
https://arxiv.org/abs/2409.08475
RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision
RT-DETR is the first real-time end-to-end transformer-based object detector. Its efficiency comes from the framework design and the Hungarian matching. However, compared to dense supervision detectors like the YOLO series, the Hungarian matching provides m
arxiv.org
Abstract.
RT-DETR을 최초의 end-to-end transformer based object detector입니다. 그 효율성은 framework 설계와 hungarian matching에서 비롯됩니다. 하지만 YOLO 시리즈와 같은 dense supervision detector들과 비교할 때, hungarian matching은 sparse supervision을 제공하여, 불충분한 모델 학습을 초래하고 최적의 결과를 달성하기 어렵게 만듭니다. 이러한 문제들을 해결하기 위해, RT-DETR에 기반한 hierarchical dense positive supervision(계층적 밀집 양성 감독) 방법을 제안하며, 이를 RT-DETRv3라고 명명합니다.
먼저 원본 decoder와 협력하여 encoooder의 feature representation을 향상시킬 수 있는 dense supervision을 제공하는 CNN based aux branch를 사용합니다. 또한 불충분한 decoder 학습을 해결하기 위해, self-attention perturbation을 포함하는 새로운 학습 전략을 제안합니다. 이는 여러 query group들에 걸쳐 positive samples에 대한 라벨 할당을 다양화하여, positive supervisioon을 풍부하게 합니다. 추가로, 각 GT에 매칭되는 더 많은 고품질 queries들을 보장하기 위해 dense supervision을 위한 shared-weight decoder branch를 사용합니다. 위에 언급된 모듈들은 학습 중에만 사용되며, 추론에 영향을 주지 않아 빠른 추론 속도를 달성할 수 있습니다. RT-DETRv3는 RT-DETR 시리즈와 YOLO 시리즈를 포함한 기존 real-time detector들을 능가합니다.
[CoIn] 논문 리뷰 | DETRs Beat YOLOs on Real-time Object Detection (Zhao et al., 2023)
https://arxiv.org/abs/2304.08069 DETRs Beat YOLOs on Real-time Object DetectionThe YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the spe
hw-hk.tistory.com
Introduction.
object detection은 computer vision에서 근본적인 문제이며, 주로 이미지 내 객체의 위치와 카테고리 정보를 얻는 데 초점을 맞춥니다. real-time object detection을 30FPS보다 빠른 추론 속도와 같이 알고리즘 성능에 대해 더 높은 요구사항을 갖습니다. 이는 자율주행, 비디오 감시, 객체 추적과 같은 실제 응용 분야에서 중요한 가치를 지닙니다. 최근 몇 년간, real-time object detection에서 가장 인기 있는 것은 YOLO 시리즈와 같은 CNN 기반의 single-stage real-time object detector들입니다. 이들은 O2M 라벨 할당 전략을 사용하며, 중복된 예측 결과를 걸러내기 위해 NMS를 사용합니다. 비록 이 전략이 추가적인 지연 시간을 도입하지만, 정확도와 속도 사이의 trade-off를 달성했습니다.
DETR은 최초의 transformer based end-to-end object detector입니다. 이는 집합 예측을 사용하며, hungarian matching 전략을 통해 최적화되어, NMS 후처리의 필요성을 제거하고 그에 따라 object detection 과정을 단순화합니다. 후속 DETR(예: DAB-DETR, DINO, DN-DETR 등)은 iterative refinement 과정과 denoising 학습을 추가로 도입했으며, 이는 모델의 수렴 속도를 효과적으로 가속화하고 성능을 향상시켰습니다. 그러나, 그것의 높은 연산 복잡도는 실제 응용을 상당히 제한합니다.
