
https://arxiv.org/abs/2406.03459
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent adv
arxiv.org
Abstract.
본 논문에서는 실시간 object detection 분야에서 YOLOs들을 능가하는 light weight DETR인 LW-DETR을 제안합니다. 이는 ViT encoder, projector 그리고 shallow DETR decoder가 단순하게 쌓인 구조로서, ViT encoder의 복잡도를 줄이기 위해 loss와 pretraining을 개선했으며, window attention과 global attention을 교차로 배치하는 것과 같은 최긴 기술들을 활용합니다. 또한 ViT encoder 내의 intermediate 및 final feature maps과 같은 multi-level feature map들을 aggregation하여 더 풍부한 feature map을 형성함으로써 ViT encoder를 개선하고, 이렇게 교차되어 있는 attention의 연산 효율성을 위해 window-major(윈도우 중심)의 feature map 구성 방식을 사용합니다.
Introduction.
real-time object detection은 visual recognition에서 중요한 문제이며 광범위한 응용 분야를 갖습니다. 현재 지배적인 솔루션들은 YOLO 시리즈와 같은 CNN에 기반을 두고 있습니다. 최근에는 DETR과 같은 trasnformer-based 방법론들이 많이 발전했지만, real-time을 위한 DETR은 완전히 탐구되지 않았습니다.
본 논문에서는 real-time object detection을 위한 light-weight DETR을 제안합니다. 이는 일반적인(plain) ViT encoder와 DETR decoder가 CNN projector에 의해 연결된 구조입니다. encoder 내의 intermediate 및 final feature maps들인 multi-level feature map들을 aggregate하여, 더 강력한 encoded feature map을 형성합니다. 또한 decoder에는 deformable cross-attention와 IoU-aware classification loss 그리고 encoder-decoder pretraining 전략을 사용합니다.
한편, 일반 ViT encoder의 복잡도를 줄이기 위해 일부 global attention을 window attention으로 대체하여 window와 global attention을 교차로 배치하는 방식을 채택합니다. 또한 window attention을 할 때는 이미지의 pixel 값들을 window의 형태로 변환해야 하는데(permutation), 이 연산이 비쌉니다. 따라서 이런 값비싼 메모리 permutation 연산을 효과적으로 줄이기 위해 window-major feature map 구성 방식(애초에 이미지를 window의 형태로 사용하는 것)을 통해, 교차로 배치된 attention들의 효율적인 구현을 사용합니다.

위 그림 1.을 통해 본 논문이 제안한 모델이 COCO datasets에서 다른 real-time detector들을 능가함을 보여줍니다.
Related Work.
YOLO-NAS, YOLOv8, RTMDet과 같은 기존의 real-time object detector들은 데이터 증강, 학습 기법, 손실 함수 등을 통해 YOLO의 첫 번째 버전과 비교하여 크게 개선되어 왔습니다. 이러한 detector들은 convolution에기반하고 있으며, 본 논문에서는 real-time detection을 위한 transformer-based solution을 탐구합니다.
ViT는 image classification에서 좋은 성능을 보여줍니다. object detection에서 ViT를 적용하는 것은 메모리 및 연산 비용을 줄이기 위해 보통 window attention이나 hierachical architecture를 사용합니다. UViT는 점진적 window attention을 사용하며, ViTDet은 사전 학습된 일반 ViT를 교차 배치된 window attention과 global attention으로 구현합니다. 본 논문의 접근 방식은 ViTDet을 따라 교차 배치된 window 및 global attention을 사용하고, 추가적으로 메모리 permutation 비용을 줄이기 위해 window-majoor order의 feature map 구성을 사용합니다.
DETR은 anchor 생성 및 NMS와 같은 구성 요소들의 필요성을 제거한 end-to-end detection 방법입니다. architecture 설계, object queries 설계, 학습 기법, 손실 함수 개선과 같은 DETR의 개선을 위한 많은 후속 연구들이 있으며, 연산 최적화, pruning, distillation과 같이 복잡도 감소를 위해 다양한 연구들이 수행되었습니다. 본 논문의 관심사는 이러한 방법들에 의해 탐구되지 않은 real-time object detection을 위한 단순한 DETR baseline을 구축하는 것입니다.
RT-DETR 또한 CNN backbone이 encoder를 형성하는 것에 초점을 맞추어 real-time object detector를 구성하기 위해 DETR framework를 사용합니다. 하지만 그 연구에는 비교적 큰 모델들에 대한 연구만 있으며, 초소형(tiny) 모델들에 대한 연구는 부족합니다. LW-DETR은 real-time detecctioon을 위한 일반 ViT backbone들과 DETR framework의 타당성을 탐구합니다.
[CoIn] 논문 리뷰 | DETRs Beat YOLOs on Real-time Object Detection (Zhao et al., 2023)
https://arxiv.org/abs/2304.08069 DETRs Beat YOLOs on Real-time Object DetectionThe YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the spe
hw-hk.tistory.com
LW-DETR.
Architecture.
LW-DETR은 ViT encoder, projector 그리고 DETR decoder로 구성됩니다.
LW-DETR은 detection encoder로서 ViT를 사용합니다. 일반 ViT는 patchification layer와 transformer encoder layer들로 구성됩니다. 초기 ViT의 transformer encoder layer는 모든 token에 대해 global self-attention layer와 FFN layer를 포함합니다. global self-attention은 계산 비용이 많이 들며, 그 시간 복잡도는 token(patch) 수에 대해 quadratic입니다. 이런 계산 복잡도를 줄이기 위해 일부 transformer encoder layer를 window self-attention으로 구현합니다. 또한 encoder 내의 intermediate 및 final feature map들인 multi-level feature map들을 aggregation하여, 더 강력한 encoded feature map을 형성합니다. 이는 아래의 그림 2.에 묘사되어 있습니다:

decoder는 transformer decoder layer들의 stack입니다. 각 layer는 self-attention, cross attention 그리고 FFN으로 구성됩니다. 본 논문에서는 계산 효율성을 위해 deformable cross-attention을 사용합니다. DETR과 그 변형들은 보통 6개의 decocer layer를 사용합니다. 하지만 본 논문에서는 효율성을 위해 3개의 decoder layer를 사용하며, 이는 시간을 1.4ms에서 0.7ms로 단축시킵니다.
또한 object queries를 content queries와 spatial queries의 합으로 형성하기 위해 mixed-query selection shceme을 사용합니다. contenmt queries는 DETR과 유사하게 학습 가능한 embedding입니다. spatial queries는 다음과 같이 계산합니다: projector의 마지막 layer에서 top-k개의 feature를 선택하고, bbox를 예측한 다음, 해당 bbox들을 spatial queries로서 embedding으로 변환하는 것입니다.
[CoIn] 논문 리뷰 | DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection (Zhang et al., 2022)
https://arxiv.org/abs/2203.03605 DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object DetectionWe present DINO (\textbf{D}ETR with \textbf{I}mproved de\textbf{N}oising anch\textbf{O}r boxes), a state-of-the-art end-to-end object detector.
hw-hk.tistory.com
Note: Mixed-Query Selection이 왜 좋을까요? 이전의 vanilla DETR은 학습 시작 전에 아무런 정보가 없는 랜덤 벡터 100개를 만들고, 학습을 통해 이 벡터들의 값을 업데이트합니다. 이 100개의 queries(content + position)은 모든 이미지에 대해 고정(static)되어 있습니다(이미지가 들어오면 동적으로 바뀌는 값이 아니니까). 즉, 이미지마다 객체의 위치가 다른데, queries는 항상 같은 곳부터 찾기 시작하는 것입니다. 이로 인해 학습 수렴 속도가 매우 느립니다.
Note: 반면, Deformable DETR과 같은 방법들은 encoder가 이미지를 훑어본 후, "여기에 물체가 있을 확률이 높아요" 라고 예측한 점수 중 top-k를 뽑습니다. position의 경우 top-k로 뽑힌 위치를 anchor로 사용하며, content의 경우 encoder에서 나온 그 위치의 feature 값 자체를 decoder의 초기 입력(content query)으로 사용해버립니다. 하지만, encoder feature는 "여기에 물체가 있다/없다"를 판단하기 위해 학습된 것이지, decoder처럼 "이 물체의 경계가 어디고 클래스가 뭐다"를 추론하기 위한 정보와는 성격이 다를 수 있습니다. 따라서 LW-DETR과 DINO는 mixed query selection을 사용합니다. 이는 content query는 vanilla DETR과 같이 static하게 하지만, spatial query는 deformable DETR과 같이 dynamic하게 선택하는 것입니다.
encoder와 encoder를 연셜하기 위해 projector를 사용합니다. projector는 encoder로부터 encoded feature maps들을 입력으로 받습니다. 이는 YOLOv8에서 구현된 C2f block(cross-stage partial DenseNet의 확장)입니다.
Note: projector는 encoder와 decoder 사이를 연결하는 다리의 역할을 합니다. ViT encoder가 뱉어내는 feature map의 channel 수와 DETR decoder가 입력을 받기 원하는 channel 수가 다를 수 있습니다. projector는 이 차원을 맞춰주어 decoder가 데이터를 잘 받을 수 있도록 변환해줍니다. 또한 encoder에서 나온 feature들을 한 번 더 섞고 가공하여 decoder가 해석하기 더 좋은 형태로 만들어주며, 이때 사용하는 것이 C2f block과 같은 것입니다.
Note: C2f block은 YOLOv8에서 처음 도입된 구조로, 기존 YOLOv5의 C3 모듈과 YOLOv7의 ELAN 구조의 장점을 합친 block입니다. 이는 입력받은 feature map을 channel 기준으로 두 갈래로 쪼갭니다(split). 그 후 한쪽 갈래는 여러 개의 bottleneck layer를 통과시키며 feature를 깊게 추출하여 가공되지 않은 나머지 갈래와 다시 합칩니다(concat). 이는 데이터의 일부가 연산을 건너뛰고 바로 출력으로 연결되므로(skip connection), 역전파시 gradient가 소실되지 않고 잘 흐르게 해줍니다.
LW-DETR의 large 및 xlarge 버전을 만들 때, projector를 두 가지 scale(1/8과 1/32)의 feature map을 출력하도록 수정하고 이에 따라 multi-scale decoder를 사용합니다. projector는 두 개의 병렬 C2f block을 사용하며, 하나는 deconvolution을 통해 입력을 upsampling하여 얻은 1/8 feature map을 담당하며, 다른 하나는 stride convolution을 통해 입력을 downsampling하여 얻은 1/32 feature map을 담당합니다. 아래의 그림 3.은 single-scale projector와 multi-scale projector의 pipeline을 보여줍니다:

본 논문에서는 IoU-aware classification loss인 IA-BCE loss를 사용합니다:

여기서 N_pos와 N_neg는 양성 및 음성 samples의 수입니다. s는 예측된 분류 점수이며, t는 IoU점수 u를 사용한 target score입니다:

이때 alpha는 경험적으로 0.25로 설정됩니다. 전체 loss는 DETR framework들에서와 동일하게 classification loss와 bbox loss의 결합이며, 다음과 같습니다:

여기서 lambda_iou와 lambda_l1은 2와 5로 설정됩니다.
Instantiation.
본 논문에서는 5개의 LW-DETR을 만듭니다: tiny, small, medium, large, xlarge:

(... 이들에 대한 자세한 config ...)
Effective Training.
DETR 학습을 가속화하기 위하 더 많은 supervision을 도입하는 다양한 기법들이 개발되었습니다. 예를 들어, 본 논문에서는 쉽게 구현되며 추론 과정을 변경하지 않는 Group DETR을 사용합니다:
[CoIn] 논문 리뷰 | Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment (Chen et al., 2023)
https://arxiv.org/abs/2207.13085 Group DETR: Fast DETR Training with Group-Wise One-to-Many AssignmentDetection transformer (DETR) relies on one-to-one assignment, assigning one ground-truth object to one prediction, for end-to-end detection without NMS po
hw-hk.tistory.com
이에 따라, 학습을 위해 13개의 weight-sharing decoder를 사용하며, 각 decoder에 대해 projector의 출력 feature로부터 각 group을 위한 object queries들을 생성합니다.
또한 Object365를 통해 사전학습을 수행하며, 이는 두 단계로 구성됩니다: 첫째, 사전 학습된 모델들에 기반하여 MIM 방식인 CAEv2를 사용하여 dataset Object365에서 ViT를 사전 학습합니다. 둘째, Object365에서 encoder를 재학습하고 decoder와 projector를 supervision 방법으로 학습합니다.
Note: MIM(Masked Image Modeling)은 NLP의 BERT 모델에서 영감을 받아 이미지 분야로 가져온 학습 방법론입니다. 이는 masked 부분을 보고, 주변 문맥을 통해 그것이 무엇인지 맞추는 것입니다. 입력 이미지를 작은 patch로 나눈 후, 조각 중 상당수를 무작위로 가립니다. 모델에게는 가리지 않은 조각들만 보여주고, 가려진 부분에 원래 무슨 그림이 있었는지 맞추도록 학습합니다. 이는 정답 라벨 없이도 이미지 내의 사물이 어떻게 생겼는지를 강력하게 학습할 수 있는 방법입니다.
Note: CAE(context autoencoder)는 대표적인 MIM모델인 MAE(masked autoencoder)의 한계를 극복한 모델입니다. MAE는 encoder는 보이는 패치만 처리하고, decoder가 복원을 담당하는데, 이때 encoder는 복원에 필요한 정보를 단순히 전달만 하고, 스스로 의미를 이해하는 능력이 부족할 수 있습니다. 따라서 encoder는 좋은 feature를 뽑는데 집중할 수 있도록 masked되어있는 feature를 예측하는 task를 부여받습니다. 이에 더해 CAEv2는 encoder가 예측한 feature와 실제 마스크 부분의 feature가 수학적으로 비슷해지도록 강제하는 부분을 추가한 것입니다.
