 고유한 global index로 mapping할 수 있습니다. 이러한 결과는 selective shift layer(Yun et al., 2020, App. B.5)를 통해 달성됩니다:

Note: contextual mapping이란 무엇일까요? transformer attention은 기본적으로 pairwise comparisons만 합니다. 즉, 한 번에 두 단어(예: '나'와 '밥')의 관계만 봅니다. 하지만 제대로 번역이나 추론을 하려면, 모델은 문장 전체의 큰 그림(global context)를 이해해야 합니다. 이를 위해, transformer는 여러 층을 겹겹이 쌓아 올립니다. 아래층에서 단어끼리 조금씩 정보를 교환하고, 위칭으로 올라갈수록 각 단어 안에 '이 문장 전체가 대충 어떤 내용이다'라는 전역 정보를 요약해서 저장하게 됩니다. 즉, 여러번의 pairwise comparisons를 통해 global한 정보를 얻을 수 있는 것입니다.
Note: 이 능력(contextual mapping)을 증명하기 위해, 임의의 layer를 정의합니다. 이는 selective shift layer로, 특정 조건을 만족하는 단어에게만 문장 전체의 요약본을 주입하는 함수입니다. 문장 속 i번째 단어의 특정 값이 임의의 기준(b와 b'사이)에 딱 들어맞을 때만 작동하며, 문장 전체를 뒤져서 가장 큰 값(max)에서 가장 작은 값(min)을 뺀 값을 해당 단어에 줍니다(이는 전체 문장의 정보가 필요한 동작입니다). 한편, softmax는 winner-takes-all 성질이 있어서 max를 찾는 데 아주 탁월합니다. 즉, softmax를 사용하면 위 동작을 쉽게 할 수 있으며, 이는 전체 문장의 정보가 필요한 동작이므로, softmax는 contextual mapping 능력이 있다는 것을 Yun et al. (2020)에서 증명합니다.
비록 SigmoidAttn이 위 selective shift layer를 직접적으로 근사할 수는 없지만, 본 논문에서의 accumulator 정의는 다음과 같은 equivalent selective shift operation에 의존합니다:

Note: Sigmoid Attn은 score를 각 단어들마다 계산하므로 contextual mapping능력이 떨어집니다. 즉, Yun et al. (2020)에서 사용한 selective shift layer에서의 max나 min을 바로 찾을 수 없습니다. 따라서 새로운 식을 발명했으며, 이는 임의의 기준에 딱 들어맞을 때 동작하며, max - min을 구하는 대신, 문장 전체에서 값이 b'보다 큰 애들만 싹 다 찾아서 더해버린 값을 해당 단어에 줍니다. 이 동작 또한 max - min과 마찬가지로 전역적인 정보가 필요하며, sigmoid는 각 token의 값이 b'보다 큰지 작은지 파악할 수 있기 때문에, sigmoid또한 contextual mapping 능력이 있다고 증명할 수 있습니다.
본 논문에서는 Appendix C에 증명되었으며, 이를 통해 SigmoidAttn에 대해서도 UAP가 성립함을 입증합니다. 본 논문의 증명은 대체로 Yun et al. (2020)의 증명과 동등하지만, 두 가지 차이점이 존재합니다. 새롭게 정의한 selective shift operation을 근사하기 위해 최소 4개의 head를 가진 SigmoidAttn과 query 및 key 정의 모두 포함된 shift 항이 필요합니다. 이와 대조적으로, SoftmaxAttn은 selective shift operation을 근사하기 위해 최소 2개의 head가 필요하며, shift 항은 오직 query 정의에만 들어갑니다. 그러나 이것은 증명을 위한 이론적인 요구사항일 뿐이며 실제 성능에는 영향을 미치지 않습니다.
Regularity of Sigmoid Attention.
