
https://arxiv.org/abs/2207.13085
Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
Detection transformer (DETR) relies on one-to-one assignment, assigning one ground-truth object to one prediction, for end-to-end detection without NMS post-processing. It is known that one-to-many assignment, assigning one ground-truth object to multiple
arxiv.org
Abstract.
DETR은 NMS 후처리가 없는 end-to-end detector를 위해 하나의 GT 객체를 하나의 예측에 할당하는 one-to-one assignment(O2O)에 의존합니다. 한편 하나의 GT 객체를 여러 예측에 할당하는 one-to-many assignment(O2M)는 Faster R-CNN이나 FCOS 같은 detector에서 사용합니다. 단순한 O2M은 DETR에서 잘 동작하지 않으며, DETR 학습에 O2M를 적용하는 것은 어렵습니다. 본 논문에서는 O2M을 위한 group-wise 방식을 도입하여 간단하면서도 효율적인 DETR 학습법인 Group DETR을 제안합니다.
이는 여러 그룹의 object queries를 사용하고, 각 그룹 내에서 O2O을 수행하며, decoder self-attention을 개별적으로 수행합니다. 이것은 object queries 증강을 이용한 데이터 증강과 유사합니다(예: DN-DETR에서의 DN task). 이는 또한 동일한 아키텍처의 파라미터 공유 네트워크들을 동시에 학습시키는 것과 유사하며, 더 많은 supervision을 도입하여 DETR의 학습을 개선합니다. 추론 과정은 정상적으로 학습된 DETR과 동일하며 어떠한 아키텍처 수정 없이 오직 한 그룹의 queries만 필요합니다.
Introduction.
DETR은 NMS나 anchor 생성과 같은 수작업으로 설계되는 많은 구성 요소들이 필요 없는 end-to-end detection을 수행합니다. 아키텍처는 CNN과 transformer encoder, self-attention, cross-attention, FFN들이 존재합니다. 학습 중에는 하나의 GT 객체가 하나의 단일 예측에 할당되는 O2O이 적용되어, GT 객체에 할당된 예측들만 정답을 맞추도록 학습되며, 중복된 예측들은 배경을 예측하도록 학습합니다.
본 논문에서의 연구는 DETR 학습 과정을 가속화하기 위한 해결책을 탐구합니다. 이전의 해결책들에는 크게 두 가지 노선이 존재합니다:
- image feature로부터 정보를 효과적이고 효율적으로 수집하기 위해 유용한 이미지 영역들이 선택되도록 cross-attention을 수정하는 것입니다. 예시 방법으로는 Deformable-DETR와 sparse sampling으로 object queries들을 refine하는 다양한 방법들이 존재합니다.
[CoIn] 논문 리뷰 | SPARSE DETR: EFFICIENT END-TO-END OBJECT DETECTION WITH LEARNABLE SPARSITY (Roh et al., 2022)
https://arxiv.org/abs/2111.14330 Sparse DETR: Efficient End-to-End Object Detection with Learnable SparsityDETR is the first end-to-end object detector using a transformer encoder-decoder architecture and demonstrates competitive performance but low comput
hw-hk.tistory.com
[CoIn] 논문 리뷰 | DEFORMABLE DETR: DEFORMABLE TRANSFORMERSFOR END-TO-END OBJECT DETECTION (Zhu et al., 2021)
https://arxiv.org/abs/2010.04159 Deformable DETR: Deformable Transformers for End-to-End Object DetectionDETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. Howev
hw-hk.tistory.com
- 학습 중 O2O을 안정화하는 것으로, 예를 들어 노이즈가 섞인 GT bbox를 transformer decoder에 입력하는 것입니다.
[CoIn] 논문 리뷰 | DN-DETR: Accelerate DETR Training byIntroducing Query DeNoising (Li et al., 2022)
https://arxiv.org/abs/2203.01305 DN-DETR: Accelerate DETR Training by Introducing Query DeNoisingWe present in this paper a novel denoising training method to speedup DETR (DEtection TRansformer) training and offer a deepened understanding of the slow conv
hw-hk.tistory.com
본 논문은 두 번째 노선에 관심이 있으며, DN-DETR처럼 할당 자체를 안정화하는 데 초점을 맞추는 대신, 효율적인 DETR 학습을 위해 더 많은 supervision을 사용합니다. 하나의 GT 객체를 여러 예측에 할당하는 것(이를 통해 더 많은 supervision을 확보하는 것), 즉 O2M은 전통적인 object detection 방법들에서 유용함이 입증되었습니다. 하지만, 단순한 O2M은 DETR에서 잘 동작하지 않으며, 이는 과제로 남아있습니다.
이에 Group DETR이라 불리는, O2M을 위해 group-wise 방식을 사용하는 DETR 학습 방법을 제안합니다. K개 그룹의 object queries들을 사용하여 그룹별 O2O을 수행하며, 결과적으로 하나의 GT 객체가 여러 예측에 할당되게 합니다(정확히는 하나의 GT 객체에 K개의 예측(object queries)들이 할당된다). GT 객체에 할당된 예측은 높은 점수를 얻고, 동일한 queries 그룹 내의 다른 중복 예측(같은 GT에 할당되려 했지만, 점수가 낮아 결과적으로는 해당 GT에 할당되지 못한 object queries)들은 낮은 점수를 얻도록 학습됩니다. 다시 말해, object queries들은 그룹 내에서 경쟁을 하며, 그룹별 분리된 self-attention을사용합니다. 이는 다른 그룹의 예측들로부터 오는 영향을 제거하고 DETR 학습을 용이하게 합니다. 추론할 때는 정상적으로 학습된 DETR과 동일하며 단일 그룹의 object queries만 사용합니다.

