
https://arxiv.org/abs/2203.03605
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
We present DINO (\textbf{D}ETR with \textbf{I}mproved de\textbf{N}oising anch\textbf{O}r boxes), a state-of-the-art end-to-end object detector. % in this paper. DINO improves over previous DETR-like models in performance and efficiency by using a contrasti
arxiv.org
Introduction.
Object detection은 computer vision의 대표적인 task입니다. 고전적인 CNN기반 객체 탐지 알고리즘에 의해 놀라운 발전이 이루어졌지만, 이러한 알고리즘은 anchor 생성이나 NMS와 같이 수작업으로 설계된 구성 요소를 포함하고 있습니다. 이런 고전적인 detection algorithm과 대조적으로, DETR은 새로운 Transformer 기반 탐지 알고리즘입니다. DETR은 수작업으로 설계된 구성 요소(NMS, anchor 생성 등)의 필요성을 제거합니다.
이전의 탐지기들과 달리(M2O matching), DETR은 객체 탐지를 집합 예측(set prediction) 과제로 모델링한 후, bipartite graph matching을 통해 label을 할당합니다. YOLO계열과 DETR계열의 label할당의 차이를 자세히 알고싶다면:
[CoIn] 논문 리뷰 | DEIM: DETR with Improved Matching for Fast Convergence (Huang et al., 2024)
https://arxiv.org/abs/2412.04234 DEIM: DETR with Improved Matching for Fast ConvergenceWe introduce DEIM, an innovative and efficient training framework designed to accelerate convergence in real-time object detection with Transformer-based architectures (
hw-hk.tistory.com
또한 DETR은 learnable queries(학습 가능한 쿼리)를 활용하여 객체의 존재를 탐색하고 feature map의 특징들을 결합하는데, 이는 마치 soft ROI pooling과 같이 동작합니다. 이런 유망한 성능에도 불구하고, DETR은 학습 수렴 속도가 느리고, query의 의미가 불분명하다는 문제가 있었습니다. 이러한 문제들을 해결하기 위해 deformable attention이나 positional 정보와 content 정보의 분리, spatial prior를 제공하는 등 많은 방법들이 제안되었습니다.
최근(2022년) DAB-DETR은 DETR의 query를 dynamic anchor box(DAB)로 공식화하여 고전적인(YOLO기반) anchor-based detector와의 격차를 줄였습니다. 또한 DN-DETR은 denosing(DN) 기법을 사용하여, bipartite matching의 불안정성 문제를 해결했습니다. 하지만, 현재(2022년) SOTA 모델들은 여전히 anchor-based detector입니다. 이러한 상황에는 다음과 같은 이유가 있습니다:
- DETR 계열의 모델들 자체가 성능이 너무 떨어진다. 대부분의 고전적인 detector들은 이미 잘 연구되어 있고, 고도로 최적화되어 있어서 새로 개발된 DETR 계열 모델들에 비해 더 나은 성능을 이끌어냅니다.
- DETR 계열 모델들의 scalability가 잘 연구되지 않았다. 거대 backbone과 대규모 데이터셋으로 확장했을 때 DETR 계열의 모델들이 어떤 성능을 내는지에 대해 보고된 결과가 없습니다(2022년).
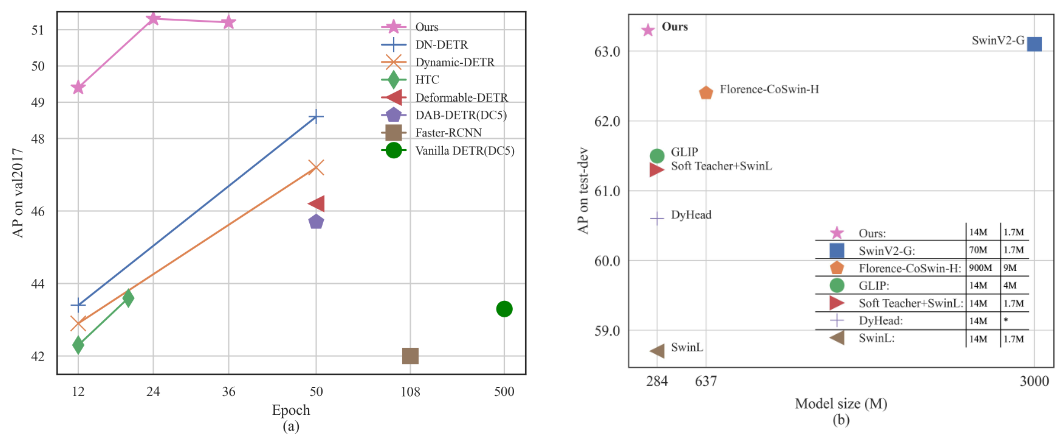
따라서 해당 연구에서는 denosing 학습, query initialization, box prediction 방식을 개선함으로써, DN-DETR, DAB-DETR, Deformable DETR에 기반한 새로운 DETR 계열 모델을 설계했으며, 이를 DINO(DETR with Improved deNoising anchOr box)라고 명명합니다. 아래의 그림 1.에서 볼 수 있듯 우수한 성능을 기록합니다:
DINO는 다음과 같이 기존의 연구들을 사용합니다:
- Following DAB-DETR: decoder 내의 query를 dynamic anchor box로 공식화하고 decoder layer를 거치며 이를 단계적으로 refine합니다.