신경망의 다른 layer들과 마찬가지로, SigmoidAttn의 regularity를 연구하는 것은 해당 네트워크의 robustness와 최적화의 용이성에 대한 통찰을 제공하므로 중요합니다. layer function φ의 regularity를 정량화하는 가장 표준적인 방법은 어떤 집합 χ에 대해 Lipschitz 상수를 계산하는 것입니다. 즉, 모든 X, Y ∈ χ에 대해 ||φ(X) - φ(Y)|| ≤ C||X - Y||를 만족하는 상수 C > 0을 찾는 것이며, 여기서 ||·||는 frobenius norm을 뜻합니다. local Lipschitz constant는 χ에서 φ의 jacobian의 spectral norm입니다. 이 둘은 서로 연관되어 있습니다: 집합 χ에 대한 φ의 Lipschitz constant는 모든 X ∈ χ에 대한 가장 큰 local Lipschitz constant입니다.
Note: 차근 차근 설명해보겠습니다. 우선 layer function φ는 SigmoidAttn layer를 말합니다. 입력 데이터(X)를 넣으면 결과물(φ(X))를 출력합니다. Regularity는 함수가 얼마나 부드럽고 안정적으로 작동하는지를 나타냅니다. 만약 regularity가 좋으면, 입력값을 조금만 바꾸면, 출력도 조금만 바뀌어 예측 가능한 범위 내에서 변합니다. 하지만, regularity가 나쁘다면, 입력값을 조금만 바꿨을 때, 결과값이 매우 크게 변하여 예측 불가능한 출력을 만들어낼 수 있습니다.
Note: Lipschitz constant C는 최대 경사도를 의미합니다. ||φ(X) - φ(Y)|| ≤ C||X - Y||라는 식에서 ||X - Y||는 입력값을 바꾼 정도를 의미하며, ||φ(X) - φ(Y)||는 layer를 통과한 후 결과값이 변한 정도를 의미하고, C는 한계치를 의미합니다. 이를 해석하면, 입력을 1만큼 바꿨을 때, 결과값은 아무리 변해봤자 C배 이상은 안 변한다는 뜻입니다. 그리고 이 상수 C가 작을수록 모델이 얌전하고 학습하기 쉽습니다. 반대로, C가 엄청나게 크거나 무한대라면, 모델이 언제 폭발할지 모르는 시한폭탄이라는 뜻입니다.
Note: Jacobian은 특정 지점(X)에서 모든 방향으로의 경사도를 의미하며, Spectral norm은 jacobian의 최대값을 의미합니다. 따라서 Local Lipschitz constant는 특정 지점(X)에서의 가장 가파른 기울기(spectral norm)를 뜻합니다. 그렇다면 최종적으로 알고 싶은 layer function φ()의 global Lipschitz constant는 어떻게 구할까요? 전체 집합 χ를 돌아다니며 모든 지점(X)의 local Lipschitz constant의 최대값을 찾으면 constant C가 나옵니다.
다음은 SigmoidAttn의 regularity를 제시하는 theorem입니다:
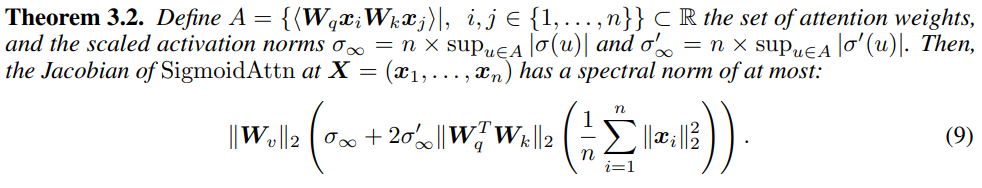
Attention 가중치들의 집합을 A로 정의하고, sigmoid function이 뱉어낼 수 있는 가장 큰 출력값에 n을 곱한 sigmoid 최대값을 σ_∞로, sigmoid 함수를 미분했을 때 나올 수 있는 가장 가파른 경사도에 n을 곱한 값을 σ'_∞라고 했을 때, C가 다음과 같은 상한선을 갖는다는 것을 증명합니다. 이는 bias를 -log(n)으로 설정했기 때문에 가능합니다. 이 덕분에 n이 매우 길어져도 σ()값 자체가 1/n 수준으로 줄어들어서, σ에 n을 곱한 σ_∞가 서로 상쇄되어 유한한 숫자 exp(μ)안에 갇히게 됩니다. 한편, 위 theorem에 따르면 SigmoidAttn은 입력 sequence의 평균 제곱 norm에 의존하는 반면(theorem 3.2 가장 마지막 항), SoftmaxAttn은 가장 큰(max) 값에 의존합니다. 이는 SigmoidAttn의 단순성에서 비롯된 또 다른 결과이며, SoftmaxAttn에 있는 정규화 상수(분모)가 제거되었기 때문입니다.
