
https://arxiv.org/abs/2010.04159
Deformable DETR: Deformable Transformers for End-to-End Object Detection
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Tra
arxiv.org
Abstraction.
DETR은 object detection에서 수작업으로 설계된 많은 구성 요소(NMS, anchors 설계 등)의 필요성을 없애면서도 좋은 성능을 보여주기 위해 제안되었습니다. 그러나 image feature map을 처리하는 trasnformer attention module의 한계로 인해, 느린 수렴 속도와 제한된 feature 공간 해상도(spatial resolution) 문제를 겪습니다. 이러한 문제를 완화하기 위해, Deformable DETR을 제안합니다. 이 모델의 attention module은 reference points 주변의 작은 핵심 sampling points에만 attention을 계산합니다. Deformable DETR은 DETR보다 10배 적은 학습 epoch으로 (특히 작은 객체에서) 더 나은 성능을 달성할 수 있습니다.
Introduction.
현대 object detector들은 anchor generation, 규칙 기반 타겟 할당, NMS 후처리 등 수작업으로 설계된 구성 요소를 많이 사용합ㅂ니다. 이들은 완전한 end-to-end가 아니며, 이러한 요소들을 없애기 위해 DETR이 제안되었으며, 최초의 end-to-end object detector를 구축하여 좋은 성능을 달성했습니다. DETR은 CNN과 transformer encoder-decoder를 결합한 단순한 아키텍처를 활용합니다. 하지만 DETR에는 다음과 같은 단점들이 존재합니다:
- 느린 수렴: 기존 object detector보다 수렴하는 데 훨씬 더 긴 학습 epoch이 필요합니다(예: Faster R-CNN보다 10-20배 느림).
- 작은 객체 탐지 성능 저하: DETR은 고해상도 feature map을 처리할 때 복잡도가 매우 높아지기 때문에, 작은 객체를 탐지하는 데 상대적으로 낮은 성능을 보입니다.
Note: 초기 DETR은 구조상 FPN과 같은 multi-scale 입력을 처리하도록 설계되지 않았습니다. DETR은 ResNet 등과 같은 backbone의 가장 마지막 층인 C5 feature map을 사용하여, 보통 이미지의 1/32 크기입니다. 만약 작은 객체 탐지 성능을 늘리기 위해 고해상도 feature map을 입력으로 받는다면, pixel 개수 N에 대해서 N^2에 달하는 계산 복잡도를 감당해야하는데 이는 어렵습니다.
위 문제들은 주로 image feature map을 처리할 때 transformer 구성 요소 자체의 결함에 기인합니다. 초기화 시 attention module은 feature map의 모든 pixel에 거의 균일한 attention 가중치를 부여하며, 의미 있는 sparse meaningful locations에 집중하도록 가중치를 학습시키려면 긴 학습 시간이 필요합니다.
Note: 한편, Attention을 수행하는데 sparsification이 중요하다는 것은 이전 글에서도 언급된 적이 있습니다:
[CoIn] 논문 리뷰 | Gated Attention for Large Language Models: Non-linearity, Sparsity,and Attention-Sink-Free (Qiu et al., 2
https://arxiv.org/abs/2505.06708 Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-FreeGating mechanisms have been widely utilized, from early models like LSTMs and Highway Networks to recent state space models, linear
hw-hk.tistory.com
또한, transformer encoder의 attention 가중치 계산은 픽셀 수의 이차적인(quadratic) 연산량을 가지기 때문에, 고해상도 feature map을 처리하는 것은 계산 및 메모리 복잡도가 매우 높습니다. 한편, image domain에서 deformable convolution은 sparse한 공간 위치에 집중하는 강력하고 효율적인 메커니즘입니다:
https://arxiv.org/abs/1703.06211
Deformable Convolutional Networks
Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric structures in its building modules. In this work, we introduce two new modules to enhance the transformation modeling capacity of CNNs
arxiv.org
하지만 deformable convolution 자체에는 DETR 성공의 핵심인 요소 간 관계 모델링(element relation modeling) 메커니즘이 부족합니다. 따라서 이를 attention을 통해 해소하여 DETR의 느린 수렴과 높은 복잡도 문제를 완화하는 deformable DETR을 제안합니다. deformable convoltion의 sparse spatial sampling 장점과 trasnformer의 relation modeling 능력을 결합하는 것입니다. 모든 feature map pixel 중에서 핵심 요소를 사전 필터링하여 작은 sampling position에만 attention을 수행하는 deformable attention module을 제안합니다. 이 모듈은 FPN의 도움 없이도 multi-scale feature를 자연스럽게 통합할 수 있습니다(아래 그림 1. 참조).