- Following DN-DETR: 학습 중 bipartite matching을 안정화하기 위해 transformer decoder layer에 GT label과 노이즈가 섞인 box를 추가합니다.
- Following Deformable Attention: 계산 효율성을 위해 deformable attention을 사용합니다.
더 나아가, 다음과 같은 세 가지 새로운 방법을 제안합니다:
- Contrastive Denoising Training: O2O matching을 개선하기 위해, 동일한 정답(GT)에 대해 긍정(positive) 샘플과 부정(negative) 샘플을 동시에 추가하는 방법을 제안합니다. 동일한 정답 박스에 서로 다른 두 가지 노이즈를 추가한 후, 노이즈가 적은 박스는 positive로, 다른 하나는 negative로 표시합니다. 이런 contrastive denoising training은 모델이 동일한 타겟에 대해 중복된 출력을 내는 것을 방지하도록 돕습니다.
- Mixed Query Selection: query의 dynamic anchor box formulation은 DETR 계열 모델을 고전적인 2단계(two-stage) 모델과 연결합니다. 따라서 query를 더 잘 초기화하기 위해 mixed query selection 방법을 제안합니다. encoder 출력에서 초기 anchor box를 positional query로 선택합니다. 하지만 content query는 이전처럼 학습 가능하게 남겨두어, 첫 번째 decoder layer가 spatial prior에 집중하도록 유도합니다.
- Look Forward Twice: 후반부 layer에서 정제된 box 정보를 활용하여 인접한 초기 layer의 파라미터 최적화를 돕기 위해, 후반부 layer의 graidient로 업데이트된 파라미터를 보정하는 look forward twice 기법을 제안합니다.
Related Work.
초기의 CNN 기반 object detector들은 수작업으로 설계된 anchor나 reference points들을 기반으로 하는 two-stage 또는 one-stage 모델들입니다:
- two-stage model: 이 모델들은 주로 RPN(Region Proposal Network)을 사용하여 잠재적인 box를 제안하고, 이들을 두 번째 단계에서 정제(refine)합니다.
- one-stage model: YOLO와 같은 모델들은 미리 정의된 anchor에 대한 offset을 직접 출력합니다.
이런 CNN기반 모델들의 성능은 anchor를 생성하는 방식에 의존하며, 중복된 box를 제거하기 위해 NMS와 같은 수작업으로 설계된 구성요소가 필요하므로, 진정한 의미의 end-to-end 최적화를 달성할 수 없습니다.
한편, DETR은 anchor 설계나 NMS와 같은 수작업 구성 요소를 사용하지 않는 transformer 기반의 end-to-end object detector입니다. 많은 연구들이 decoder의 cross-attention으로 인해 발생하는 DETR의 느린 학습 수렴 속도를 해결하려고 시도했습니다:
- Sun et al. 은 decoder를 사용하지 않는 encoder-only DETR을 설계했습니다.
- Dai et al. 은 여러 feature level에서 중요한 영역에 집중하는 Dynamic Decoder를 제안했습니다.
또 다른 연구의 흐름은 DETR의 decoder query에 대한 이해입니다. 많은 논문들이 quiery를 다양한 관점에서 spartial position과 연관시킵니다:
- Deformable DETR: 이는 2D anchor point를 예측하고, reference point 주변의 특정 sampling points들에만 집중하는 deformable attention 모듈을 설계했습니다.