결과적인 아키텍처는 위 그림 2.(a)에 보이는 바와 같이 병렬 decoder group을 가진 DETR과 동일합니다. 학습 중, 병렬 decoder들은 decoder 파라미터를 공유하고 서로 다른 object queries들을 사용합니다. 반면, 더 많은 그룹의 object queries를 사용하는 것은 데이터 증강과 유사하며, queries 증강으로서 동작합니다. 이는 더 많은 supervision을 도입하며 decoder 학습을 개선합니다.
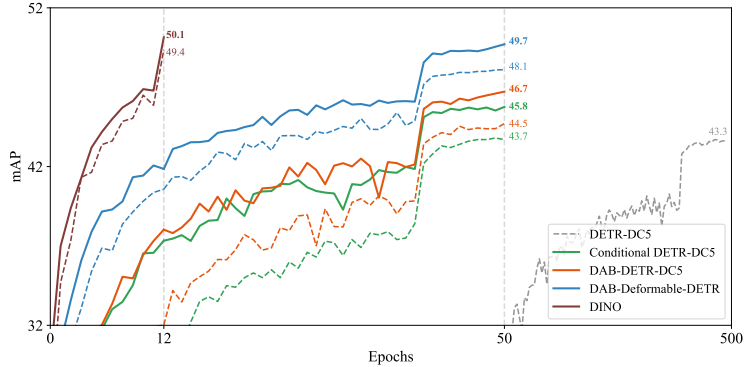
Group DETR은 아래의 그림 1.과 같이 빠른 학습 수렴을 달성하는데 효과적입니다:
Background.
DETR은 encoder, decoder, class/box predictor로 구성됩니다. encoder는 이미지 I를 입력으로 받아 image feature X를 출력합니다:

decoder는 image feature X와 행렬 Q로 표기되는 object queries들을 입력으로 받고, embedding \tildeQ를 출력하며, 그 뒤에는 Y로 표기되는 출력들을 갖는 predictor에 입력됩니다:

decoder는 여러 layer들의 sequence입니다. 이때 각 layer들은 다음을 포함합니다:
- object queries에 대한 self-attention, 이는 중복 탐지에 대한 정보를 수집하기 위해 queries들 간의 상호작용을 수행합니다.
- queries와 image feature사이의 cross-attention, 이는 object queries에 유용한 정보를 image feature로부터 수집합니다.
- object detection에 이득을 주기 위해 queries들을 개별적으로 처리하는 FFN.
DETR 학습 중의 예측들은 집합(set)의 형태이며, GT 객체들과 정해진 대응 관계가 없습니다. DETR은 예측들과 GT 객체들 사이의 bipartite matching을 구축함으로써 O2O, 즉 하나의 GT 객체가 하나의 예측에 할당되고 그 반대도 성립하는 방식을 사용합니다:
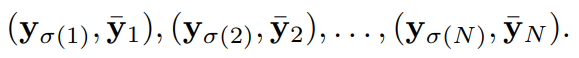
이때 σ()는 N개의 index의 최적 순열이며, \barY는 GT입니다. 그러면 loss는 다음과 같이 구할 수 있습니다:
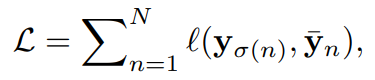
여기서 l()은 GT 객체(\barY)와 예측(y) 사이의 classification loss와 box regression loss의 조합입니다. O2O을 통한 최적화는 하나의 GT 객체에 대해 하나의 예측을 하도록 장려하며, 중복된 예측들을 GT와 아예 멀어지도록 낮은 점수를 주는 것을 목표로 합니다. 그러한 점수 매기기는 하나의 예측과 다른 예측들과의 비교를 필요로 하며, 다른 예측들에 대한 정보는 queries들에 대한 decoder self-attention으로부터 제공됩니다. O2O과 object queries에 대한 self-attention이라는 두 가지 설계는 후처리 NMS 필요 없는 end-to-end detection에 있어서 필수적입니다.
한편, O2M은 Faster R-CNN, FCOS 등 non-end-to-end detection에서 더 많은 supervision을 도입하기 위해 성공적으로 사용되었습니다. 하나의 GT 객체는 여러 앵커나 여러 픽셀에 해당되며, 추론 중에는 이러한 중복 탐지 제거를 위해 후처리 NMS가 필수적입니다.
Group DETR.
Naive O2M assignment.
위 그림 2.(c)에 묘사된 O2M을 위한 naive한 방식부터 시작합니다. 우선 O2O을 하나의 GT 객체를 여러 예측에 할당하는 O2M으로 대체합니다. 하지만 이것은 작동하지 않으며 성능이 매우 낮습니다. 모델이 하나의 GT 객체에 대해 여러 예측을 출력하도록 학습하지만, 하나의 GT 객체에 대해 단 하나의 예측만 높은 점수를 받고, 나머지 중복된 예측들은 낮은 점수를 매기는 메커니즘이 결여되어 있기 때문입니다.
Note: O2M을 DETR에 그냥 적용한다면, DETR은 중복된 bbox를 매우 많이 만들어내지만, NMS라는 후처리를 하지 않기 때문에, 추론의 결과로 생성되는 bboxes들은 거의 다 중복되어있을 것입니다. 따라서 NMS라는 후처리를 하지 않는데, 중복 bbox가 너무 많기 때문에 성능이 낮아지는 것입니다.
따라서 다중 group object queries 메커니즘을 사용합니다. 이는 초기 N개의 queries를 primary group으로 만들고, K-1개의 group에 각가 N개의 queries 사용하여, 총 K개의 groups를 만듭니다. 이에 따라 K개 group의 예측들인 Y_K를 얻습니다. 각 group들에 대해 O2O을 수행하고, 각 예측 그룹과 정답 객체들 사이의 bipartite matching을 수행합니다. 이는 모든 group내에서가 아니라 하나의 group 내에서, 하나의 GT 객체에 대해 오직 하나의 예측만이 더 높은 점수를 받고 중복 예측들은 더 낮은 점수를 받도록 결과를 만듭니다.
한 group내에서 O2O 할당은 GR 객체에 할당된 예측이 동일한 그룹 내의 다른 예측들보다 우월하다는 것을 의미합니다. 이것은 모든 groups로부터가 아니라 오직 동일한 group 내의 예측들로부터만 정보를 수집할 필요가 있습니다(O2O 할당은 group-wise로 수행하면서 attention은 모든 groups들을 통합해서 수행하면 안된다). 따라서 각 group에 대해 개별적으로 queries들에 대한 self-attention을 수행합니다:

결과적으로 encoder는 그대로 유지되며, decoder는 그림 2.(a)에 보이듯 K개의 분리된 병렬 decoder를 사용합니다:

여기서 K개 group에 대한 decoder와 predictor의 파라미터는 공유됩니다. decoder 분리와 병렬화는 다른 두 연산인 cross-attention과 FFN에 대해 queries들 간의 상호작용이 없기 때문에 실행 가능합니다.
Note: 즉, queries들 간의 self-attention만이 서로 다른 group들의 정보를 사용할 뿐, FFN이나 encoder image feature map을 사용하는 cross-attention은 서로 다른 groups들의 정보를 사용하지 않기 때문에 그냥 사용해도 된다는 뜻입니다. 아래의 그림 6. 을 통해 구조를 파악할 수 있습니다:

이런 접근법을 Group Decoder라고 부르며, 모델 추론에서는 오직 한 group의 queries들 만을 사용합니다. pseudo-code는 다음과 같습니다:

loss는 K개 loss들의 합이며, 각각은 하나의 decoder에 대한 것입니다. loss는 다음과 같이 계산됩니다:

Analysis.
Group DETR을 이용한 학습은 encode, decoder 그리고 predictor의 파라미터를 공유하고 오직 object queries의 초기화만 다른 K개의 DETR모델을 동시에 학습시키는 것으로 간주될 수 있습니다. 이것은 공유된 파라미터들이 더 많은 역전파된 gradients들을 받는 것으로 이어지며, 모델이 더 빠르게 수렴할 수 있습니다.

부수적인 이점으로서, 위 그림 5. 에 보이는 바와 같이 Group DETR이 할당을 더 안정적으로 만드는 것이 관찰됩니다.
multi-group object queries 메커니즘은 추가적인 K-1개의 group queries들을 사용하는데, 이는 queries들의 primary group에 대한 augmentation으로 간주될 수 있습니다.

