
https://arxiv.org/abs/2407.11699
Relation DETR: Exploring Explicit Position Relation Prior for Object Detection
This paper presents a general scheme for enhancing the convergence and performance of DETR (DEtection TRansformer). We investigate the slow convergence problem in transformers from a new perspective, suggesting that it arises from the self-attention that i
arxiv.org
Abstract.
본 논문은 DETR의 수렴성과 성능을 향상시키기 위한 방법을 제안합니다. 본 논문은 transformer의 느린 수렴 문제를 새로운 관점에서 조사하며, 이것이 입력에 대한 구조적 편향(structural bias)을 도입하지 않은 self-attention에서 기인한다고 제안합니다. 이 문제를 해결하기 위해, Macroscopic Correlation, MC(정량적 거시적 상관관계) 지표를 사용하여 그 통계적 유의성을 검증한 후, object detection을 강화하기 위해 위치 관계 사전 정보(position relation prior)를 attention bias로 통합하는 것을 탐구합니다.
Relation-DETR이라 불리는 본 논문의 접근 방식은 점진적인(progressive) attention refinement를 위한 position relation embedding을 구축하기 위해 encoder를 도입하며, 이는 중복되지 않은 예측과 positive supervision 사이의 충돌을 해결하기 위해 기존의 DETR streaming pipeline을 constrastive relation pipeline(대조 관계 파이프라인)으로 더 확장합니다.
Introduction.
obejct detection은 관심 있는 각 object에 대해 bbox regression과 object classification 문제를 해결하는 것을 목표로 합니다. 최근, DETR은 CNN detector들의 수작업 설계에 대한 의존성을 극복하고, end-to-end 방식의 아키텍처를 달성했습니다. 하지만, COCO와 같은 대규모 데이터셋에서 좋은 성능을 보여주었음에도 불구하고, 느린 수렴 문제가 존재합니다.
이 문제의 근본 원인은 중복되지 않은 예측(non-duplicate predictions)을 위한 학습(O2O)과 많은 positive supervision(O2M) 사이의 충돌에 있습니다. 학습 과정 동안, DETR은 고유한 결과를 생성하기 위해 hungarian algorithm을 사용하여 각 GT에 단 하나의 positive prediction만을 할당합니다. 그러나, 이는 negative predictions이 loss function의 대다수를 지배하게 만들어, 불충분한 positive supervision을 초래합니다. 따라서, 수렴을 위해 더 많은 샘플과 iterations이 요구됩니다.
이전의 시도들은 추가적인 감독을 위해 train-only architecture(예: query denoising, group queries 등)를 도입하거나, loss function에 hard mining(예: IA-BCE loss)하여 이 문제를 해결했습니다. 다른 연구들은 queries들과 feature maps 사이의 더 나은 상호작용을 위한 특정 구조들(예: DAB-DETR)뿐만 아니라 고품질 queries에 집중하는 기법들을 제안했습니다. 이러한 발전에도 불구하고, 대부분의 DETR detector들은 transformer decoder에서 널리 사용되는 self-attention의 관점에서는 이 문제에 대한 탐구가 거의 이뤄지지 않았습니다.
self-attention의 효과는 sequence embedding 사이의 고차원적 관계 표현을 수립하는 데 있으며, 이는 또한 서로 다른 detection feature들 사이의 관계를 모델링하는 핵심 구성 요소로 작용합니다. 그러나, 이러한 관계는 입력에 대해 어떠한 구조적 편향도 가정하지 않은 implicit한 표현이며, 심지어 위치 정보조차 학습 데이터로부터 배워야 합니다. 결과적으로, transformer의 학습 과정은 데이터 집약적이며 수렴이 느립니다.
Note: 위치 정보를 학습 데이터로부터 배우는 것은 문제가 안됩니다. Deformable-DETR 등은 encoder로부터 위치 정보를 가져오기 때문에, 학습 데이터(입력 데이터)로부터 위치 정보를 학습하는 것입니다. 하지만 본 논문에서는 그걸로는 부족하다는 것입니다. transformer의 self-attention은 CNN과 달리 뭉쳐있는 픽셀들 간의 관계, 즉 spatial locality를 이용하는 것이 부족하며, 이를 채워주기 위해 structural bias, 즉 바로 옆 픽셀이 중요하다는 기초적인 사실을 명시적으로 알려주면 됩니다.