Efficient Inference.
본 논문에서는 encoder(ViT)에 Window attention과 global attention을 교차 배치했습니다. 일부 global self-attention layer를 window self-attention layer로 교채하는 것인데, 이에 효율적인 교차 배치 attention을 위해 window-major feature map 구성 방식을 사용합니다. 이는 feature map들을 window 단위로 구성하는 것입니다. feature map들이 행 단위(row by row) 구성되는 ViTDet 구현은 window attention을 위해 feature map을 row-major 구성에서 window-major로 바꾸는 데 값비싼 permutation 연산들을 필요로 합니다.
예를 들어 다음과 같이 4 x 4 feature map이 주어졌을 때:
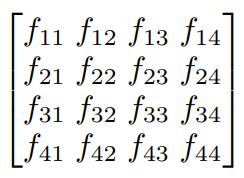
window size 2 x 2에 대한 window-major 구성은 아래와 같습니다:
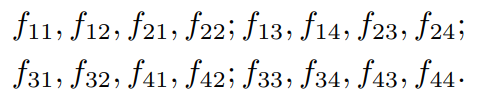
이 구성은 feature들을 재배열하지 않고도 window attention과 global attention에 모두 적용 가능합니다. 하지만 아래와 같은 row-major 구성은:

global attention에는 괜찮지만, window attention을 수행하기 위해서는 값비싼 permutation 연산으로 처리되어야 합니다.
Empirical Study.
ViTDet에 의해 채택된 교차 배치된 window 및 global attention은 계산 복잡도를 23.0 GFlops에서 16.6 GFlops로 줄여주며, 비싼 global attention을 저렴한 window attention으로 대체하는 것의 이점을 검증할 수 있습니다. 하지만 지연 시간(latency)는 줄어들지 않았고 심지어 0.2ms 증가했습니다. 이는 row-major feature map 구성에서 값비싼 permutation 연산들이 필요하기 때문입니다. window-major feature map 구성은 이러한 부작용을 완화하고 3.7ms에서 2.9ms로 0.8ms라는 더 큰 latency 감소를 이끕니다.
multi-level feature aggregation은 0.7mAP 이득을 가져옵니다. IoU-aware classification loss와 더 많은 supervision(Group DETR)은 mAP 점수를 34.7에서 35.3와 38.4로 향상시킵니다. bbox regression target을 위한 bbox reparameterization은 약간의 성능 향상을 만들며, 가장 큰 향상은 Object365에서의 사전 학습에서 옵니다. 이는 8.7mAP를 향상시키는데, 이는 transformer가 실제로 대용향 데이터로부터 이득을 얻음을 시사합니다. 아래는 이들을 정리한 표입니다:

Experiments.
(... 자세한 실험 내용은 원본 논문을 참조 ...)