[CoIn] 논문 리뷰 | DEFORMABLE DETR: DEFORMABLE TRANSFORMERSFOR END-TO-END OBJECT DETECTION (Zhu et al., 2021)
https://arxiv.org/abs/2010.04159 Deformable DETR: Deformable Transformers for End-to-End Object DetectionDETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. Howev
hw-hk.tistory.com
- Efficient DETR: 이는 encoder의 dense prediction에서 상위 K개의 위치를 사용하여 decoder query를 강화합니다.
- DAB-DETR: 이는 더 나아가 query를 표현하기 위해 2D anchor points들을 4D anchor box 좌표로 확장하고, 각 decoder layer에서 box를 동적으로 업데이트 합니다.
[CoIn] 논문 리뷰 | DAB-DETR: DYNAMIC ANCHOR BOXESARE BETTER QUERIES FOR DETR (Liu et al., 2022)
https://arxiv.org/abs/2201.12329 DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETRWe present in this paper a novel query formulation using dynamic anchor boxes for DETR (DEtection TRansformer) and offer a deeper understanding of the role of querie
hw-hk.tistory.com
최근 DN-DETR은 DETR의 학습 속도를 높이기 위해 Denoising 학습 방법을 도입했습니다. 이는 노이즈가 추가된 GT label과 box를 decoder에 입력하고, 모델이 원본을 복원하도록 학습시키는 방식입니다.
DINO: DETR with Improved DeNoising Anchor Boxes.
Preliminaries.
Conditional DETR과 DAB-DETR에서 연구된 바와 같이, DETR의 query는 positional part와 content part로 구성되어 있습니다. 이를 각각 positional queries와 content queries라고 부르며, DAB-DETR은 DETR의 각 positional queries를 4D anchor box (x, y, w, h)로 명시적으로 formulation합니다. 여기서 x와 y는 박스의 중심 좌표이며, w와 h는 너비와 높이에 해당합니다. 이러한 명시적인 anchor box의 공식화는 decoder 내에서 레이어별로 anchor box를 동적으로 정제하는 것을 용이하게 만듭니다.
DN-DETR은 DETR 계열의 모델의 학습 수렴을 가속화하기 위해 DeNoising(DN) 학습 방법을 도입했습니다. 이 연구는 DETR의 느린 수렴 문제가 bipartite matching의 불안정성에 기인함을 보여줍니다. 이 문제를 완화하기 위해, DN-DETR은 noise가 추가된 정답(GT) 라벨과 박스를 transformer decoder에 추가로 입력하고, 모델이 정답을 복원하도록 학습시킬 것을 제안합니다. 추가된 노이즈 (Δx, Δy, Δw, Δh)는 |Δx| < λw/2, |Δy| < λh/2, |Δw| < λw, |Δh| < λh 라는 제약 조건을 갖습니다. 여기서 (x, y, w, h)는 GT 박스를 나타내며, λ는 노이즈의 크기를 조절하는 하이퍼 파라미터입니다. DN-DETR은 DAB-DETR을 따라 decoder query를 anchor로 간주하므로, λ가 일반적으로 작기 때문에 노이즈가 추가된 GT 박스 근처에 GT 박스가 있는 특별한 anchor로 볼 수 있습니다. 원래의 DETR query 외에도, DN-DETR은 노이즈가 추가된 GT 라벨과 박스를 decoder에 입력하여 보조적인 DN loss을 제공하는 DN 파트를 추가합니다. DN loss는 DETR 학습을 효과적으로 안정화하고 가속화하여, 어떤 DETR 계열 모델에도 적용될 수 있습니다.
Deformable DETR은 DETR의 수렴 속도를 높이기 위한 또 다른 초기 연구입니다. deformable attention을 계산하기 위해 reference point라는 개념을 도입하여, deformable attention이 reference point 주변의 적은 수의 핵심 sampling points에만 집중할 수 있게 합니다. reference points 개념은 DETR 성능을 더욱 향상시키기 위한 다음 기법의 개발을 가능하게 했습니다:
- query selection: 이는 encoder의 feature와 reference box를 선택하여 decoder의 입력으로 직접 사용합니다.
- iterative bounding box refinement: 이를 이 논문에서는 look forward once라고 부릅니다.
Model Overview.
DETR 계열 모델로서 DINO는 backbone, multi-layer transformer encoder, multi-layer transformer decoder 그리고 multi-prediction heads를 포함하는 end-to-end architecture입니다. 전체 파이프라인은 다음과 같습니다:

이미지가 주어지면, ResNet이나 Swin Transformer와 같은 backbone으로 multi-scale feature를 추출하고, 이를 해당하는 위치 embedding과 함께 transformer encoder에 입력합니다. encoder layer를 통한 feature enhancement 후, decoder를 위한 positional queries로서 anchor를 초기화하는 Mixed Query Selection Strategy를 사용합니다. 그 후 그렇게 초기화된 anchor와 학습 사능한 contents queries를 사용하며, deformable attention을 통해 encoder 출력의 feature들을 결합하고 query를 layer 별로 업데이트합니다.
