
https://arxiv.org/abs/2201.12329
DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR
We present in this paper a novel query formulation using dynamic anchor boxes for DETR (DEtection TRansformer) and offer a deeper understanding of the role of queries in DETR. This new formulation directly uses box coordinates as queries in Transformer dec
arxiv.org
Abstract.
본 논문에서 DETR(DEtection TRansformer)을 위한 동적 앵커 박스(dynamic anchor boxes)를 사용하는 새로운 query formulation을 제안하고, DETR 내 query의 역할에 대한 더 깊은 이해를 제공합니다. 이 새로운 formulation은 box 좌표를 transformer decoder queries로 직접 사용하며, layer-by-layer 이를 동적으로 업데이트 합니다. box 좌표를 사용하는 것은 explicit positional priors를 사용하여 query와 feature간의 유사도를 개선하고 DETR의 느린 학습 수렴 문제를 제거하는 데 도움을 줄 뿐만 아니라, box의 너비와 높이 정보를 사용하여 위치 attention map을 modulate할 수 있습니다. 이러한 설계는 DETR의 queries가 soft RoI pooling을 cascade 방식으로 층별로 수행할 수 있게 합니다.
Introduction.
object detection은 넓은 응용 분야를 가진 computer vision 분야의 근본적인 과제입니다. 대부분의 고전적인 detector들은 convolutional architectures들을 기반으로 하며 발전을 이뤘습니다. 최근(2020년)에는 DETR이라 불리는 transformer 기반의 end-to-end detector가 나왔으며, 이는 anchor와 같은 수작업으로 설계된 구성 요소의 필요성을 제거하고 Faster RCNN과 같은 현대적인 anchor-based detector들과 비교하여 괜찮은 성능을 보입니다.
anchor-based detector들과 대조적으로, DETR은 object detection을 set prediction 문제로 모델링하고, 이미지로부터 특성을 탐색하고 pooling하기 위해 100여개의 학습 가능한 queries를 사용합니다. 이는 NMS를 사용할 필요 없이 예측을 수행합니다. 그러나 queries의 비효율적인 설계와 사용으로 인해, DETR은 상당히 느린 학습 수렴을 겪으며, 좋은 성능을 달성하기 위해 보통 500epochs을 필요로 합니다.
대부분의 DETR의 빠른 수렴을 위한 시도들은 각 queries들을 특정 공간 위치와 더 명시적으로 연관시키려고 합니다. 예를 들어, Conditional DETR은 이미지 feature들과 더 나은 matching을 위해 content feature에 기반하여 queries를 적응시킴으로써 conditional spatial query를 학습합니다. Efficient DETR은 top-k개의 object queries를 선택하기 위해 dense prediction module을 사용하며, Anchor DETR은 query를 2D anchor point로 formulate합니다. 유사하게 Deformable DETR은 2D reference points들을 queries로 직접 사용하며, 각 reference points에서 deformable cross-attention 연산을 수행합니다. 그러나 위 모든 연구들은 객체의 scales에 대한 고려 없이 2D 위치만을 anchor point로 사용합니다.
본 논문에서는 anchor box, 즉 4D box 좌표 (x, y, w, h)를 DETR의 query로 사용하고 이를 층별로 업데이트할 것을 제안합니다. 이 새로운 query formulation은 각 anchor box의 위치와 크기를 모두 고려함으로써 cross-attention module을 위한 더 나은 공간적 사전 정보를 도입합니다.