Note: SoftmaxAttn은 최대값에 의존하는 것이 왜 문제가 될까요? Softmax는 모든 token의 점수 함을 1로 맞춰야 하기 때문에, 모든 단어가 coupled 되어 있습니다. 만약 100개의 tokens들 중 99개의 점수가 낮아도, 나머지 한 개의 점수가 그에 상응하게 높아지기 때문에, 해당 layer의 안정성이 무너집니다. 하지만 SigmoidAttn은 각 token들을 독립적(decoupled)으로 평가합니다. 따라서 99개의 token의 점수가 낮고, 나머지 한 개의 점수가 높더라도, 평균치에 묻혀 안정적으로 동작합니다.
이 결과는 모든 x_i가 반지름 R인 공(ball) 안에 있다면 SigmoidAttn의 Lipschitz constant가 최대 R^2에 비례하여 커진다는 것을 의미하지만, 이 결과는 무한한 분포를 가지는 x_i에도 적용할 수 있기 때문에 훨씬 더 강력합니다; 오직 second moment가 bounded된다는 것만이 중요합니다.
이는 SoftmaxATtn에 대해 얻어진 upper bound와 극명한 대조를 이룹니다: Castin et al. (2023, theorem 3.4)은 모든 i에 대해 ||x_i|| ≤ R을 만족하는 sequence X = (x_1, x_2, ..., x_n)이 존재하여, 이 X에서 attention의 jacobian spectral norm이 어떤 상수 c > 0에 대해 최소 cR^2exp(cR^2)가 됨을 보여주었습니다. 반면에, SigmoidAttn의 upper bound는 R^2에 비례하여 커지며, 이는 SigmoidAttn의 local Lipschitz constant가 SoftmaxAttn의 최악의 local Lipschitz constant보다 훨씬 낮다는 것을 의미합니다. 이는 실제 평균적인 경우(average case)의 Lipschitz constant를 알려주는 것은 아니며, 실제 Lipschitz constant는 Softmax와 SigmoidAttn 모두에서 이보다 훨씬 더 낮을 가능성이 높습니다.
Computational Complexity of Sigmoid and Softmax.

n_ctx와 d_head는 각각 context length와 head dimension입니다. Δ는 sigmoid와 softmax간의 계산량 차이를 측정합니다. c는 causal(추론 시, c = (n_ctx + 1)/2n_ctx ~ 1/2)와 standard(c=1) attention 여부를 반영하는 비율입니다. 1B LLM에서 전형적으로 사용되는 n_ctx와 d_head의 값은 각각 2048, 64입니다. SigmoidAttn과 SoftmaxAttn은 동일한 수의 부동소수점 연산을 공유합니다. 나머지 차이점들은 구현 세부 사항 때문이며, attention logit L을 계산하는 것은 다른 attention 연산들에 비하면 아주 미미한 수준입니다(~1%).
FLASHSIGMOID: Hardware-Aware Implementation.
(... FLASHATTENTION에서 영감을 받은 구현들 설명 ...)
Experiments.