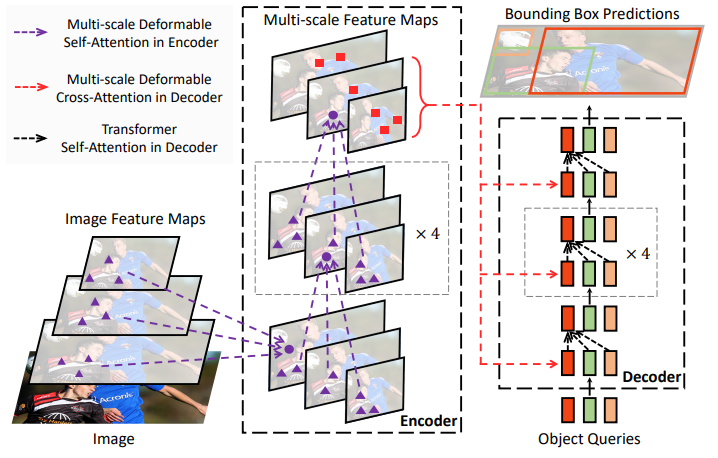
deformable DETR의 빠른 수렴 속도와 계산 및 메모리 효율성으로 인해, end-to-end object detector의 변형들을 탐구할 수 있었으며, detection 성능을 향상시키기 위해 간단하고 효과적인 iterative bounding bosx refinement 메커니즘을 탐구했습니다. 또한, two-stage deformable DETR도 시도했는데, 이는 RoI proposals 단계에서 deformable DETR의 변형을 이용하는 것입니다.
Relate Work.
transformer는 self-attention과 cross-attention 메커니즘을 모두 포함하며, 이에 대한 가장 큰 단점은 방대한 수의 key에서 오는 높은 시간 및 메모리 복잡도로, 이는 모델의 확장성을 저해합니다. 이를 해결하기 위한 노력들은 다음과 같습니다:
- key에 대해 사전 정의된 sparse attention pattern을 사용하는 것입니다. 가장 단순하게는 attention pattern을 고정된 local window로 제한하는 것입니다. attention pattern을 local neighbors들로 제한하면, 복잡도는 줄어들지만, global information을 잃게 됩니다. 이를 보완하기 위해, key에 대한 receptive field를 크게 늘리기 위해 고정된 간격으로 key에 attend하기도 합니다. 한편, 적은 수의 특별한 토큰들이 모든 key 요소들에 접근할 수 있도록 허용하거나, 먼 거리의 key들에 집접 attention을 사용하는 고정된 sparse attention pattern을 추가하기도 합니다.
- data-dependent sparse attention을 학습하는 것입니다.
- self-attention의 low-rank 특징을 이용하는 것입니다. Wang et al. (2020b)는 channel 차원 대신 크기(seqlength) 차원에 대한 linear projection을 통해 key의 수를 줄이며, kernel 근사화를 통해 self-attention 계산을 할 수도 있습니다.
이미지 도메인에서 효율적인 attention mechanism들은 첫 번째 범주(key에 대해 사전 정의된 sparse attention pattern을 사용하는 것)에 머물러 있으며, 이론적으로 감소된 복잡도에도 불구하고, 메모리 접근 패턴의 내재적인 한계로 인해 이러한 접근 방식들이 동일한 FLOPs 하에서 전통적인 합성곱보다 느립니다.
한편, deformable convolution이나 dynamic convolution과 같은 합성곱의 변형들은 self-attention mechanism으로도 볼 수 있습니다(attend할 부분만 계산하는 것). 특히 deformable convolution은 이미지 인식에서 transformer self-attention 보다 훨씬 더 효과적이고 효율적이지만, 요소 간 관계 모델링(relation modeling)이 부족합니다.
Note: deformable convolution에서 집중해야하는 부분에 대해서 계산을 하는 것까지는 좋은데, 그렇게 reference points들을 뽑아놓고 convolution 연산을 수행하면 관계 모델링이 안됩니다. convolution 연산은 해당 연산에 참여하는 요소들 간의 관계를 이용하는 연산은 아니기 때문입니다. 한편 attention은 그 연산의 의도 자체가 해당 연산에 참여하는 요소들 간의 context를 반영하는 것이기 때문에, 관계 모델링에는 유리합니다. 즉, deformable convolution에서의 sparse한 요소 선택과 attention의 관계 모델링을 섞으면 됩니다.