이는 위 그림 3.에 경험적으로 묘사되어 있습니다. 동일한 객체를 예측하는 reference points들은 공간적으로 가까우며, 따라서 대응하는 object queries들은 유사합니다. 이것은 multi-group object queries 메커니즘이 데이터 증강과 유사하며, 매 iteration마다 더 많은 자동 학습된 증강 queries가 포함되고, 이는 decoder 학습을 위해 더 많은 supervision을 도입합니다.

위 그림 4.는 서로 다른 group의 증강된 queries들이 유사한 결과로 이어진다는 것을 경험적으로 시사합니다. 더 많은 supervision은 각 GT에 할당된 더 많은 queries로부터 더 많은 box regression/classification supervision을 도입합니다. 더 많은 supervision을 갖는 gradient는 또한 decoder에서 encoder로 역전파됩니다. 이는 encoder 또한 이득을 얻는다고 추정할 수 있으며, 이는 아래의 표 1. 을 통해 경험적으로 검증됩니다:

Group DETR은 학습 중에 더 많은 decoder를 사용합니다. 이는 추가적인 학습 연산 비용 뿐만 아니라 학습 메모리 비용을 가져올 것으로 예상할 수 있습니다. 하지만 병렬 decoder들은 일반 self-attention을 병렬 self-attention으로 대체함으로써 단일 decoder로 구현될 수 있으며, 효율적인 attention 구현체인 FlashAttention을 사용할 수 있습니다. 결과적으로, Group DETR은 학습 GPU 메모리와 학습 시간에서 오직 적은 증가만을 가져옵니다.

위 그림 7. 은 Group DETR은 연산 및 메모리 복잡도를 그렇게 많이 증가시키진 않는다는 것을 보여줍니다. 또한 Group DETR이 단순히 더 많은 학습 시간으로부터 이득을 얻는 것인지 확인하기 위해 일반 DETR 학습의 학습 시간을 늘려서 얻은 결과를 비교합니다:

위 표 2. 는 더 많은 학습 시간을 가진 일반 학습이 적은 이득을 가져오며 성능이 여전히 Group DETR보다 낮다는 것을 보여줍니다. 이를 통해 본 논문의 접근법의 성능 이득이 단순히 학습 시간 증가에서 오는 것이 아님을 암시합니다.
DN-DETR은 DETR 학습 중 O2O을 안정화하는 것을 목표로 합니다. DN-DETR은 GT 객체에 노이즈를 추가함으로써 추가적인 queries를 형성합니다. DN-DETR에서는 추가 그룹(DN group)의 queries의 수가 GT 객체의 수와 동일합니다. 각 query들은 하나의 GT 객체에 대응하며, no-object에 대응하는 queries들은 없습니다. 대조적으로, 본 논문의 접근법은 GT 객체와 no-object 모두에 대응하는 N개(예: 300)의 object queries들을 자동으로 학습합니다.
또한 DN-DETR은 주로 중복 예측보다는 다른 객체에 대한 예측(DN group들의 예측)으로부터 정보를 수집하기 위해 noised queries들에 대한 self-attention을 수행합니다. 대신 Group DETR에서의 self-attention은 중복 예측과 다른 객체에 대한 예측 모두를 수집합니다. 따라서 DN-DETR은 GT 객체에 대응하는 더 많은 양성 queries 도입을 통해 box와 classification 예측에 주된 도움을 주며, 중복 예측 제거에는 직접적인 도움을 주지 않습니다. 하지만 본 논문의 접근 방식은 양성 queries와 음성(no-object) queries를 모두 사용하며, 중복 예측 제거에 도움을 줍니다.
Note: DINO에서는 constrastive DN(CDN)을 통해 증강된 queries들을 통해 GT 객체에 대한 denoising 뿐만 아니라, no-object에 대한 denoising을 예측합니다:
[CoIn] 논문 리뷰 | DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection (Zhang et al., 2022)
https://arxiv.org/abs/2203.03605 DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object DetectionWe present DINO (\textbf{D}ETR with \textbf{I}mproved de\textbf{N}oising anch\textbf{O}r boxes), a state-of-the-art end-to-end object detector.
hw-hk.tistory.com
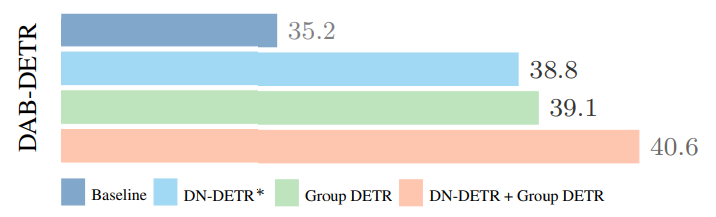
아래의 그림 8.은 Group DETR의 성능이 DN-DETR 보다 낫다는 것을 보여줍니다:
Experiments.
(... 원본 논문 참조 ...)