SigmoidAttn을 경험적으로 검증하기 위해, 여러 도메인에 걸쳐 평가를 진행하며, 다음과 같은 관찰 결과를 얻었습니다:
- SigmoidAttn은 MAE를 제외하면 bias가 없어도 vision task에서 효과적이며, hyperparameter없이 baseline SoftmaxAttn의 성능에 맞추기 위해서는 LayerScale에 의존합니다.
- 언어 모델링(LM)과 ASR은 initial norm인 ||σ(QK^T/√d)V||에 민감합니다. 따라서 다음을 통한 modulation이 필요합니다: SigmoidAttn 하에서 logit mass를 0근처로 이동시켜 초기 attention norm을 줄이는 ALiBi와 같은 relative embedding을 사용합니다. 또한 모든 positional embedding을 사용할 수 있게 하면서 동일한 효과를 달성하기 위한 적절한 bias 값의 초기화와 추가적인 normalization 비용을 감수한 hybrid-norm을 추가합니다.
Ablations.
도입한 각 구성 요소의 이점을 분석하기 위해 ablations을 수행합니다. attention의 모든 구성 요소를 측정하고 LayerScale, QK norm, 다양한 positional embedding 기법들 그리고 b의 초기화 값에 대한 효과를 검증합니다.
아래의 그림은 C4 datasets의 realnews split data를 사용하며 단일 layer AR(auto regressive) transformer block을 학습시킨 결과입니다:

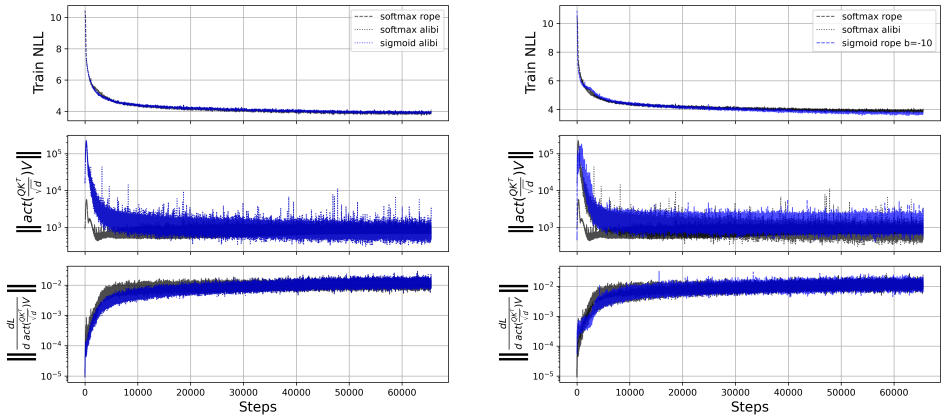
SigmoidAttn은 SinCos(그림 3.) 또는 RoPE를 사용할 때 초기에는 SoftmaxAttn보다 성능이 떨어졌는데, 이는 초기 높은 attention norm인 ||σ(QK^T/√d)V||에 있다고 봅니다. 이러한 큰 attention norm 문제를 해결하기 위해, 다음을 제안합니다:
(a) sigmoid 활성화 하에서 상대적 편향을 통해 초기 attention logit mass를 0으로 이동시켜 동등한 훈련 negative log-likelihoods를 생성하는 ALiBi의 사용; 또는
(b) attention logit bias b를 sequence 길이에 비례하는 음의 offset인 -ln(n)으로 설정.
참고로, (b)는 RoPE와 같은 다른 PE 기법의 사용을 가능하게 합니다(그림 6.)
Note: ALiBi는 attention score를 거리에 따라서 scaling하는 것으로, 거리가 멀면 attention score를 낮춰서 길이에 대해서 어느 정도 안정적으로 norm을 유지할 수 있는 position embedding 방법입니다. 따라서 bias = -log(n)을 통해 길이에 대한 안정성을 추가할 필요 없지만, RoPE나 SinCos은 길이에 대한 안정화 기능이 없기 때문에 bias = -log(n)을 통해 attention norm을 안정적으로 유지해야 합니다.