본 논문에서 제안하는 deformable attention은 위에서 언급한 두 번째 범주(data-dependent sparse attention을 학습하는 것)에 속합니다. 이것은 query feature로부터 예측된 적은 수의 고정된 sampling points에만 attend합니다.
object detection의 주요한 어려움 중 하나는 매우 다른 scale의 효과적으로 표현하는 것입니다. 현대의 object detector들은 이를 위해 multi-scale feature들을 사용합니다. 이에 대표적인 연구로 FPN이 있습니다:
[CoIn] 논문 리뷰 | Feature Pyramid Networks for Object Detection (Lin et al., 2017)
https://arxiv.org/abs/1612.03144 Feature Pyramid Networks for Object DetectionFeature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representa
hw-hk.tistory.com
FPN은 multi-scale feature들을 결합하기 위해 top-down 경로를 사용하며, PANet은 FPN 위에 bottm-up 경로를 추가한 것이며, BiFPN은 PANet의 반복적이고 단순화된 버전입니다:
[CoIn] 논문 리뷰 | EfficientDet: Scalable and Efficient Object Detection (Tan et al., 2020)
https://arxiv.org/abs/1911.09070 EfficientDet: Scalable and Efficient Object DetectionModel efficiency has become increasingly important in computer vision. In this paper, we systematically study neural network architecture design choices for object detect
hw-hk.tistory.com
본 논문에서 제안하는 multi-scale deformable attention module은 이러한 feature pyramid들의 도움 없이도 attention mechanism을 통해 multi-scale feature map을 자연스럽게 aggregation할 수 있습니다.
Revisiting Transformers and DETR.
transformer는 기계 번역을 위한 attention mechanism에 기반한 네트워크 아키텍처입니다. query element와 key element가 주어졌을 때, multi-head attention module은 query-key 쌍의 적합성을 측정하는 attention score에 따라 key의 내용을 적응적으로 aggregate합니다. 모델이 서로 다른 representation subspaces와 서로 다른 위치의 내용에 attend할 수 있도록 하기 위해, 서로 다른 attention head들의 출력들은 가중치와 함께 선형적으로 결합됩니다.
q(z_q)는 query, k(x_k)는 key라고 했을 때, Multi-head attention은 다음과 같습니다:
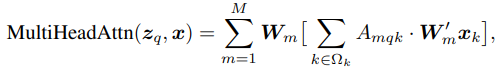
여기서 A_mqk는 head m, query q, key k에 대한 attention score로 다음과 같이 구할 수 있습니다:

이런 transformer에는 두 가지 문제가 존재합니다:
- 느린 수렴: transformer는 수렴하기까지 긴 학습 일정이 필요합니다. query와 key요소의 수가 각각 N_q, N_k라고 했을 때, 파라미터 초기화를 했을 때, U_mz_q와 V_mx_k는 평균 0, 분산 1인 분포를 따릅니다. 이때 N_k가 클 때 attention 가중치 A_mqk는 1/(N_k)가 되게 합니다. 이는 입력 feature에 대해 ambigous gradients를 초래하며, attention score가 특정 key에 집중할 수 있게 하려면 긴 학습 일정이 필요합니다.
- 높은 복잡도: 수많은 query 및 key 요소로 인해 MHA의 계산 및 메모리 복잡도가 매우 높을 수 있습니다.

DETR은 transformer encoder-decoder architecture를 기반으로 구축되었으며, bipartite matching을 통해 각 GT bbox에 대해 고유한 예측을 강제하는 set-based hungarian loss와 결합되어 있습니다. 이를 간단히 리뷰하면 다음과 같습니다: CNN backbone(예: ResNet)에 의해 추출된 input feature map이 주어지면, DETR은 표준 transformer encoder-decoder architecture를 활용하여 input feature map을 일련의 object queries로 변환합니다. detection head로서 3개의 FFN과 linear projection이 decoder에 의해 생성된 object queries 위에 추가됩니다. FFN은 regression branch로 작동하여 bbox를 예측하며, linear projection은 classification branch로 작동하여 분류 결과를 생성합니다.
