
https://arxiv.org/abs/2111.14330
Sparse DETR: Efficient End-to-End Object Detection with Learnable Sparsity
DETR is the first end-to-end object detector using a transformer encoder-decoder architecture and demonstrates competitive performance but low computational efficiency on high resolution feature maps. The subsequent work, Deformable DETR, enhances the effi
arxiv.org
Abstract.
DETR은 transformer encoder-decoder architecture를 사용하는 end-to-end object detector이며, 경쟁력 있는 성능을 보여주지만, 고해상도 feature map에서는 낮은 연산 효율성을 보입니다. deformable DETR은 dense attention을 deformable attention으로 대체하여 DETR의 효율성을 향상시켰으며, 이는 10배 더 빠른 수렴과 향상된 성능을 달성했습니다. deformable DETR은 성능을 개선하기 위해 multi-scale feature를 사용하지만, encoder token 수가 DETR에 비해 20배 증가하고 encoder attention 연산 비용이 여전히 병목으로 남습니다.
본 논문의 저자들은 encoder token의 일부만 업데이트되더라도 탐지 성능이 거의 저하되지 않음을 관찰했으며, 이러한 관찰에서 영감으로 받아, decoder에 의해 참조될 것으로 예상되는 토큰만 선택적으로 업데이트하여 모델이 객체를 효과적으로 탐지하도록 돕는 Sparse DETR을 제안합니다. 또한 encoder에서 선택된 토큰에 aux loss를 적용하는 것이 연산 오버헤드를 최소화하며 성능을 향상시킨다는 것을 보여줍니다.
Introduction.
Carion et al. (2020)은 set-based objective를 통해 NMS 후처리의 필요성을 제거함으로써 완전한 end-to-end detector인 DETR을 제안했습니다. 학습 목적 함수는 classification 및 regression 비용을 모두 고려하는 hungarian algorithm을 사용하여 설계되었으며, 매우 경쟁력있는 성능을 달성합니다. 그러나 DETR은 작은 객체의 탐지 개선을 위해 객체 탐지에서 일반적으로 사용되는 FPN과 같은 multi-scale feature들을 사용할 수 없습니다. 이는 transformer architecture의 메모리 사용량과 연산량 때문입니다.
[CoIn] 논문 리뷰 | Feature Pyramid Networks for Object Detection (Lin et al., 2017)
https://arxiv.org/abs/1612.03144 Feature Pyramid Networks for Object DetectionFeature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representa
hw-hk.tistory.com
이 문제를 해결하기 위해 deformable convolution에서 영감을 받은 deformable attention을 제안하며, attention module내의 key sparsification을 통해 quadratic 복잡도를 linear 하게 줄였습니다:
[CoIn] 논문 리뷰 | DEFORMABLE DETR: DEFORMABLE TRANSFORMERSFOR END-TO-END OBJECT DETECTION (Zhu et al., 2021)
https://arxiv.org/abs/2010.04159 Deformable DETR: Deformable Transformers for End-to-End Object DetectionDETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. Howev
hw-hk.tistory.com
deformable attention을 사용함으로써, deformable DETR은 DETR의 느린 수렴과 높은 복잡도 문제를 해결하며, 이는 encoder가 multi-sscale feature를 입력으로 사용할 수 있게 하고 작은 객체 탐지 성능을 크게 향상시킵니다. 그러나 multi-scale feature를 encoder 입력으로 사용하는 것은 처리해야 할 토큰의 수를 약 20배 증가시킵니다. 결국, 동일한 토큰 길이에 대해서는 효율적인 연산을 수행함에도 불구하고 전체 복잡도가 다시 증가하여(multi-scale feature를 입력해서, single-scale feature를 사용하면 토큰 사용량이 매우 줄어드는 것은 맞다), 모델 추론 속도가 vanilla DETR보다 느려지게 됩니다.