RT-DETR은 최초의 실시간 end-to-end transformer based object detector입니다. 이는 효율적인 하이브리드 encoder와 IoU-aware queries selection 모듈, 그리고 확장 가능한 decoder layer를 사용하여, 다른 실시간 detector들 보다 더 나은 결과를 달성했습니다. 그러나, hungarian matching 전략은 학습 중에 sparse supervision을 제공하여, encoder와 decoder 모두의 불충분한 학습을 초래하고, 이는 해당 접근법의 최적 성능을 제한합니다. RT-DETRv2는 속도를 희생하지 않고 성능을 향상시키기 위해 학습 전략을 최적화함으로써 RT-DETR의 유연성과 실용성을 더욱 강화했지만, 더 긴 학습 시간을 필요로 합니다. object detection에서의 sparse supervision문제를 효과적으로 해결하기 위해, 본 논문에서는 hierarchical dense positive supervision 방법을 제안하는데, 이는 학습 중에 다중 aux branch를 도입함으로써 모델 수렴을 효과적으로 가속화하고 모델 성능을 강화합니다. 본 논문의 주요한 contribution은 다음과 같습니다:
- CNN 기반 O2M 라벨 할당 aux head를 도입하는데, 이는 최적화를 위해 원본 detection branch와 협력하여 encoder의 표현 능력을 더욱 강화합니다.
- 다중 query groups에 걸쳐 라벨 할당을 다양화함으로써 decoder의 supervision을 강화하는 것을 목표로 하는 self-attention perturbations을 포함한 학습 전략을 제안합니다. 추가로, 각 GT에 매칭되는 더 많은 고품질 queries들을 보장하기 위해 dense positive supervision을 위한 shared-weight decoder branch를 도입했습니다. 이러한 접근 방식들은 추가적인 추론 지연 시간 없이 모델의 성능을 향상시키고 수렴을 가속화 합니다.
- 아래의 그림 1. 과 같이 COCO dataset에서 유효성을 검증했습니다:

Related Work.
CNN-baed real-time object detection.
현재의 CNN 기반 실시간 객체 탐지기들은 주로 YOLO 시리즈입니다. YOLOv4와 YOLOv5는 네트워크 아키텍처를 최적화했고(예: CSPNet 과 PAN 채택), 동시에 Mosaic data augmentatioon을 활용했습니다. YOLOv6는 RepVGG backbone, decoupled head, SimSPPF, 그리고 더 효과적인 학습 전략(예: SimOTA)을 포함하여 구조를 더욱 최적화했습니다. YOLOv7은 서로 다른 level의 feature들을 더 잘 통합하기 위해 E-ELAN attention module을 사용하며, 작은 객체의 탐지를 개선하기 위해 adaptive anchor mechanism을 사용합니다. YOLOv8은 효과적인 feature extraction과 fusion을 위해 c2f 모듈을 제안했으며, YOLOv9는 새로운 GELAN 아키텍처를 제안하고 학습 과정을 강화하기 위해 PGI를 설계했습니다.
Transformer-based real-time object detection.
RT-DETR은 최초의 real-time end-to-end object detector입니다. 이 접근 방식은 intra-scale interaction과 cross-scale fusion을 분리하여 multi-scale feature를 효과적으로 처리하는 효율적인 하이브리드 encoder를 설계하고, decoder에 더 높은 품질의 초기 queries를 제공함으로써 성능을 더욱 향상시키기 위해 IoU-aware queries selection을 제안합니다. 이의 정확도와 속도는 같은 시기의 YOLO 시리즈보다 우수합니다. RT-DETRv2는 쉬운 배초를 위한 동적 데이터 증강 및 최적화된 샘플링 연산자를 포함한 학습 전략을 더욱 최적화하여, 모델 성능의 추가적인 향상을 가져왔습니다. 그러나, 그들의 O2O sparse supervision 때문에, 수렴 속도와 최종 효과는 제한적입니다. 따라서, O2M 라벨 할당 전략을 도입하는 것은 모델 성능을 더욱 향상시킬 수 있습니다.
Auxiliary training strategy.