본 논문에서, 명시적 위치 관계 사전 정보(explicit position relation prior)를 통해 DETR detector들을 강화하는 것을 탐구합니다. 먼저 이미지 내의 위치 관계를 정량화하기 위한 지표를 수립하고, 그 통계적 유의성을 검증하기 위해 분포를 분석합니다. 이러한 맥락에서, 두 bbox 간의 모든 pairwise 상호작용을 모델링하기 위해 position relation encoder를 사용하며, cross-layer 정보 상호작용을 위해 progressive attention refinement를 사용합니다. 충분한 positive supervision을 제공하면서도 end-to-end 속성을 유지하기 위해, contrast relation strategy를 사용하는데, 이는 O2O matching과 O2M matching을 모두 활용하면서 중복 제거에 대한 위치 관계의 영향력을 강조합니다(즉, O2M matching을 통해 supervision의 수를 유지하며, O2M matching 사용하면 중복 제거를 NMS를 통해 해야하니, O2O matching을 활용하여 중복 제거에 대한 위치 관계의 영향력을 사용한다는 뜻).
Related Work.
transformer-based feature extractor들은 이미지 patches들에 기반하여 token sequence를 생성하고, 지역적 특징들을 aggregation하거나 pyramid 후처리를 통해 multi-scale feature들을 추출합니다. DETR은 추출된 feature들을 object queries로 encoding하고 이를 탐지된 bbox와 label로 decoding합니다. 그러나, self-learned attention mechanism은 대규모 데이터셋과 학습 반복에 대한 요구를 증가시킵니다. 이전까지 많은 연구들(예: DAB-DETR, Group-DETR, Deformable-DETR 등)이 있었지만, 이들조차 여전히 transformer decoder에서 vanilla multi-head attention을 활용합니다.
시각적 feature들을 pixel-level, patch-level 또는 image-level에서 처리하는 대신, relation network는 instance 수준에서 관계들을 포착합니다. relation network에 대한 기존 연구는 category-based 및 instance-based 접근법들을 포함합니다. category-based 접근법들은 Visual Genome과 같은 relation datasets들로부터 또는 class labels들로부터 적응적으로 학습하여 개념적 또는 통계적 관계(예: 동시 발생 확률)를 구축합니다. 그러나 이 둘 모두 instance와 category 사이의 할당으로 인해 복잡성을 증가시킵니다.
대조적으로, instance-based 접근법들은 object feature들을 node 집합으로, 그들의 관계를 edge 집합으로 하여 fine-grained graph 구조를 직접 구축합니다. 따라서, 학습 과정 동안 graph 상에서의 추론은 자연스럽게 explicit한 관계 가중치를 결정합니다. 이 가중치는 고차원 공간에서 각 쌍의 object instances들 사이의 parametric distance를 나타내며, 외형 유사도, proposals distance 또는 self-attention score 같은 것입니다. 구조적 편향 없이 오로지 학습 데이터로부터만 self-attention score를 학습하는 것은 데이터셋 규모와 반복에 대한 요구를 증가시키기 때문에, 그 요구를 줄이기 위해 명시적 위치 관계를 prior로서 탐구합니다.
object detection training 동안, GT에 할당된 positive predictions들은 negative predictions들보다 훨씬 적어서, 종종 불균형한 감독과 느린 수렴을 초래합니다. classification task에서 Focal Loss는 어려운 샘플에 집중하기 위해 가중치 파라미터를 도입했으며, 이는 GFL, VFL과 같은 많은 변형들로 확장되었습니다. 게다가, object detection task를 위해, regression 지표에 기반한 modulated terms을 가진 loss function들(예: TOOD, IA-DCE)를 사용하는 것이 제안되었습니다.
Statistical significance of object position relation.
object detection에서 object들간의 상관관계가 존재하는지 확인하기 위해, 단일 이미지 내 객체들 간의 위치 상관관계를 측정하고자 Pearson Correlation Coefficient, PCC에 기반한 정량적인 상관관계(Macroscopic Correlation, MC) 지표를 제안합니다. 이미지 내의 object들이 node 집합을 형성하고, 각 bbox 주석 쌍 사이의 PCC가 그에 해당하는 edge 가중치 역할을 한다고 가정하면, 연속적인 값을 가진 무방향 그래프를 구축할 수 있습니다.