일반적으로 자연 이미지는 관심이 있는 객체와 무관한 넓은 배경 영역을 포함하는 경우가 많으며, 이에 따라 end-to-end detector에서도 배경에 해당하는 토큰이 상당 부분을 차지합니다. 게다가 각 지역적 특성의 중요도는 동일하지 않은데, 이는 foreground에만 집중하여 성공적으로 작업을 수행하는 two-stage detector들을 통해 증명된 바 있습니다(RoI proposal을 통해 foreground에 해당하는 부분만 두 번째 network가 추론을 수행한다). 이는 탐지 작업에서 줄일 수 있는 상당한 지역적 중복성(regional redundancy)이 존재함을 시사하며, 두드러진 영역에 집중하는 효율적인 탐지기를 고안하는 것은 자연스러운 방향입니다.
본 논문의 저자는 예비 실험에서 다음을 관찰했습니다:
- 완전히 수렴된 Deformable DETR 모델이 추론하는 동안 decoder가 참조하는 encoder token은 전체의 약 45%에 불과하다.
- 완전히 학습된 다른 detector로부터 decoder가 선호하는 encoder만을 업데이트하면서 새로운 detector를 재학습시킬 때 성능 손실을 거의 겪지 않았습니다(0.1AP 하락).
이러한 관찰에서 영감을 받아, encoder token을 sparsification하기 위한 학습 가능한 decoder cross attention predictor를 제안합니다. 기존 방법들에서 encoder는 모든 토큰, 즉 해당하는 위치 임베딩과 결함된 backbone feature를 구별 없이 입력으로 받습니다. 반면, 해당 방법은 나중에 decoder에서 참조될 encoder 토큰을 구별하고 self-attention에서 오직 그 토큰들만을 고려합니다. 따라서 이는 연산에 관여하는 encoder 토큰의 수를 크게 줄이고 전체 연산 비용을 감소시킬 수 있습니다. 더 나아가 연산 오버헤드를 최소화하면서 탐지 성능을 향상시키기 위해 선택된 encoder 토큰들에 대한 encoder aux loss를 제안합니다. 제안된 aux loss는 성능을 향상시킬 뿐만 아니라 더 많은 수의 encoder layer를 학습시키는 것을 가능하게 합니다.
Related Work.
transformer에서 attention 연산이 높은 시간 및 메모리 복잡도를 초래한다는 것은 잘 알려진 문제입니다. vision transformer는 입력으로 더 큰 토큰 집합을 소화해야 하므로, 이를 위한 경량 attention mechasnism을 제안하는 연구들은 많습니다. 이러한 연구들의 대부분은 단일 스케일 attention module에 존재하는 복잡도만을 조명했습니다.
더 가벼운 transformer attention을 위한 유망한 접근 방식 중 하나는 입력 의존적 토큰 희소화(input-dependent token sparsification)입니다. dynamic ViT와 IA-RED2는 모두 입력 토큰 위에 sparse patterrn을 생성하는 공동 학습된 토큰 선택기를 제안합니다. 이러한 접근 방식들은 주로 분류 작업에서 평가되는 backbone network를 sparsification하는 데 초점을 맞추는 반면, 본 논문의 관심사는 end-to-end object detector의 sparse encoder입니다.
반면에, DETR 기반 framework 내에서 sparse transformer를 목표로 한다는 점에서 유사한 연구들이 존재합니다. Deformable DETR은 학습 가능한 2D offset을 사용하여 전체 key 집합의 일부만 sampling함으로써 sparse attention을 수행하며, 이는 합리적인 연산 비용으로 multi-scale feature map을 사용할 수 있게 해줍니다. 이는 key sparsification 방법으로 볼 수 있지만 여전히 dense queries를 사용하는 반면, 본 논문의 접근 방식은 queries 집합까지 더 줄이는 큰 희소성을 추구합니다. PnP-DETR은 foreground 토큰을 sampling하고 background 토큰을 더 작은 집합으로 압축하는 PnP(Polling and Pull) 모듈을 도입하여 transformer encoder의 토큰 길이를 단축합니다. 그러나 그들의 희소화 방식은 deformable attention에서 가정하는 토큰 집합의 2D 공간 구조를 깨뜨리기 때문에, 그들의 방법은 Deformable DETR과 단순하게 통합될 수 없습니다.