또한 이론적 분석인 theorem 3.2를 검증하기 위해, sequence 길이에 걸친 SigmoidAttn과 SoftmaxAttn의 jacobian norm을 측정합니다:

자동 미분을 사용하여, hybrid norm을 사용했을 때와 사용하지 않았을 때 두 메커니즘에 대한 정확한 jacobian norm을 계산하고, 이를 theorical bounds와 비교합니다. 두 변형 모두 경험적 norm(실선)이 이론적 upper bound(점선)을 훨씬 밑도는 것을 보여줍니다. 본 논문에서 제안한 bias init(b = -log(n))를 통해 SigmoidAttn은 두 설정 모두에서 SoftmaxAttn보다 더 낮은 norm을 달성하며, 이는 regularity가 향상되었음을 시사합니다.
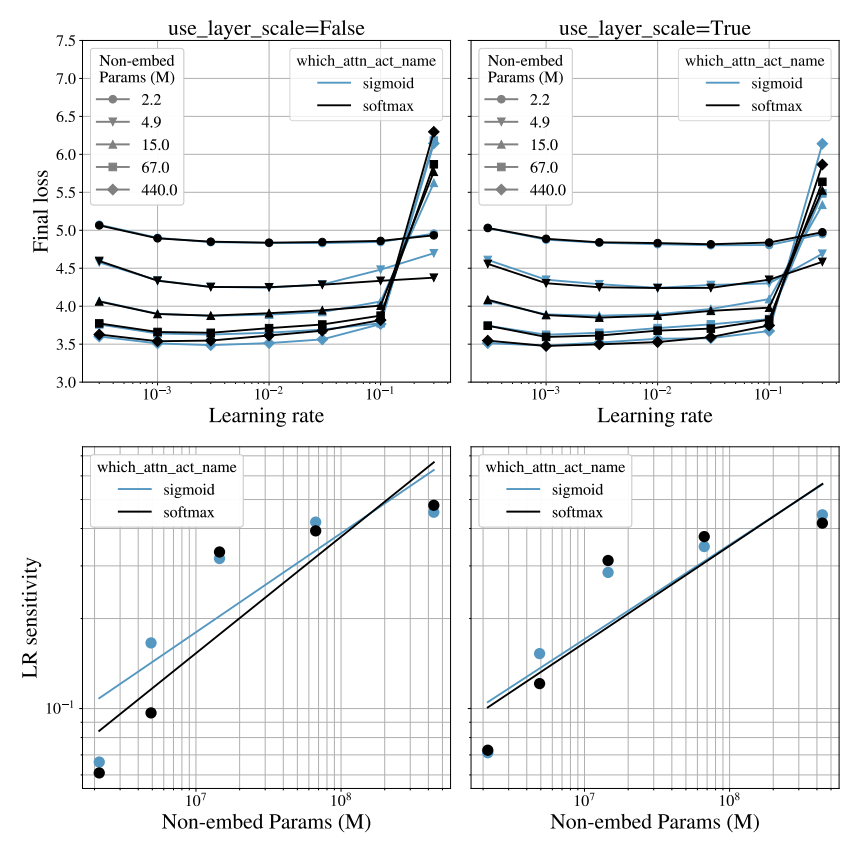
한편, LayerScale의 필요성을 검증하기 위해, 안정성에 미치는 영향을 정량화하는 Wortsman et al. (2023b)의 방법을 따릅니다. 모든 모델은 b = -ln(n)인 RoPE와 AdamW를 사용하여 C4의 realnews split data에서 학습됩니다. Wortsman et al. (2023b)에 따라, 학습률 η ∈ {3e-4, 1e-3, 3e-3, 1e-2, 3e-2, 1e-1, 3e-1} 범위를 탐색합니다. LayerScale은 1e-4로 초기화되며, LayerScale이 성능을 향상시키는 vision task(그림 10.(a))와 달리, LM에서는 SoftmaxAttn이 LayerScale로부터 약간의 이점을 얻는 반면 SigmoidAttn의 성능은 대체로 영향을 받지 않는 것을 관찰했습니다.