DETR encoder의 입력은 ResNet feature map이며, H와 W를 각각 feature map의 높이와 너비라고 했을 때, self-attention의 계산 복잡도는 O(H^2W^2)입니다. DETR의 decoder의 입력은 encoder로부터 온 feature map과 학습 가능한 위치 임베딩으로 표현되는 N개의 object queries입니다. deocder에는 두 가지 유형의 attention module인 cross-attention과 self-attention이 존재합니다:
- cross-attention: object queries가 feature map에서 feature를 추출합니다. query는 object query이며, key는 encoder의 output feature map입니다. 여기서 N_q = N이며, N_k = H x W입니다. cross attention의 복잡도는 O(HWC^2+NHWC)입니다. 이 복잡도는 feature map 크기에 대해 선형적으로 증가합니다.
- self-attention: object queries 끼리 상호 작용하여 관계를 포착합니다. query와 key 모두 object queries이며, N_q = N_k = N이며, 복잡도는 O(2NC^2+N^2C)입니다. 이 복잡도는 적당한 수의 object queries에 대해서 허용 가능합니다.
DETR은 수작업으로 설계되는 많은 구성 요소들의 필요성을 제거한 매력적인 object detection 설계이지만, 다음과 같은 문제가 존재합니다:
- 작은 객체 탐지 성능 저하: 다른 object detector들은 작은 objects들을 더 잘 탐지하기 위해 고해상도 feature map을 사용합니다. 그러나 고해상도 feature map은 DETR의 transformer encoder 내 self-attention module에 대해 감당할 수 없는 복잡도를 초래합니다.
- 느린 수렴: 다른 object detector들에 비해, DETR의 수렴 속도는 매우 느립니다. 이는 주로 이미지 feature를 처리하는 attention module이 학습하기 어렵기 때문입니다. 예를 들어, 초기화 시점에 cross-attention module은 전체 feature map에 대해 거의 평균적인 attention을 갖습니다. 반면 학습이 끝날 때 attention map은 매우 sparse해져서 객체의 일부분에만 집중하도록 학습됩니다. DETR은 attention map에서 이러한 중요한 변화를 학습하기 위해 긴 학습 일정을 필요로 합니다.
Method.
Deformable attention
image feature map에 transformer attention을 적용하는 것의 핵심 문제는 그것이 모든 가능한 공간 위치를 본다는 것입니다. 이를 해결하기 위해 deformable attention module을 제안합니다. 이는 deformable convolution에서 영감을 받아, 그림 2. 에서 보는 바와 같이 feature map의 공간 크기와 무관하게 reference point 주변의 작은 핵심 sampling poinst에만 attend합니다:

각 query에 대해 적은 고정된 수의 key들만을 할당함으로써, 수렴 및 해상도 문제를 완화할 수 있습니다.
Note: 해상도 문제를 완화할 수 있다는 것은 기존에 높은 계산 복잡도로 인해 높은 해상도를 입력으로 받을 수 없었지만, 이제 deformable attention을 통해 더 가볍게 attention module을 실행할 수 있어서 높은 해상도를 입력으로 받을 수 있고, 높은 해상도를 입력으로 받지 못해서 생기는 작은 객체 탐지 문제를 해결할 수 있다는 의미이다.
input feature map이 주어졌을 때, q가 content feature z_q와 reference points p_q를 인덱싱한다면, deformable attention 은 다음과 같이 계산됩니다:
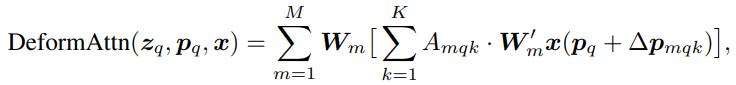
여기서 m은 attention head를, k는 sampling된 key를, K는 총 sampling된 key의 수입니다. delta p_mqk와 A_mqk는 각각 m번째 attention head 내 k번째 sampling point의 sampling offset과 attention score를 나타냅니다. p_q + delta p_mqk를 통해 reference points들을 찾을 때, 이 값은 분수가 되므로, bilinear interpolation을 사용합니다. delta p_mqk와 A_mqk는 모두 query feature z_q에 대한 linear attention으로 얻어집니다.
deformable attention은 convolution feature map을 key로 처리하도록 설계되었습니다. N_q를 querise의 수라고 할 때, MK가 상대적으로 작다면, deformable attention의 복잡도는 O(2N_qC^2+min(HWC^2,N_qKC^2))입니다. 이것이 encoder에 적용될 때, N_q = HW이기 때문에, O(HWC^2)가 되며, decoder에 적용될 때는 O(NKC^2)가 됩니다(HW와 무관).