aux loss는 심층 네트워크의 초기 layer에 gradient를 전달하기 위해 널리 채택됩니다. DETR 변형 모델들은 추가적인 FFN head를 통해 모든 decoder layer의 끝에 aux hungarian loss를 적용하며, 이를 통해 각 decoder layer는 decoder의 출력에서 올바른 수의 객체를 탐지하는 것을 직접 학습합니다. 수가 상대적으로 적은(예: 300개) decoder의 object queries와 달리, encoder의 토큰 수는 multi-scale feature를 사용할 때 훨씬 더 큰 규모를 가집니다. 따라서 layerwise aux loss를 다중 scale encoder로 확장하는 것은 부착된 FFN head에 너무 낳은 토큰을 입력하게 되어 학습 시간 비용을 증가시킵니다. 따라서 Sparse DETR에서는 encoder에 이미 유도된 sparsity로 인해, 더 넓은 범위의 중간 layer에서 aux loss의 이점을 누리면서도 즉각적으로 그 비용을 절약할 수 있습니다.
Note: 즉 decoder의 경우 object queries의 #가 그렇게 많지 않기 때문에, detection head를 layer마다 달아서 aux loss를 넣어줘도 inference time에 있어서 그렇게 큰 영향이 없는 반면, encoder의 경우는 HxW 만큼의 queries가 존재하기 때문에, layer마다 aux loss를 넣어주고 싶어도 detection head에 들어가는 토큰의 수가 너무 많아 inference time에 영향이 있습니다.
Approach.
Preliminary
DETR은 backbone network로부터 flatten된 공간 feature map x를 transformer encoder에 입력합니다. 여기서 N은 토큰(즉, feature)의 수를 나타내며, D는 토큰의 차원을 나타냅니다. encoder는 몇 개의 기본 self-attention module을 통해 x를 반복적으로 업데이트합니다. 그 후, transformer decoder는 정제된 encoder output과 M개의 학습 가능한 object queries를 모두 입력으로 받아, 각 객체 query q_i에 대해 class score c와 bbox b의 튜플을 예측합니다. backbone network를 포함한 모든 구성 요소는 GT와 예측 y 간의 bipartite matching을 수행함으로써 학습됩니다.
Deformable DETR은 DETR의 주요 계산 병목인 dense attention을 deformable attention module로 대체합니다. 이는 계산 비용을 크게 줄이며, 수렴을 개선합니다. query 집합과 key 집합의 크기가 N으로 똑같을 때, 기존 dense attention은 모든 쌍에 대해 attention score A_qk를 계산하여, N에 대해 quadratic 복잡도를 초래합니다. deformable attention은 각 query에 대해 관련된 key들만을 고려함으로써 이 quadratic 복잡도를 linear하게 줄입니다.
이런 key sparsification으로 인해, deformable DETR은 backbone network의 multi-scale feature를 사용할 수 있게 되어 작은 객체의 탐지 성능을 크게 향상시킵니다. 하지만 역설적으로, multi-scale feature를 사용하는 것은 transformer encoder내의 token 수를 DETR에 비해 약 20배 증가시켜, encoder가 deformable DETR의 계산 병목이 되게 만듭니다.