이를 통해, 각 이미지에 대한 MC는 그래프 강도(graph intensity)를 사용하여 계산할 수 있으며, 다음과 같이 공식화됩니다:

N은 객체의 수, 즉 node의 수를 나타내며, b = [x, y, w, h]는 데이터셋 내 bbox의 위치 주석을 나타냅니다. MC = 1은 모든 객체가 선형적으로 상관관계가 있을 때만 성립하며, 어떠한 객체 쌍 사이에도 위치 상관관계가 없으면 MC = 0 입니다. 이를 산업용(ESD, CSD, MSSD), 가정용(AI2thor), 도심용(Cityscapes), 그리고 일반적인 환경(PascalVOC, COCO, Object365, SA-1B)을 포함한 다양한 시나리오에 걸쳐 데이터셋들에 대한 MC의 통계적 분포를 시각화합니다:
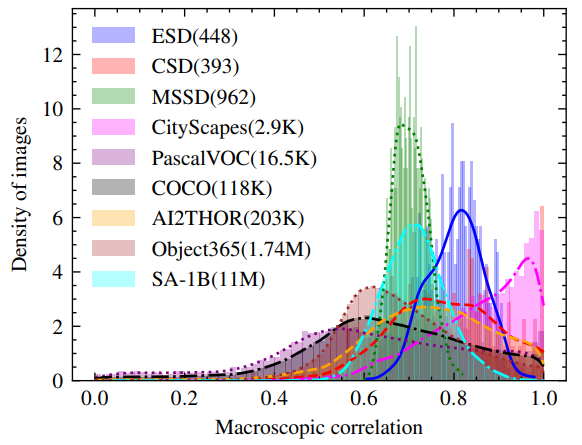
위 그림 1.에서 보이는 바와 같이, 이 모든 데이터셋들은 MC의 분포가 높은 수치 값 주변에 집중되어 있으며, 분포의 중심이 1에 더 가깝다는 것을 알 수 있습니다. 이것은 object 위치 관계의 존재와 통계적 유의성을 입증하며, 특히 task-specific datasets들은 고차원 특징 공간에서 더 많은 prior knowledge와 더 명확한 클러스터링 패턴을 보여줍니다.
Relation-DETR.
위에서 살펴봤듯, 위치 관계의 통계적 유의성을 고려하여, object detection을 향상시키기 위해 명시적 위치 관계 사전 정보(explicit position relation prior)를 이용하는 Relation-DETR을 제안합니다.
Position relation encoder.
backbone에 의해 추출된 image feature가 주어지면, transformer encoder는 object queries들을 bbox = [x, y, w, h]와 class label c를 예측값으로 decoding하기 위한 증강된 메모리 Z(feature map, d x H x W)를 생성합니다. 각 decoder layer는 iterative bbox refinement를 통해 마지막 decoder layer의 좌표에 대한 Δ를 예측함으로써 bbox 좌표를 반복적으로 정제합니다. 게다가, aux loss를 계산하기 위해 모든 decoder layer의 예측값들이 loss 계산이 동등하게 참여합니다.
앞서 언급한 프레임워크 하에서, position relation encoder는 고차원 relation embedding을 transformer 내 self-attention을 위한 explicit prior로서 표현합니다. 이 embedding은 각 decoder layer의 예측된 bbox를 기반으로 계산됩니다. relation이 평행 이동 및 스케일 변환에 불변(강건)하도록 보장하기 위해, 정규화된 상대적 기하학 특징(normalized relative geometric features)에 기반하여 encoding합니다:
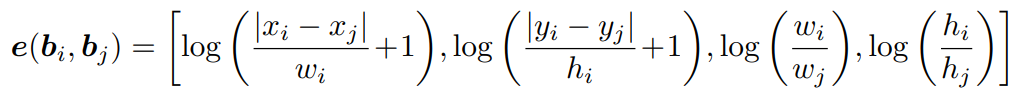
i = j일 때, e(b_i, b_j) = 0이기 때문에, 위 위치 관계는 unbiased입니다.
Note: 위에 relation geometric features가 왜 평행 이동 및 스케일 변환에 불변해야 하며, 저 식이 왜 불변함을 보장할까요? 예를 들어, 모델에게 bbox A는 (10, 10)에 있고, bbox B는 (20, 20)에 있다고 절대 좌표로 알려주는 것은 이미지가 커지거나 이동하면 좌표가 다 바뀌기 때문에 별로 도움이 되지 않습니다. 대신 "bbox B는 A의 너비만큼 오른쪽으로 떨어져있고, 크기는 bbox A의 절반이야" 라고 알려주면, 이미지를 확대하든 이동하든 관계는 변하지 않습니다. 이것이 불변성입니다. 따라서 위 수식의 4가지 요소는 다음과 같습니다:
- log(|x_i - x_j|/w_i + 1): 가로 거리, 두 bbox가 x축으로 얼마나 떨어져 있나? (기준은 내 너비 w_i 대비).