이런 formulation의 핵심 통찰은 DETR의 각 query가 두 부분, 즉 content feature(decoder의 self-attention 출력)와 positional feature(DETR의 학습 가능한 object queries)로 나뉜다는 것입니다. cross-attention score는 queries를 key와 비교하여 계산되는데, 이 key set 또한 content feature와 positional feature로 나눌 수 있습니다. 따라서 transformer decoder내의 queries는 content와 position을 모두 고려하는 query-to-feature 유사도 측정에 기반하여 feature map으로부터 feature를 pooling하는 것으로 해석할 수 있습니다. content 유사도는 의미적으로 관련된 feature를 pooling하기 위한 것인 반면, positional 유사도는 query 위치 주변의 feature들을 pooling하기 위한 positional constraint를 제공하기 위한 것입니다.
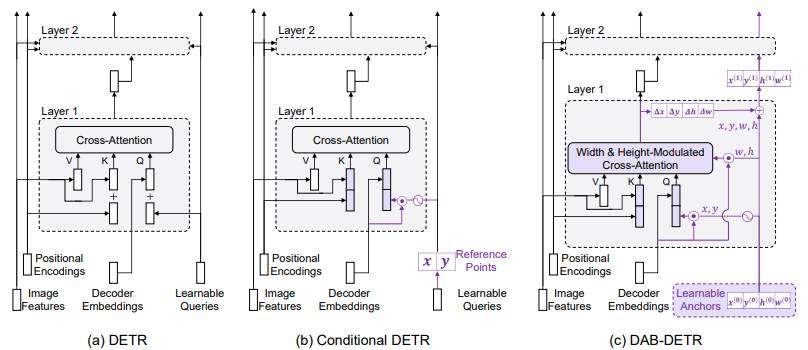
이러한 attention computation mechanism은 위 그림 1.(c)에서 묘사된 것과 같이 anchor box를 fomulation하도록 하는데, 이는 anchor box의 중심 위치 (x,y)를 사용하여 중심 주변의 feature들을 pooling하고, anchor box 크기 (w,h)를 사용하여 cross-attention map을 변조(modulate)함으로써 anchor box 크기에 적응시키는 것을 가능하게 합니다. 게다가 좌표를 query로 사용하기 때문에, anchor box들은 층별로 동적으로 업데이트 될 수 있습니다. 이러한 방식으로, DETR의 queries는 soft RoI pooling을 계단식 방식으로 층별로 수행할 수 있습니다.
Note: conditional DETR은 일반 DETR과 달리 attention의 query를 content-aware하게 만들었다는 점이 개선점입니다. 기존의 DETR은 learnable queries가 위치 정보만을 갖고 있으며, 수렴이 완료되면, 각 object queries들은 이미지의 특정 위치를 가르키는 고정 벡터가 됩니다(그렇게 수렴하게 됩니다). 따라서 test시 어떤 이미지가 들어오든 object queries는 학습 때 수렴된 위치만을 가르키는 query가 됩니다. 한편, conditional DETR의 경우는 content feature에 Linear layer를 추가하여, 이미지의 content를 보고 위치를 정해주는 방식으로 추론하게 됩니다.
본 논문에서 cross-attention을 modulate하기 위해 anchor box 크기를 사용함으로써 feature pooling을 위한 더 나은 positional prior를 제공합니다. cross-attention은 전체 feature map으로부터 feature를 pooling할 수 있기 때문에, cross-attention module이 target object에 해당하는 local region에 집중하도록 각 queries에 적절한 위치적 정보를 제공하는 것이 중요합니다. 이것은 또한 DETR의 학습 수렴을 가속화할 수 있는데, 대부분의 이전 연구들은 각 queries를 특정 위치와 연관시켜 DETR을 개선하지만, 그들은 고정된 크기의 isotropic Gaussian(등방성 가우시안) 위치 사전 정보를 가정하는데, 이는 서로 다른 scale의 객체들에 대해서는 부적절합니다.
Note: 왜 기존의 DETR attention은 isotropic gaussian을 가정한다고 했을까요? 일반적인 attention은 content feature간의 내용 유사도만을 비교합니다. 하지만 DETR은 Q와 K에 대해서 positional encoding 값을 넣어준 후 attention을 수행합니다(concat으로 positional part와 content part를 나눠도 성질은 유지됩니다):