Encoder Token Sparsification
encoder token subset은 다음 섹션에서 설명될 특정 기준에 따라 backbone feature map x로부터 얻어집니다. 이 과정에서 업데이트되지 않는 feature들에 대해서, x의 값들은 변하지 않은 채로 encoder layer를 통과합니다(residual connection). 각 톸느의 salient socring network g가 있다고 할 때, 주어진 keeping ratio ρ에 대해 가장 높은 점수를 가진 상위 ρ% 토큰을 ρ-salient regions으로 정의합니다. 그러면 i-th encoder layer는 다음과 같이 feature x를 업데이트합니다:

여기서 DefAttn은 deformable attention을, LN은 layer norm을, FFN은 feed forward network를 나타냅니다. 선택되지 않은 토큰의 경우에도 값들은 여전히 encoder layer를 통과하므로, 선택된 토큰들을 업데이트할 때 key로서 참조될 수 있습니다. 이는 선택되지 않은 토큰들이 자신들의 값을 잃지 않으면서 계산 비용을 최소화한 채 선택된 토큰들에게 정보를 전달할 수 있음을 의미합니다.

deformable DETR은 key sparsification을 통해 attention 복잡도를 줄였고, 위 그림 1. 에서 보여지듯이 query sparsification을 통해 attention 복잡도를 더욱 줄입니다. DETR의 기존 dense attention은 quadratic 복잡도를 가지며, deformable attention은 linear한 복잡도를, sparse attention은 오직 O(SK)만을 갖습니다(S = salient query #, K = sparse key #).
Finding Salient Encoder Tokens
encoder의 각 입력 토큰마다 객체성(objectness, 물체가 있을 정도)를 측정하는 것은 backbone feature 중 어떤 것들이 transformer encoder에서 추가로 업데이트되어야 하는지를 결정하는 데 매우 자연스럽습니다. 사전 학습된 backbone network로부터의 feature map이 객체의 salient를 찾을 수 있다는 것은 널리 알려져 있으며, 이것인 RPN이 많은 object detector들에서 성공적으로 채택된 이유입니다.
이러한 관찰에서 영감을 받아, backbone feature map에 추가적인 detection head와 hungarian looss를 도입하는데, 여기서 새로 추가된 head의 구조는 decoder 내 최종 detection head의 구조와 동일합니다. 그러면 가장 높은 class 점수를 갖는 상위 ρ% encoder tokens들을 선택할 수 있습니다. 이 접근 방식은 encoder tokens들을 희소화하는 데 효과적이지만, 이것이 transformer decoder에게 sub-optimal 합니다. 왜냐하면 detection head로부터 선택된 encoder token들은 decoder를 위해 명시적으로 고려된 것이 아니기 때문입니다.
Note: encoder에 detection head를 달아 salient token을 선택했을 때, 해당 토큰들이 decoder에 자주 쓰인다고 보장할 수는 없습니다. 즉 그렇게 선택된 salient token들은 그저 그 위치에 물체가 있다는 것을 말할 뿐, decoder에서는 foreground 뿐만 아니라 background tokens들도 참조할 수 있습니다.
따라서 decoder와 관련성이 높은 encoder 토큰의 부분집합을 보다 명시적인 방식으로 선택하기 위한 또 다른 접근 방식을 고려했으며, transformer decoder로부터의 cross attention map이 salient를 측정하는 데 사용될 수 있음을 관찰했습니다. 왜냐하면 decoder는 학습이 진행됨에 따라 탐지하기에 유리한 encoder 출력 토큰의 부분집합이 점진적으로 attend하기 때문입니다. 이에 decoder cross attention map에 의해 정의된 salient GT를 예측하는 scoring network를 도입하고, 이를 사용하여 어떤 인코더 토큰이 즉석(on the fly)에서 추가로 정제되어야 하는지를 결정합니다.