Multi-scale Deformable Attention Module
대부분의 현대 object detection framework는 multi-scale feature map의 이점을 활용하며, 이를 multi-scale feature map을 위해 자연스럽게 확장할 수 있습니다. 기존의 deformable attention의 입력 중 하나인 x를 multi-scale feature map x^l로 수정하면 됩니다:

이때 함수 φ는 정규화된 좌표 p_q_hat을 l번째 level의 입력 feature map으로 re-scale하는 함수입니다. multi-scale deformable attention은 단일 scale feature map에서 K개의 포인트를 sampling하는 대신 multi-scale feature map에서 LK개의 포인트를 sampling한다는 점을 제외하면 이전과 매우 유사합니다. sampling points가 모든 가능한 위치를 찍는다면, 이는 transformer attention과 동일합니다.
Deformable Transformer Encoder-Decoder
DETR에서 feature amp을 처리하는 transformer attention module을 제안한 multi-scale deformable attention으로 대체합니다. encoder의 입력과 출력은 모두 동일한 해상도의 multi-scale feature map이며, encoder에서 ResNet의 단계 C3부터 C5까지의 feature map으로부터 multi-scale feature map X^l를 추출합니다. 여기서 C_l은 입력 이미지보다 2^l 낮은 해상도를 갖습니다. 여기서 FPN의 top-down 구조는 사용되지 않는데, 이는 본 논문에서 제안한 multi-scale deformable attention 그 자체가 multi-scale feature map 간의 정보를 교환할 수 있기 때문입니다.
encoder에 multi-scale deformable attention을 적용할 때, 출력은 입력과 동일한 해상도를 가진 multi-scale feature map입니다. key와 query 요소는 모두 multi-scale feature map의 pixel이며, 각 query pixel에 대해, reference point는 자기 자신입니다. 각 query pixel이 어떤 feature level에 있는지 식별하기 위해, 위치 임베딩 외에도 scale-level embedding을 feature map에 추가합니다. 또한 위치 임베딩은 고정된 인코딩을 갖는 반면, scale-level embedding은 네트워크와 함께 공동으로 학습됩니다.
decoder에는 cross attention 모듈과 self-attention module이 있습니다. 두 유형의 attention module에 대한 query 요소는 object queries입니다. cross attention module에서 object queries는 feature map으로부터 feature를 추출하는데, 여기서 key 요소는 encoder에서 추출된 feature map입니다. self-attention module에서는, object queries들이 서로 상호작용하는데, 여기서 key 요소는 object queries들입니다. 본 논문에서 제안한 deformable attention은 encoder feature map을 key 요소로 처리하도록 설계되었기 때문에, 각 cross-attention module 만을 multi-scale deformable attention으로 바꾸고, self-attention module은 변경하지 않고 그대로 둡니다. 각 object queries들에 대해, reference points p_q의 정규화된 좌표(0-1)은 학습 가능한 linear projection(detection head와는 다름)과 sigmoid를 거쳐 object query embedding으로부터 예측됩니다.
multi-scale deformable attention module이 reference points 주변의 이미지 feature를 추출하기 때문에, 최적화 난이도를 낮추기 위해 detection head가 reference point에 대한 상대적 offsets으로 예측하도록 합니다. reference point는 bbox 중심의 초기 추정값으로 사용되며, detection head는 reference point에 대한 상대적 offsets을 예측합니다. 이런 방식으로, 학습된 decoder attention은 예측된 bbox와 강한 상관관계를 갖게 되며, 이는 수렴 속도를 가속화합니다.
Iterative Bounding Box Refinement
또한 deformable DETR은 빠른 수렴 속도와 계산 및 메모리 효율성 덕분에 end-to-end object detector의 다양한 변형을 사용할 수 있습니다. 그 중 하나는 iterative bbox refinement입니다. 이는 각 decoder layer는 이전 layer로부터의 예측을 기반으로 bbox를 refine하는 것을 말합니다.
Note: decoder의 각 layer마다 detection head가 존재하며, 첫 번째 layer에서 들어오는 reference point를 초기 bbox위치로 정한 후 각 layer를 통과할 때마다 detection head는 그 bbox의 offset만을 예측합니다. 다음 layer의 reference point는 그 전 layer의 detection head를 통해 예측된 offset이 적용된 bbox를 사용합니다.
Experiment.

표 1.은 Deformable DETR의 성능을 보여줍니다.

그림 3.은 Deformable DETR이 매우 빠른 수렴 속도를 달성한다는 것을 보여줍니다.