- log(|y_i - y_j|/h_i + 1): 세로 거리, 두 bbox가 y축으로 얼마나 떨어져 있나? (기준은 내 높이 h_i 대비).
- log(w_i/w_j): 너비 비율, 내 너비가 쟤보다 몇 배 큰가?
- log(h_i|/h_j): 높이 비율, 내 높이가 쟤보다 몇 배 큰가?
relation matrix(object들간의 position relation을 나타내는 행렬, E(i, j) = e(b_i, b_j), N x N x 4)는 sine-cosine encoding을 통해 고차원 embedding으로 변환됩니다:
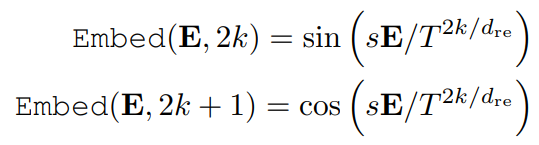
relation embedding의 형태는 N x N x 4d_re이며, T와 d_re, s는 encoding 파라미터입니다.
Note: 위에 normaliezed relative geometric features를 그냥 attention의 bias로 사용하기에는 4차원짜리 벡터이기 때문에, 불가능합니다. 따라서 이를 고차원의 벡터로 바꿔야하며, transformer의 positional encoding처럼, 하나의 거리 값을 여러 주파수를 가진 sine-cosine 파동에 태웁니다.
마지막으로 embedding은 linear transformation을 거쳐 M개의 scalar 가중치를 얻는데, 여기서 M은 attention head의 수를 나타냅니다:

여기서 ε은 self-attention에 통합될 때 exp 연산 후 기울기 소실(gradient vanishing)을 피하기 위해 relation에 대한 양수 값을 보장하며, 해당 값은 N x N x M입니다.
Progressive attention refinement with position relation.
Deformable-DETR에 의해 제안된 iterative bbox refinement는 고품질 bbox에 대한 유효성을 보여주었습니다:
[CoIn] 논문 리뷰 | DEFORMABLE DETR: DEFORMABLE TRANSFORMERSFOR END-TO-END OBJECT DETECTION (Zhu et al., 2021)
https://arxiv.org/abs/2010.04159 Deformable DETR: Deformable Transformers for End-to-End Object DetectionDETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. Howev
hw-hk.tistory.com
이에 따라 본 논문에서도 위치 관계를 DETR의 streaming pipeline에 적용하기 위해 iterative attention refinement 방법을 제안합니다. i-th layer의 relation은 (i-1)-th layer와 i-th layer의 bbox 모두에 의해 결정되며, 이는 (i+1)-th layer의 bbox를 생성하기 위해 self-attention에 추가로 통합됩니다:

여기서 Q^l은 DETR transformer의 l-th deocder layer에 있는 query를 나타내고, Z는 메모리, 즉 transformer encoder로부터 생성된 image feature입니다. 본 논문의 방법과 기존 DETR decoder 사이의 유일한 차이점은 빨간색으로 표시되어 있으며, 아래 그림 2에 묘사된 바와 같이, 위치 관계 계산을 위한 lateral branch를 사용합니다:

따라서 position relation과 iterative attention refinement는 직관적이며, 일관된 성능 향상을 달성하기 위해 기존 DETR detector들의 self-attention에 plug-in-and-play 통합을 허용합니다.
Contrast relation pipeline.
기본의 중복 제거 방법들(예: NMS, soft-NMS 등)의 메커니즘을 재고해보면, 이러한 과정들은 IoU에 크게 의존하는데, 이는 어느 정도 bbox 간의 위치 관계를 의미합니다(bbox사이의 위치 관계가 겹치면 중복을 제거하는 거니까). 따라서 self-attention 내 queires들 간의 position relation을 통합하는 것이 유사하게 object detection에서 중복되지 않은 예측에 기여한다고 가설을 세울 수 있습니다.