DN-DETR에서와 같이, DeNoising 학습을 수행하기 위한 추가적인 DN branch가 있으며, 표준 DN 방법을 넘어, hard negative samples를 고려하는 새로운 contrastive denoising training을 사용합니다. 후반부 layer의 정제된 box 정보를 충분히 활용하여 인접한 초기 layer의 파라미터 최적화를 돕기 위해, 인접 layer간에 gradient를 전달하는 새로운 look forward twice 방법도 사용합니다.
Contrastive DeNoising Training.
DN-DETR은 학습을 안정화하고 수렴을 가속화하는 데 매우 효과적입니다. DN query의 도움으로, 모델은 근처에 GT 박스가 있는 anchor를 기반으로 예측하는 법을 배웁니다. 그러나 근처에 객체가 없는 anchor에 대해 no object를 예측하는 능력은 여전히 부족합니다. 이 문제를 해결하기 위해, 쓸모없는 anchor를 거부하기 위한 contrastive denoising 방식을 사용합니다.
DN-DETR은 노이즈 크기를 조절하기 위한 하이퍼 파라미터 λ를 사용합니다. 생성된 노이즈는 λ보다 크지 않은데, 이는 DN-DETR이 모델이 적당히 노이즈가 섞인 query로부터 GT를 복원하기를 원하기 때문입니다.

CDN은 λ1 < λ2인 두 개의 파라미터 λ1과 λ2를 사용합니다. 위 그림 3. 의 동심 사각형에서 볼 수 있듯이, 두 종류의 CDN query를 생성합니다:
- positive query: 내부 사각형 안에 위치하며 λ1보다 작은 노이즈를 갖습니다. 이들은 해당하는 정답 박스를 복원할 것으로 기대합니다.
- negative query: 내부 사각형과 외부 사각형 사이에 위치하며 λ1보다 크고 λ2보다 작은 노이즈 크기를 가집니다. 이들은 객체 없음(no object)을 예측할 것으로 기대됩니다.
일반적으로 λ2를 작게 설정하는데, 이는 GT 박스에 더 가까운 어려운 negative samples들이 성능 향상에 더 도움이 되기 때문입니다. 그림 3.과 같이 각 CDN 그룹은 positive queries set와 nagetive queries set를 가집니다. 이미지에 n개의 GT 박스가 있다면, 각 GT 박스가 하나의 positive와 하나의 negative query를 생성하여 CDN 그룹은 2 x n 개의 queries를 갖게 됩니다. DN-DETR과 유사하게, 효과를 높이기 위해 여러 개의 CDN 그룹을 사용하며, reconstruction loss로는 box regression을 위한 l1 및 GIOU loss와 classification을 위한 Focal loss를 사용합니다. negative sample을 배경으로 분류하기 위한 loss 또한 Focal loss입니다.
이 방법이 작동하는 이유는 혼동(confusion)을 억제하고 bbox 예측을 위한 고품질의 anchor를 선택할 수 있기 때문입니다. confusion은 여러 anchors가 하나의 객체에 가까울 때 발생합니다. 이 경우는 모델이 어떤 anchor를 선택할지 결정하기 어려우며, 이러한 confusion은 다음의 두 가지 문제를 야기할 수 있습니다:
- duplicated predictions: 비록 DETR 계열의 모델들이 set-based(bipartite matching 기반의) loss와 self-attention의 도움으로 중복 box를 억제할 수 있지만, 이는 제한적입니다.
- 원치 않는 anchor 선택: GT 박스에서 더 멀리 떨어진 원치 않는 anchor가 선택될 수 있습니다. 비록 DN 학습이 모델이 가까운 anchor를 선택하도록 개선했지만, CDN은 모델에게 더 멀리 있는 anchor를 거부하도록 가르침으로써 이 능력을 더욱 향상시킵니다.
CDN의 효과를 입증하기 위해, average top-k distance(ATD) 라는 지표를 정의하고 이를 matching 파트에서 anchor들이 target GT box로부터 얼마나 멀리 떨어져 있는지 평가하는 데 사용합니다. DETR에서와 같이, 각 앵커는 하나의 예측에 대용되며 이는 GT 박스나 배경과 매칭될 수 있습니다. 여기서 GT 박스와 매칭된 것들만 고려합니다.