이에 대해서 attention을 수행하면 다음과 같이 분해할 수 있습니다:

Q_pos와 K_pos를 만들때는 sine, cosine 함수를 이용하며, 두 sine, cosine 함수들의 곱은 삼각함수의 덧셈 정리인 cos(α-β)와 유사한 형태가 됩니다. 즉, 두 점 사이의 거리가 유사하면 최대값인 1이, 멀어지면 값이 작아지는 것입니다. 한편, 이는 isotropic gaussian을 가정합니다. 위, 아래, 양 옆 상관없이 거리가 동일하게 떨어지면 positional similarity가 동일하게 낮게 되는 것입니다. 이는 물체의 모양을 고려하지 않은 것으로, 예를 들어 사람의 경우 위 아래로 길고 옆으로 좁습니다. 따라서 원형 가우시안을 가정하면, 사람의 머리와 발은 범위 밖이라 낮은 positional 가중치를, 옆의 배경을 불필요하게 높은 positional 가중치를 갖게 됩니다. 이런 문제를 해결하기 위해, attention score를 계산할 때, x축 방향의 차이는 w로 나누고, y축 방향의 차이는 h로 나눕니다(추후 언급).
각 queries anchor box에서 이용 가능한 크기 정보 (w,h)를 가지고, 가우시안 위치 사전 정보를 타원 형태로 변조할 수 있습니다. 본 논문에서 cross-attention score에서 너비와 높이를 x 부분과 y 부분으로 나누는데, 이는 가우시안 사전 정보가 서로 다른 스케일의 객체들과 더 잘 매칭되도록 돕습니다. 또한 위치적 사전 정보를 더욱 개선하기 위해, 위치 attention의 flatness를 조정하기 위해 temperature parameter를 도입합니다.
요약하자면, DAB-DETR(Dynamic Anchor Box DETR)은 anchor를 queries로 직접 학습합니다. 이는 queries의 역할에 대한 더 깊은 이해를 제공하며, transformer decoder 내 positional cross attention map을 변조(modulate)하기 위해 anchor 크기를 사용하고, 층별 동적 anchor update를 가능하게 합니다.
Related Work.
대부분의 고전적인 detector들은 anchor box나 anchor point를 사용하는 anchor-based입니다. 이와 대조적으로 DETR은 학습 가능한 벡터 집합을 queries로 사용하는 anchor-free detector입니다. 많은 후속 연구들이 DETR의 느린 수렴 문제를 해결하고자 했으며, 이에 대한 한 방향은 DETR 내 queries의 역할에 대한 깊은 이해입니다. DETR의 학습 가능한 queries들은 feature pooling을 위한 위치적 제약(positional constraints)을 제공하는 데 사용되므로, 대부분의 관련 연구들은 DETR의 각 queries들을 특정 공간 위치와 더 명시적으로 연관시키려고 했습니다. 본 논문에서는 queries에 포함된 모든 정보는 box 좌표라는 관점을 따라 anchor box 자체가 DETR의 queries로서 동작합니다.
(... 다른 연구들 ...)
Why a Positional Prior Could Speedup Training?
DETR의 학습 수렴 속도를 가속화하기 위해 많은 연구가 수행되었습니다. Sun et al. (2020)은 cross-attention module이 느린 수렴의 주된 원인임을 보여주며, 그들은 더 빠른 학습을 위해 decoder를 제거했습니다. decoder의 cross-attention과 encoder의 self-attention을 비교하면 아래의 그림 2.와 같은 차이점이 있습니다:
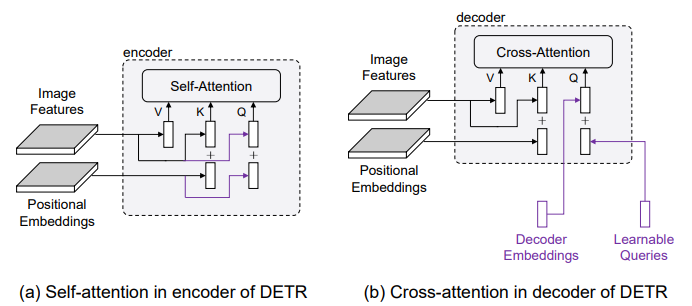
decoder의 임베딩은 0으로 초기화되므로, 첫 번째 cross-attention module 이후에 image feature와 동일한 공간으로 투영됩니다. 그 후, decoder layer는 encoder layer에서의 image feature들 간의 연산과 매우 유사한 과정을 거치므로, 느린 수렴의 근본적인 원인은 learnable queries에 있을 가능성이 높습니다.
Note: 왜 그렇게 판단할 수 있을까요? DETR decoder의 입력은 content query와 object query가 합쳐져서 들어갑니다. 이때 decoder의 첫 번째 layer의 입력에서는 content query는 0-vector이므로, object query(위치)만을 이용해서 image feature의 특정 부분을 pooling합니다. 즉, object query의 위치에 해당하는 image feature값을 그대로 가져오는 것이기 때문에, 이후 decoder의 cross-attention은 encoder에서의 self-attention과 수학적으로 별반 다르지 않습니다. 만약 cross-attention과 self-attention의 결과가 차이가 난다면, 이는 learnable queries 때문이라고 생각할 수 있습니다.
cross-attention에서 모델의 느린 학습 수렴을 설명하는 두 가지 가능한 이유는 다음과 같습니다:
- 최적화의 어려움으로 인해 queries를 학습하기 어렵다는 점.
- 학습된 queries 내의 위치 정보가 image feature에 사용된 sinusoidal positional encoding과 같은 방식으로 encoding되지 않았다는 점.
첫 번째 이유가 맞는지 확인하기 위해, DETR에서 잘 학습된 query를 재사용한 후, 다른 모듈들만 학습시켰습니다:

그림 3. (a)의 학습 곡선은 고정된 queries가 매우 초기 epoch에서만 수렴을 약산 향상 시킨다는 것을 보여줍니다. 따라서 query의 학습과 관련된 이유는 느린 수렴의 이유가 아닐 가능성이 높습니다.
두 번째 가능성이 맞는지 확인하기 위해, 아래의 그림 4.와 같이 학습된 queries와 image feature간의 attention map을 시각화 합니다:

학습된 queries는 특정 영역의 객체를 필터링하는 데 사용되므로, 각 query는 decoder가 관심 영역에 집중하도록 하는 positional prior로 간주할 수 있습니다. 위 그림 4.를 보면 DETR의 경우 multi-mode와 거의 균일한 attention weights와 같은 특징들이 나타납니다. 이는 이미지에 여러 객첵가 존재할 때 객체의 위치를 파악하게 하기 힘들게 하거나, 너무 크거나 작은 지역에 attention weights가 몰려있어, feature pooling과정에 유용한 positional 정보를 주입할 수 없습니다.
본 논문의 저자들은 DETR queries의 이런 특징들이 느린 학습의 원인일 가능성이 높다고 추측하며, queries를 local region으로 제한하기 위해 명시적인 위치적 사전 정보를 도입하는 것이 바람직하다고 가정합니다.
DAB-DETR.

본 논문에서는 위 그림 5.와 같이 주로 DETR의 decoder 부분을 개선합니다. 이미지가 주어지면, CNN backbone을 이용하여 image spatial feature를 추출하고, transformer encoder가 CNN feature를 정제합니다. 그 후, object queries와 content queries를 포함하는 dual queries가 decoder에 입력되어, anchor에 대응하고 content queries와 유사한 패턴을 갖는 객체들을 탐색합니다.
앞서 언급했듯이, DAB-DETR은 query box, 즉 anchor box를 직접 학습하고 이 anchor들로부터 positional queries들을 유도합니다. 각 decoder layer에는 self-attention module과 cross-attention module이 있으며, 이들은 각각 queries update와 feature pooling에 사용됩니다. A_q를 q번째 anchor(x_q, y_q, w_q, h_q) 로 표기하며, C_q와 P_q는 그에 대응하는 content query와 position query입니다. 이때 A_q가 주어지면, 그 position query P_q는 다음과 같이 생성됩니다:

여기서 PE는 float numbers로부터 sinusoidal embedding을 생성하는 position encoding을 말하며, MLP의 파라미터는 모든 layer에서 공유됩니다. PE 연산자는 다음과 같이 overloading합니다:
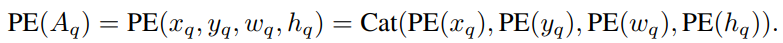
Cat은 concatenation을 말하며, PE는 실수를 D/2 차원을 갖는 vector로 매핑합니다. 따라서 위 함수 MLP는 2D 차원의 벡터를 D 차원으로 투영시키는 MLP입니다. MLP는 하나의 linear layer와 ReLU activation으로 구성됩니다. self-attention module에서 query, key, value 세 가지 모두 동일한 content query를 갖지만, query와 key는 추가적인 position query를 갖습니다:
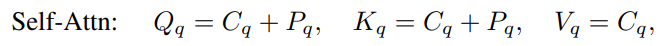
Conditional DETR에서 영감을 받아, cross-attention module에서는 query와 keyy의 position query와 content query를 concat하여, query와 key의 내적으로 계산되는 query-feature 유사도에 대한 content와 position에 대한 기여를 분리할 수 있습니다(위에서 봤던 내적 식에서 덧셈이 아닌 concat을 사용하면, content-position relation term은 사라지게 됩니다).
또한 conditional spatial query를 사용하며, 이를 위해 content 정보에 조건부인 vector를 얻기 위해 MLP를 추가합니다. 그리고 이를 사용하여 PE와 element-wise multiplication을 수행합니다:
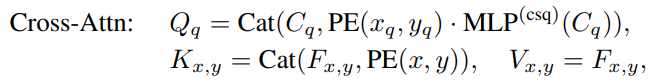
Note: 기존 DETR에서는 position 정보와 content 정보를 단순히 더했습니다. 하지만 CSQ의 핵심 아니디어는 '우리가 찾으려는 물체의 content에 따라, position을 해석하는 방식이 달라져야 한다'는 것입니다. MLP(C_q)는 scale factor로서 PE의 각 성분을 얼마나 증폭하거나 억제할지를 결정하는 scale로 동작합니다. 따라서 PE⊙MLP(C_q)를 하면, 변조된 위치 벡터가 됩니다.
한편, 학습을 위해 좌표를 query로 사용하는 것은 queries들을 layer 별로 업데이트하는 것을 가능하게 합니다. 따라서 위 그림 5.에서 볼 수 있듯, prediction head에 의해 상대적 위치(delta x, delta y, ...)등을 예측한 후 각 layer에서 anchor를 업데이트 합니다(이는 Deformable DETR에서 decoder의 layer별 prediction head를 통해 regression을 refine하는 것과 유사합니다:)
[CoIn] 논문 리뷰 | DEFORMABLE DETR: DEFORMABLE TRANSFORMERSFOR END-TO-END OBJECT DETECTION (Zhu et al., 2021)
https://arxiv.org/abs/2010.04159 Deformable DETR: Deformable Transformers for End-to-End Object DetectionDETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. Howev
hw-hk.tistory.com

전통적인 positional attention map은 위 그림 6.의 왼쪽 그림과 같이 gaussian-like prior로 사용됩니다. 그러나 이 사전 정보는 단순히 모든 객체에 대해 등방성(isotropic)이고 고정된 크기라고 가정되므로, 객체의 scale 정보가 무시된 채로 남습니다. 따라서 이를 개선하기 위해 attention map에 scale 정보를 주입합니다. 원래의 positional attention map에서 query-key 유사도는 두 좌표 인코딩의 내적의 합으로 계산됩니다:

여기에 gaussian prior를 부드럽게 하여 서로 다른 스케일의 객체들과 더 잘 매칭되도록 만들기 위해, 상대적 anchor 너비와 높이를 x부분과 y부분에서 각각 나눔으로써 positional attention map을 변조(modulate)합니다:

w_q,ref와 h_q,ref는 다음과 같이 계산되는 참조 너비와 높이입니다:

Note: PE·PE에 scaling fator로 1/w_q와 1/h_q를 사용하는 이유가 무엇일까? 위의 식인 modulated positional attention은 softmax를 통과하기 전의 logit 값을 계산하는 식입니다. 만약 w_q가 크다면(object가 좌 우로 큰 물체), x좌표에 대해서는 logit들이 전체적으로 낮아지며, 이는 마치 logit에 temperature를 높이는 것과 같이 softmax 후의 score가 넓게 퍼지는 효과를 냅니다. h_q도 마찬가지로 동작합니다. 한편, w_q,ref, h_q,ref를 통해 content를 봤을 때 attention map을 추가로 modulate 할 수 있도록 scaling factor를 추가합니다.
아래의 그림 7.은 temperature별 positional attention map입니다:
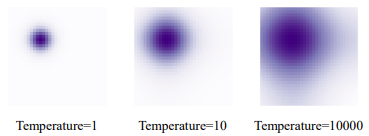
본 논문에선는 다음과 같은 PE 함수를 사용합니다:

Experiments.
(... 좋은 성능 ...)