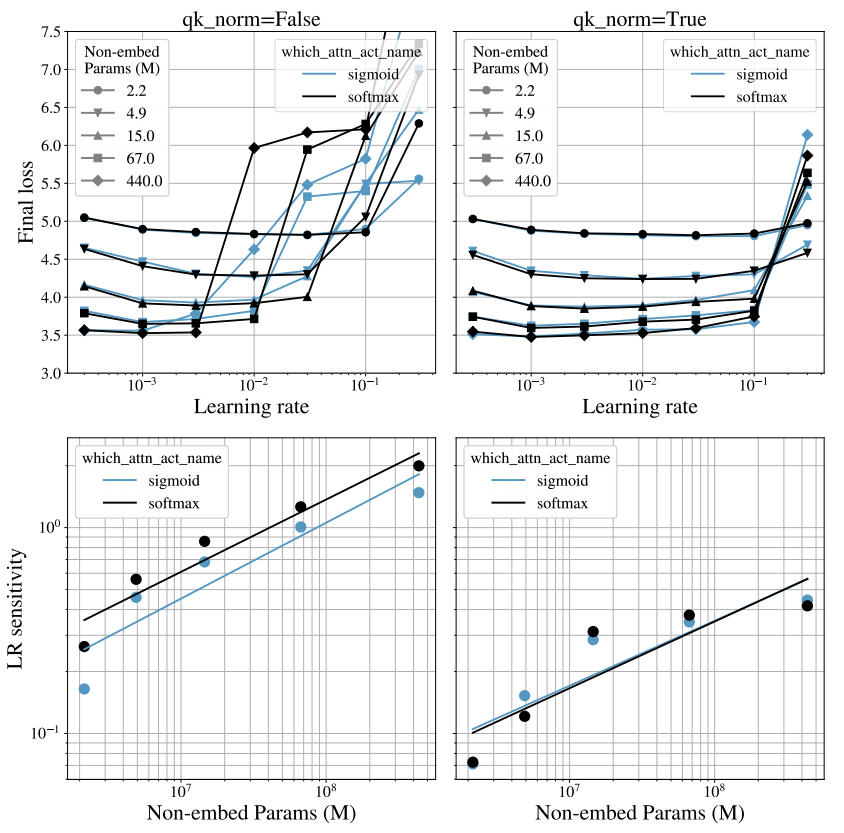
SoftmaxAttn과 SigmoidAttn의 안정성을 탐구하기 위해, LayerScale 분석에서 설명한 바와 같이 Wortsman et al. (2023b)의 분석을 이용하여 QK norm의 영향을 조사합니다. LM의 경우, SigmoidAttn과 SoftmaxAttn 모두 QK norm이 없을 때 학습률 변화에 민감함을 보입니다. 그러나 QK norm을 사용하면 크게 안정화되며(그림 9). vision task에서 SigmoidAttn은 QK norm이 있든 없든 (그림 10.(a)), 그리고 Wortsman et al. (2023a)의 n^-α 정규화가 필요 없이 견고함을 보여줍니다:
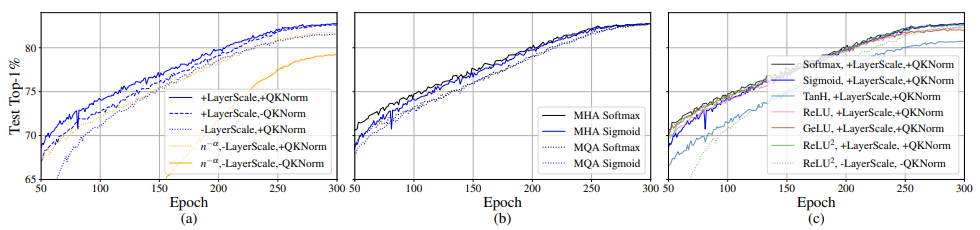
(... 다른 tasks들에 대한 연구 ...)