위 그림 2.는 scoring network를 학습하는 방법을 요약합니다. 각 encoder input token x의 salient를 측정하기 위해, 모든 object queries와 encoder 출력 사이의 decoder cross attention을 집계합니다. 이 절차는 backbone으로부터의 feature map과 동일한 크기의 단일 맵을 생성하며, 이는 Decoder cross-Attention Map(DAM)으로 정의됩니다. dense attention의 경우, DAM은 모든 decoder layer의 attention map을 통해 쉽게 얻을 수 있습니다. deformable atteniton의 경우, 각 encoder token에 대해, attention offset이 해당 encoder 출력 토큰으로 향하는 decoder object queries의 attention score를 누적하여 DAM을 구할 수 있습니다.
scoring network를 학습시키기 위해, 상위 ρ% 인코더 토큰만 유지되도록 DAM을 이진화(binarize)하며, 이는 각 encoder token이 decoder에 의해 얼마나 참조될지를 정밀하게 예측하는 것이 아니라, decoder가 가장 많이 참조하는 작은 encoder 토큰 부분집합을 찾는 것이기 때문입니다. 이 이진화된 DAM은 각 encoder 토큰이 상위 ρ% 가장 많이 참조된 encoder token에 포함되는지 여부를 나타내는 one-hot target을 의미합니다. 그 후, 주어진 encoder token이 상위 ρ% 가장 많이 참조된 토큰에 포함될 가능성을 예측하기 위해 4-layer scoring network g를 이용하여 다음과 같이 BCE loss를 최소화함으로써 학습됩니다:

학습 초기 단계의 DAM이 정확하지 않기 때문에, decoder 결과에 기반하여 encoder tokens들을 제거하는 것은 최종 성능을 저하시키거나 수렴을 해칠거라고 생각할 수 있지만, 경험적으로 학습 초기 단계에서도 최적화가 매우 안정적이며, objectness 점수에 기반한 방법과 비교하여 더 나은 성능을 달성함으로 관찰했습니다.
Additional Components
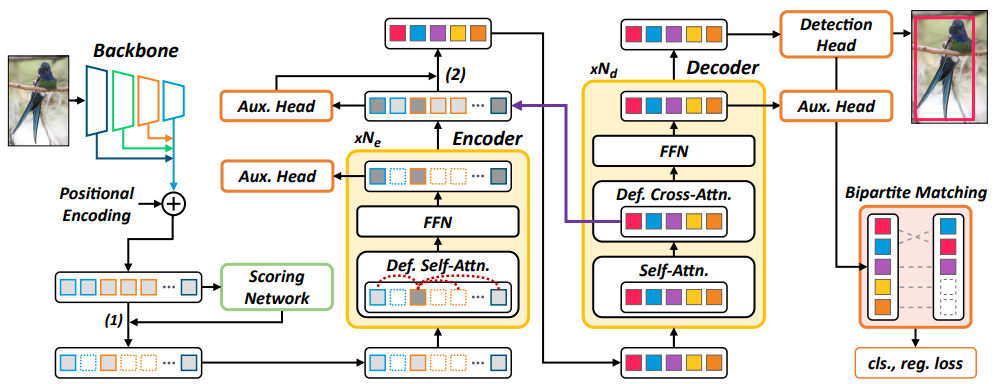
이에 더해 다음은 두 가지 구성 요소를 추가합니다(위 그림 3. 참고):
- encoder aux loss: DETR 변형 모델들에서, aux detection head는 decoder layer에 부착되지만 encoder layer에는 부착되지 않습니다. decoder token(예: 300개)에 비해 훨씬 더 많은 수의 encoder token 때문에, encoder aux head는 계산 비용을 크게 증가시킵니다. 그러나 Sparse DETR은 encoder token의 일부만 refine되며, sparse encoder token에 대해서만 aux head를 추가하는 것은 큰 부담이 아닙니다. 선택된 token들에 대해서 hungarian loss와 함께 aux detection head를 적용하는 것이 gradient vanishing 문제를 완화하여 더 깊은 encoder의 수렴을 안정화시키고 탐지 성능을 향상시킨다는 것을 경험적으로 관찰했습니다.