N개의 GT bbox b_0, b_1, ..., b_N-1이 있고, 각 b_i에 대해 그에 대응하는 anchor를 찾아 a_i라고 표기할 수 있습니다. 이때 ATD는 다음과 같습니다:

아래는 결과입니다:
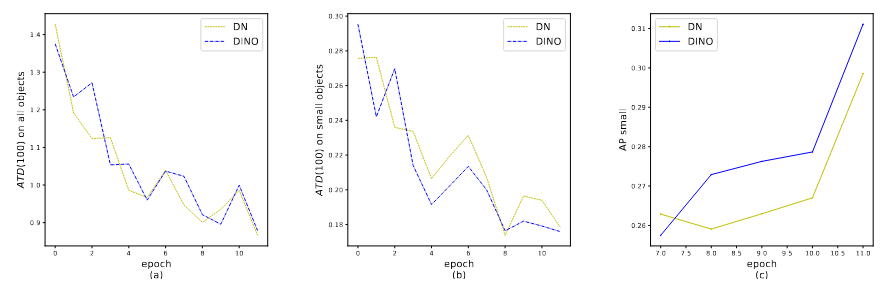
그림 4. (a)와 (b)에서 보듯이, DN은 전반적으로 좋은 앵커를 선택하는 데 충분히 좋습니다. 하지만 CDN은 작은 객체에 대해서 더 잘 찾습니다.
Mixed Query Selection.

DETR과 DN-DETR에서, decoder query는 그림 5. (a)와 같이 개별 이미지의 encoder feature를 전혀 가져 오지 않는 static embedding입니다. deformable DETR은 positional queries와 content queries를 모두 학습하는데, 성능 향상을 위해 deformable DETR은 query selection을 수행하기도 합니다. 이는 마지막 encoder layer에서 상위 k개의 encoder features들을 사전 정보(prior)로 사용하여 decoder queries를 강화합니다. 그림 5. (b)에서 보듯이, positional queries와 content queries 모두 선택된 feature의 linear tranform에 의해 생성됩니다.
DINO에서는 MQS를 통해 그림 5. (c)와 같이, 선택된 상위 K개의 특징과 위치 정보만을 사용하여 anchor box를 초기화하고, content queries는 이전과 같이 static인 상태로 둡니다. deformable attention과 같이 encoder의 top-k feature를 통해 content queries까지 강화하는 것은 encoder에서 선택된 feature들이 추가적인 refinement가 없는 content feature이므로, 모호하거나 decoder에게 오해를 불러일으킬 수 있습니다. 예를 들어, 선택된 feature들은 여러 객체를 포함하거나 객체의 일부분일 수 있습니다.
Look Forward Twice.
Deformable DETR에서 iterative box refinement는 학습을 안정화하기 위해 gradient backpropagation을 차단합니다.

위 그림 6.(a)에 보이는 바와 같이, layer i 의 파라미터들이 오직 box b_i의 aux loss에 기반하여 업데이트되므로, 이 방법은 look forward once라고 부를 수 있습니다. 그러나 더 뒤쪽 layer에서 나온 개선된 box 정보가 그에 인접한 이전 layer의 box 예측을 수정하는 데 도움을 줄 수도 있습니다. 따라서 look forward twice라고 불리는 방법은 제안하는데, 이는 위 그림 6.(b)에 보이는 바와 같이 layer-i 의 파라미터가 layer-i 와 layer-(i+1) 양쪽의 loss에 의해 영향을 받습니다. 각 예측된 offfsets Δb_i에 대해, 이것은 box를 두 번 업데이트 하게 됩니다(b_i'과 b^{pred}_{i+1}).
예측된 box b^{pred}_i의 최종 정밀도는 두 가지 요인에 의해 결정됩니다: 1) 초기 box b_{i-1}의 품질과 2) box의 예측된 offset Δb_i입니다. look forward once는 gradient 정보가 layer-i에서 layer-(i-1)로 흐르지 않기 때문에, Δb_i만을 개선합니다. 대조적으로 본 논문의 방식(look forward twice)은 초기 박스 b_{i-1}과 offsets Δb_i를 모두 개선합니다. i번째 layer에 대한 입력 box b_{i-1}이 주어지면, 다음과 같이 최종 예측 box를 예측합니다:

Experiments.
(... 자세한 내용은 원본 논문 참조 ...)