중복되지 않은 예측을 위한 O2O matching과 충분한 positive supervision을 위한 O2M matching의 충돌은 DETR의 streaming pipeline에서 발생할 수 있습니다. 이 한계를 극복하기 위해, 제안된 position relation에 기반하여 이를 contrast pipeline으로 확장합니다. 두 개의 병렬 queries sets, 즉 matching queries Q_m과 hybrid queries Q_h를 구축합니다. 둘 다 transformer decoder에 입력되지만 서로 다른 처리를 겪습니다. matching queries는 중복되지 않은 예측을 생성하기 위해 position relation을 통합한 self-attention으로 처리됩니다:
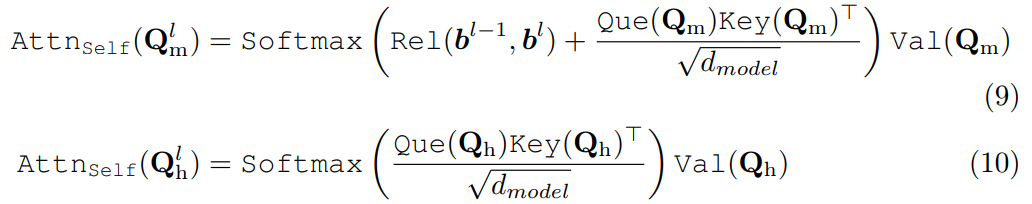
반면 hybrid queries는 동일한 decoder에 의해 decoding되지만 더 많은 잠재적 후보를 탐색하기 위해 position relation 계산을 건너뜁니다. 그들의 대응하는 예측은 각각 p_m^l = (b_m^l, c_m^l)과 p_h^l = (b_h^l, c_h^l)로 표기됩니다. 이에 대한 세부 사항은 아래의 그림 3.에 설명되어 있습니다:

g가 GT 주석을 나타낸다고 가정할 때, p_m에 대해서는 중복되지 않는 속성을 강조하기 위해 O2O matching 체계를 사용하며, loss 계산은 원본 DETR과 유사합니다:

반면, p_h에 대해서는, 더 많은 잠재적 positive prediction들을 형성하기 위해 O2M matching 체계가 사용됩니다. 이는 H-DETR을 따르며 loss 계산을 위해 정답을 K번 반복하여 \tilde{g} = {g^1, g^2, ..., g^K}로 표기합니다:
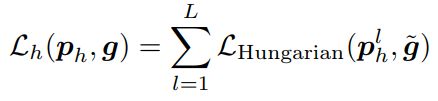
hybrid queries는 오직 학습 중에만 관여하므로, 추론 시에는 어떠한 추가적인 계산 부담도 발생하지 않습니다.
Note: 왜 p_h에는 position relation을 사용하지 않을까요? 이는 p_h의 목적이 많은 수의 positive supervision을 만드는데 있어서 그렇습니다. 앞선 가정에 따르면 position relation은 NMS와 같은 중복 제거의 원리와 유사합니다. 따라서 position relation을 적용하면 중복된 예측이 줄어드는 것입니다. 중복된 예측이 줄어들면, O2M matching에서 하나의 GT에 할당되는 positive supervision의 개수가 줄어들 수 있습니다. hybrid queries들의 목적은 많은 positive supervision을 만드는 것이기 때문에, position relation을 사용하지 않는 것입니다.
Note: 한편 H-DETR의 loss는 어떤 것일까요? 이는 K번 정답을 복제하는 것입니다. 이미지에 "고양이"라는 정답(g)가 있다고 가정했을 때, 기존 DETR은 정답 리스트 = [고양이] 1개입니다. 즉, queries가 300개가 있다면 positive prediction은 오직 1개이고, 나머지 299개는 negative samples이 되는 것입니다. 반면에, H-DETR은 정답을 K(예: 6)번 복사합니다. 따라서 정답 리스트 = [고양이, 고양이, ..., 고양이] 6개입니다. 즉, positive samples의 개수가 K개가 되는 것입니다. 다시 돌아와서, 최대 K개의 positive sample을 만들 수 있는데, p_h에서 position relation을 사용하여 중복된 예측을 줄인다면, 고양이(GT) 근처에 prediction들이 중복되어 예측되지 않는다면, 최대 K개의 positive sample을 만들 수 있지만, 그보다 더 적게 positive sample이 만들어 질 것입니다.
Experimental Results and Discussion.
(... 자세한 실험 내용은 논문 원본 참조 ...)