- top-k decoder queries: DETR과 Deformable DETR에서, decoder queries는 학습 가능한 object queries만으로 주어지거나 encoder 이후 또 다른 head를 통해 예측된 reference point와 함께 주어집니다. Efficient DETR에서 decoder는 RoI pooling과 유사하게 encoder의 출력 일부를 입력으로 받습니다. 여기서, aux detection head가 encoder 출력 x_enc에 부착되고 이 head는 각 encoder의 출력 objectness score를 계산합니다. 이 점수에 기반하여, top-k개의 encoder 출력이 decoder queries로 전달되는데, 이는 objectness encoder sparsification과 유사합니다. 이것이 학습 가능한 object queries에 기반한 방법이나 two-stage 방식보다 성능이 우수하기 때문에, top-k decoder queries selection을 사용합니다.
Experiments.
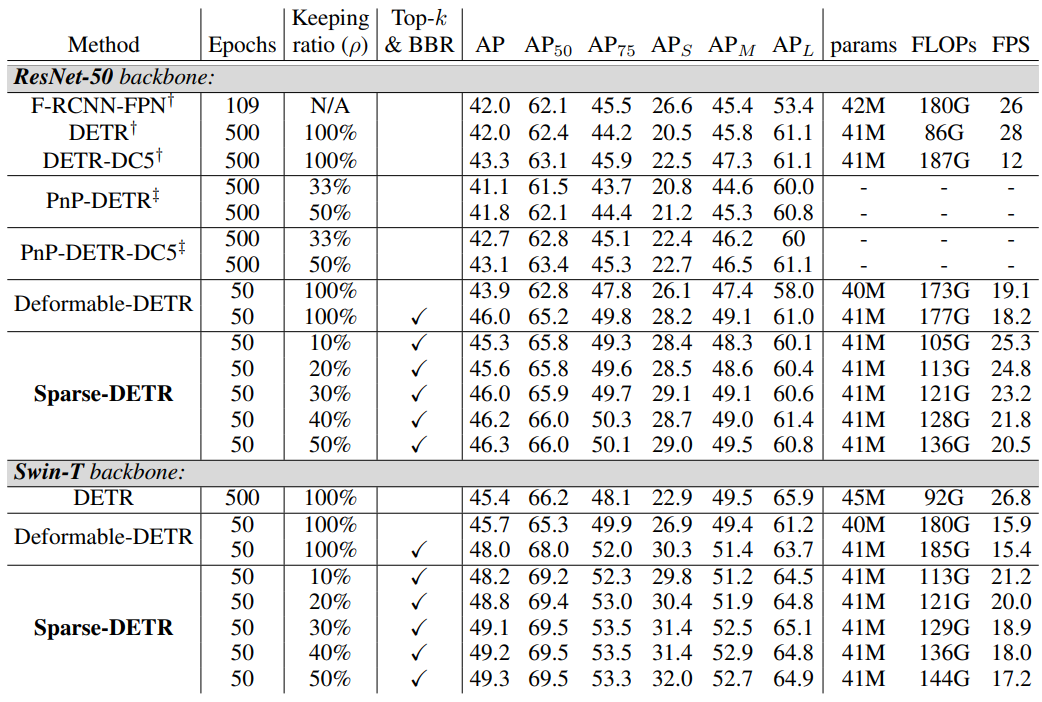
표 1.은 COCO val2017에서 Sparse DETR과 다른 baseline들의 결과입니다.

그림 4. 는 encoder token sparsification 전략들의 비교 결과입니다. OS(objectness selection)보다는 DAM이 더 나으며, 50%의 encoder token만을 refine해도 Full Query 정도의 성능을 기록할 수 있습니다.

그림 5. 는 DAM 기반 모델의 Corr과, OS 기반 모델의 Corr를 비교한 것으로 Corr은 다음과 같이 계산합니다:

이는 decoder가 참조하는 encoder 토큰과 encoder에 의해서 refine 된 token 사이의 중첩을 측정하는 지표입니다.