
https://arxiv.org/abs/2203.01305
DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
We present in this paper a novel denoising training method to speedup DETR (DEtection TRansformer) training and offer a deepened understanding of the slow convergence issue of DETR-like methods. We show that the slow convergence results from the instabilit
arxiv.org
Abstract.
DETR의 학습 속도를 높이는 DeNoising 방법을 제안합니다. 본 논문의 저자는 누린 수렴이 학습 초기 단계에서 일관성 없는 최적화 목표를 만드는 bipartite graph matching의 불안정성에서 기인함을 밝혀냈습니다. 이 문제를 해결하기 위해, hungarian loss 외에, 노이즈가 섞인 GT bbox를 transformer decoder에 추가로 입력하고 모델이 원본 상자를 복원하도록 학습시키는데, 이는 bipartite graph mathcing의 어려움을 효과적으로 줄이고 더 빠른 수렴으로 이끕니다.
Introduction.
이전 고전적인 detector들과 대조적으로, DETR은 transformer encoder의 출력으로부터 이미지 특성을 탐색하기 위해 learnable queries를 사용하고, set-based bbox 예측을 수행하기 위해 bipartite graph matching을 사용합니다. 이러한 설계는 수작업으로 설계된 anchor와 NMS를 효과적으로 제거하고 end-to-end 최적화를 가능하게 합니다. 그러나 DETR은 이전 detector들과 비교하여 매우 느린 학습 수렴을 겪는데, 일반적으로 Faster-RCNN 학습에서는 12epochs이 소요되는 반면, COCO detection datasets에서 DETR은 500epochs가 소요됩니다.
많은 연구들이 느린 수렴 문제를 완화하려고 노력했으며, 효율적인 feature probing을 위해 각 DETR의 queries들을 여러 위치가 아닌 특정 공간 위치와 연관시켰습니다. 예를 들어, Conditional DETR은 각 queries를 content part와 positional part로 분리하여, queries가 특정 공간 위치와 명확한 대응 관계를 갖도록 강제합니다. Deformable DETR은 2D reference points들을 queries로 직접 취급하여 cross-attention을 수행합니다. DAB-DETR은 queries를 4D anchor box로 해석하고 layer by layer로 점진적으로 개선하도록 합니다:
[CoIn] 논문 리뷰 | DAB-DETR: DYNAMIC ANCHOR BOXESARE BETTER QUERIES FOR DETR (Liu et al., 2022)
https://arxiv.org/abs/2201.12329 DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETRWe present in this paper a novel query formulation using dynamic anchor boxes for DETR (DEtection TRansformer) and offer a deeper understanding of the role of querie
hw-hk.tistory.com
[CoIn] 논문 리뷰 | DEFORMABLE DETR: DEFORMABLE TRANSFORMERSFOR END-TO-END OBJECT DETECTION (Zhu et al., 2021)
https://arxiv.org/abs/2010.04159 Deformable DETR: Deformable Transformers for End-to-End Object DetectionDETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. Howev
hw-hk.tistory.com
이러한 진전에도 불구하고, 더 효율적인 학습을 위해 bipartite graph matching 부분을 수정한 연구는 거의 없었습니다. 본 논문에서는 느린 수렴 문제가 discrete bipartite graph matching 구성 요소에서도 기인함을 발견했는데, 이는 확률적 최적화(stochastic optimization)의 특성으로 인해 학습 초기 단계에서 불안정합니다. 결과적으로, 동일한 이미지에 대해 queries가 종종 서로 다른 epoch에서 서로 다른 object와 매칭되는데, 이는 최적화를 ambiguous하고 inconstant하게 만듭니다(추후 언급).
이 문제를 해결하기 위해, bipartite graph matching을 안정화하는 데 도움을 주는 query denoising task를 도입합니다. 이전 연구들이 queries들을 위치 정보를 포함하는 reference points나 anchor box로 해석하는 것에서 효과를 보였으므로, 본 논문에서도 4D anchor box를 queries로 사용합니다. 해결책은 노이즈가 섞인 GT bbox를 noised queries로서 학습 가능한 anchor queries와 함께 transformer decoder에 입력하는 것입니다. 두 종류의 queries들 모두 (x, y, w, h)라는 동일한 입력 형식을 가지며, transformer decoder에 동시에 입력될 수 있습니다.
noised queries에 대해서, 그것들에 대응하는 GT 상자를 복원하는 DeNoising task를 수행하빈다. 다른 학습 가능한 anchor queries에 대해서는 vanilla DETR에서처럼 동일한 학습 손실과 bipartite matching을 수행합니다. noised queries들은 bipartite matching을 거칠 필요가 없으므로, DeNoising task는 더 쉬운 aux task로 간주될 수 있으며, DETR이 불안정산 discrete bipartite mathcing을 완화하고 bbox 예측을 더 빠르게 학습하도록 돕습니다. 한편, 추가된 무작위 노이즈는 대개 작으므로 DeNoising task는 최적화 난이도를 낮추는 데 도움을 줍니다. 또한 각 decoder queries를 bbox + class label embedding으로 간주하여 box denoising과 label denoising을 모두 수행합니다.
요약하자면, 본 논문에서 제안한 방법은 DeNoising training approach입니다. 손실 함수는 복원 손실(reconstruction loss)이고 다른 하나는 다른 DETR들에서 사용한 hungarian loss입니다.
Related Work.
(... 관련 연구들 ...)
Why DeNoising Accelerates DETR Training?
hungarian matching은 graph matching에서 사용하는 알고리즘 입니다. cost matrix가 주어지면, 이 알고리즘은 최적의 matching 결과를 출력합니다. DETR은 예측된 객체와 GT 객체 사이의 matching 문제를 해결하기 위해 객체 탐지에 hungarian matching을 채택했습니다. DETR은 정답 할당을 동적인 과정으로 바꾸는데, 이는 discrete한 bipartite matching과 확률적(stochastic) 학습 과정으로 인한 불안정성 문제를 야기합니다.
Note: 이를 자세히 설명하면 다음과 같습니다. 기존 탐지기(예: Faster-RCNN, YOLO)는 정적으로 정답을 할당합니다. 즉, anchor box와 GT가 겹치는 영역(IoU)가 0.5 이상이면 무조건 매칭이며, 학습 내내 (기준이) 변하지 않습니다. 반면, DETR은 동적입니다. queries들이 예측한 값과 GT 사이의 비용을 계산해서 가장 싼 조합을 찾습니다. 이때 queries의 예측값은 학습(SGD)에 의해 매번 바뀔 수 있습니다. 즉, 저번에는 1번 query가 사과를 맡았는데, 이번에는 2번 query가 사과를 맡을 수도 있습니다. 이렇게 확률적으로 학습하지만 매칭은 이산적(discrete)으로 이뤄집니다. hungarian algorithm은 매칭이 된다/안 된다의 두 가지 뿐이며, 0.5 만큼 매칭 같은 건 없습니다.
Note: 예를 들어, GT가 있을 때, query A의 비용이 0.5, query B의 비용이 0.51이면, GT는 A와 매칭이 됩니다. 다음 epoch에 SGD에 의해 확률적으로 파라미터가 업데이트 되어서 query A의 예측이 아주 조금 나빠졌습니다. query A의 비용이 0.52, query B의 비용이 0.51이 되었다면, GT는 query B와 매칭됩니다. 비용은 고장 0.02 차이인데, 역할은 완전히 바뀌었습니다. 이는 학습시 문제가 되는데, query의 입장에서는 loss function이 계속 바뀌는 것이기 때문입니다.
DETR 모델들의 학습 과정을 '좋은 앵커' 학습하기와 상대적 오프셋(relative offsets) 학습하기의 두 단계로 나눌 수 있습니다. decoder queries들은 anchor 학습을 담당하며, 위에서 설명한 일관성 없는 anchor의 업데이트는 relative offsets 학습을 어렵게 만들 수 있습니다. 따라서, relative offsets 학습을 더 쉽게 만들기 위해 denoising task를 활용하는데, 이는 bipartite matching을 우회하기 때문에, anchor가 일관성 없이 바뀌지 않기 때문에, relative offsets만을 학습할 수 있습니다.
Note: 좋은 anchor 학습하기는 object queries가 GT와 어느 정도 겹치거나 매우 가까운 위치에 자리를 잡도록 학습하는 것을 말합니다. 그 후 offsets을 학습하는데, 이는 object queries에서 얼마나 더 움직여야 더욱 정확해지는지를 학습하는 것입니다. 하지만 SGD에 의해 GT가 되는 anchor가 일관성 없이 계속 바뀐다면, queries는 relative offsets을 학습할 겨를이 없습니다. 그래서 DN task를 맡는 queries는 relative offsets을 학습하는데 집중시키기 위해 불안정한 bipartite matching을 skip합니다.
bipartite matching 결과의 불안정성을 정량적으로 평가하기 위해, 다음과 같은 metric을 설계합니다. 하나의 학습 이미지에 대해, i-th epoch에서 transformer decoder로부터 예측된 객체들을 O^i라고 부르며, 정답 객체들을 T라고 표기합니다. bipartite matching이후, i-th epoch의 matching결과를 저장하기 위해 index vector V^i를 다음과 같이 계산합니다:

하나의 학습 이미지에 대한 i-th epoch의 불안정성을 V^i와 V^i-1 사이의 차이로 정의하며, 다음과 같이 계산됩니다:
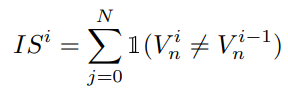
이를 통해 DN-DETR과 DAB-DETR의 IS를 비교합니다:
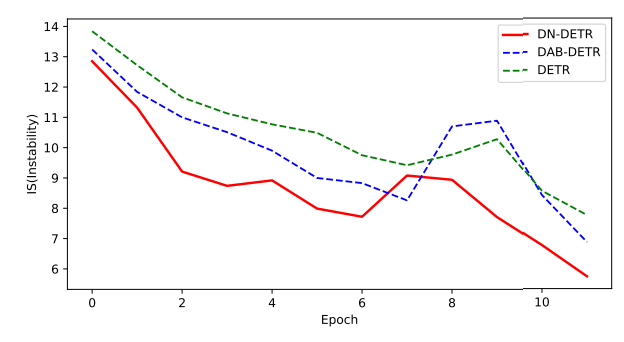
위 그림 2. 는 DN-DETR이 불안정성을 효과적으로 완화할 수 있음을 보여줍니다.
또한 DN-DETR이 anchor와 대응하는 target(GT) 사이의 거리를 줄임으로써 detection을 도울 수 있음을 보여줍니다. vanilla DETR은 object queries들이 여러 modes를 가짐을 볼 수 있는데, 이는 queries가 예측된 box를 위해 넓은 영역에서 탐색하게 만듭니다. 그러나 DN-DETR은 object queries와 GT 사이의 훨씬 더 적은 평균 거리를 갖습니다:

위 그림 3.은 DAB-DETR과 DN-DETR의 마지막 decoder layer에서의 초기 anchor와 matching된 정답 box 사이의 평균 L1 거리를 계산합니다. DN task는 정답에 가까운 노이즈가 섞인 box로부터 box를 복원하도록 모델을 학습시키고, 모델은 예측을 위해 더 국소적으로(locally) 탐색하게 되며, 이는 각 queries가 근처 영역에 집중하게 만들고 queries들 사이의 잠재적인 예측 충돌을 방지합니다.
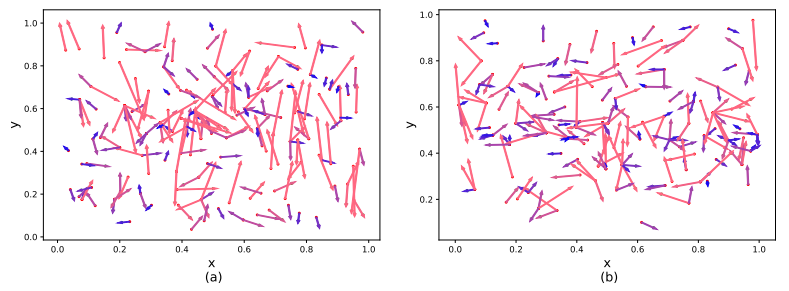
위 그림 4.는 DAB-DETR과 DN-DETR에서의 anchor와 target의 예시입니다.
Note: DN-DETR의 queries과 target 간의 L1 distance가 줄어든건, 애초에 DN-DETR의 queries가 GT에서 noise를 더한 것이기 때문에, 당연히 작은거 아닌가? 하지만 DN queries들은 학습때만 사용될 뿐 평가의 주체는 일반적인 queries들입니다. DN queries들이 존재했기 때문에 일반 queries들도 GT 근처로 갈 수 있었다는 것인데, 이는 DN queries와 일반 queries가 decoder의 가중치를 공유하며, DN queries들을 통해서 relative offsets을 학습할 수 있는 학습 signal의 개수를 늘린 것이라고 볼 수 있습니다.
DN-DETR.
본 논문은 DAB-DETR을 기반으로 하며, 이는 decoder queries들을 box anchor 좌표로 명시적으로 공식화합니다. decoder queries들을 q로, transformer decoder의 출력을 o라고 하며, transformer encoder이후의 정제된 image feature와 denoising task 설계에 기초하여 유도된 attention mask를 각각 F와 A라고 할 때, 다음과 같이 공식화할 수 있습니다:

decoder queries에는 두 부분이 존재합니다. 하나는 matching part입니다. 입력은 학습 가능한 anchor(learnable anchors)이며, DETR에서와 동일한 방식으로 취급됩니다. 즉, matching part는 bipartite graph matching을 채택하고 matching된 decoder 출력을 가지고 GT box-lebel 쌍을 근사하도록 학습합니다. 다른 하나는 denoising part입니다. 입력은 노이즈가 섞인 GT box-lebel 쌍인데, 이를 GT object라고 부릅니다. denoising part의 출력은 GT object를 복원하는 것을 목표로 합니다.
denoising part를 q라고 하며, matching part를 Q라고 했을 때 다음과 같이 공식화할 수 있습니다:

denoising의 효율성을 높이기 위해, denoising part에서 noised GT object의 여러 버전을 사용합니다. 나아가 denoising part에서 matching part로, 그리고 동일한 GT object의 서로 다른 noise 버전들 사이로 정보가 유출되는 것을 방지하기 위해 attention mask를 활용합니다. 전체적인 overview는 아래와 같습니다:

많은 연구들이 DETR queries들을 위치 정보와 연관시키며, DAB-DETR도 각 query를 4D anchor 좌푤로 공식화합니다. 아래의 그림 5. (a)와 같이 queries들은 tuple (x, y, w, h)로 지정되는데, 이는 layer by layer로 동적으로 업데이트 됩니다:

각 decoder layer의 출력은 tuple (Δx, Δy, Δw, Δh)를 포함하며, anchor는 이를 이용해 업데이트 됩니다. DN-DETR은 위 그림 5.(b)에 볼 수 있듯, decoder embedding을 label embedding으로 지정하는 것만 DAB-DETR에서 수정합니다.
각 이미지에 대해, 모든 GT object들을 수집하고, 그것들의 bbox와 class label 모두에 무작위 노이즈를 추가합니다. 그리고 denoising 학습의 효용을 극대화하기 위해, GT object에 대해 여러 개의 노이즈 버전을 추가합니다:
- center shifting: bbox 중심에 무작위 노이즈 (Δ x, Δy)를 더하며, |Δx| < λ_1w/2 그리고 |Δy| < λ_1h/2가 되도록 하는데, 여기서 λ_1이 (0,1)이어야 노이즈가 섞인 bbox의 중심이 여전히 원본 bbox 상자 내부에 놓이게 됩니다.
- box scaling: (0,1)인 λ_2를 설정하여, bbox의 너비와 높이를 각각 [(1-λ_2)w, (1+λ_2)w], [(1-λ_2)h, (1+λ_2)h] 에서 무작위로 샘플링됩니다.
label noising에 대해서, label flipping을 사용하는데, 이는 이부 GT label을 부작위로 다른 label로 뒤집는 것을 말합니다. label flipping은 모델이 label-box 관계를 더 잘 포착하기 위해 노이즈가 섞인 bbox에 따라 GT label을 예측하도록 강제합니다. 뒤집을 label의 비율을 조절하기 위한 하이퍼 파라미터 γ를 가지며, 복원 손실(reconstruction losses)는 DAB-DETR에서와 같이 bbox에 대해서는 l1 loss와 GIoU loss이고, class label에 대해서는 Focal loss입니다. 노이즈가 섞인 GT object를 나타내기 위한 함수 δ()를 사용합니다.
또한 Attention mask를 사용합니다. attention mask를 사용하기 위해, 먼저 노이즈가 섞인 GT objects들을 그룹으로 나누어야 합니다. 각 그룹은 모든 GT objects들의 노이즈 버전입니다:

각 그룹은 M개의 queries들을 포함하며, M은 이미지 내 GT object 수입니다. 따라서 다음을 얻습니다:
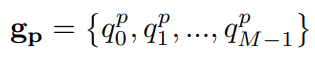
이때 q^p_m = δ(t_m)입니다. attention mask의 목적은 정보 유출을 막는 것입니다. 여기에는 두 가지 유형의 잠재적인 정보 유출이 있는데: 1) matching part가 노이즈가 섞인 GT objects를 보고 쉽게 GT objects를 예측할 수 있다는 것입니다. 또한 2) GT objects의 한 nosied 버전이 다른 버전을 볼 수 있다는 것입니다. 따라서, attention mask는 그림 6.에서 볼 수 있듯, matching part가 denoising part를 볼 수 없게 하고, denoising group들이 서로 볼 수 없게 하는 합니다.
Attention mask A는 W x W matrix로, W = P x M + N이며, P는 그룹의 수, M은 GT 객체의 수이며, N은 matching part의 쿼리의 수입니다. 처음 P x M 개의 행과 열이 denoising part를 나타내며, 뒤에 N개가 matching part를 나타냅니다. a_ij = 1이면 i-th query가 j-th query를 볼 수 없음을 의미하며, 그렇지 않으면 a_ij = 0입니다:
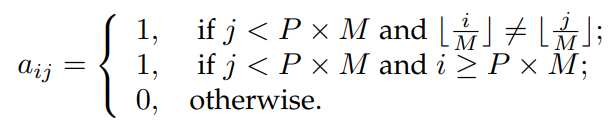
decoder embedding은 box denoising과 label denoising을 모두 지원하기 위해 label embedding을 사용하며, matching part와 denoising part의 일관성을 위해, matching part의 class embedding은 81번째 클래스(COCO 2017은 80개의 클래스가 존재)에 대한 embedding을 넣습니다. 또한 indicator를 추가하여, denoising part에는 1, matching part에는 0을 입력합니다.
(... 나머지는 활용 부분 ...)
Experiment.
(... 논문 참조 ...)