Co-DETR은 multiple parallel O2M 라벨 할당 aux head training 전략들(예: ATSS 및 Faster RCNN)을 제안했는데, 이는 end-to-end decoder의 학습 능력을 쉽게 강화할 수 있습니다. 예를 들어, ViT-CoMer와 Co-DETR의 총합은 COCO detection task에서 SOTA를 달성했으며, DAC-DETR, MS-DETR, GroupDETR은 주로 모델의 decoder에 O2M supervision을 추가함으로써 수렴을 가속화합니다:
[CoIn] 논문 리뷰 | Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment (Chen et al., 2023)
https://arxiv.org/abs/2207.13085 Group DETR: Fast DETR Training with Group-Wise One-to-Many AssignmentDetection transformer (DETR) relies on one-to-one assignment, assigning one ground-truth object to one prediction, for end-to-end detection without NMS po
hw-hk.tistory.com
하지만 위 모델들은 real-time object detector가 아닙니다. 이들에 영감을 받아, 본 논문에서는 RT-DETR의 encoder와 decoder 모두에 multiple O2M aux dense supervision들을 도입합니다. 이 모듈들은 RT-DETR의 수렴 속도를 강화하고 전반적인 성능을 향상시키며, 이들은 오직 학습 단계에만 관여하기 때문에, RT-DETR의 추론 지연 시간에 영향을 미치지 않습니다.
Method.
Overall Architecture.

RT-DETRv3의 전체 구조는 위 그림 2.와 같습니다. RT-DETR의 전체 프레임워크(노란색)를 유지하면서, 추가적으로 본 논문에서 제안한 hierarchical decoupling dense supervision 방법(녹색)을 도입했습니다. 초기에 입력 이미지는 CNN backbone(예: ResNet)과 Efficient Hybrid Encoder라고 불리는 feature fusion module을 통해 처리되어 multi-scale feature map C3, C4, C5를 얻습니다. 이 features들을 그 후 CNN 기반의 O2M aux branch와 transformer 기반의 decoder branch에 병렬로 입력됩니다.
CNN 기반 O2M aux branch의 경우, encodoer feature representation을 헙력적으로 감독하기 위해 PP-YOLOE와 같은 기존의 최첨단 dense supervision 방법을 사용합니다. transformer 기반 decoder branch에서는 multi-scale features들이 먼저 flatten되고 concatenated 됩니다. 그런 다음 queries selection 모듈을 사용하여 그들 중 top-k개의 feature를 선택해 object queries를 생성합니다.
decoder 내부에서 여러 세트의 random mask를 생성하는 mask generator를 도입합니다. 이 masks들은 self-attention module에 적용되어 queries들 간의 상관관계에 영향을 미치고, 따라서 positive queries의 할당을 다르게 만듭니다. 위 그림2.에서 OQ^{o2o-1}, ..., OQ^{o2o-n}으로 묘사된 바와 같이, 각 random mask set는 대응하는 queries들과 짝을 이룹니다. 게다가, 각 GT에 매칭되는 고품질 queries들이 더 많이 존재하도록 보장하기 위해, decoder 내부에 O2M 라벨 할당 branch를 통합합니다.
Overview of RT-DETR.
RT-DETR은 object detection task를 위해 설계된 real-time detection framework입니다. 이는 추론 속도와 탐지 정확도를 최적화하면서 DETR의 end-to-end 예측의 장점을 통합합니다. 실시간 성능을 달성하기 위해, encoder 모듈은 경량 CNN backbone과 효율적인 feature fusion을 위해 설계된 efficient hybrid encoder 모듈로 대체됩니다. RT-DETR은 고신뢰도 feature를 object queries로 선택하여 queries 최적화의 난이도를 줄이는 uncetainty-minimal queries selection 모듈을 제안했습니다.
이어서, decoder의 여러 layers들은 self-attention과 cross-attention, FFN 모듈을 통해 이러한 queries들을 강화하며, 예측 결과는 MLP 층에 의해 생성됩니다. 학습 최적화 과정동안, RT-DETR은 O2O 할당을 위해 hungarianc matching을 사용하며, loss 계산을 위해, bbox regression에 대해서는 L1 loss와 GIoU loss를 사용하고, classification에 대해서는 VFL(variable focus loss)를 사용합니다.
One-to-Many Auxiliary Branch Based on CNN.
decoder의 O2O 매칭 방식으로 인해 발생하는 encoder 출력의 sparse supervision 문제를 완화하게 위해, PP-YOLOE와 같은 O2M 할당을 가진 auxiliary detection head를 도입합니다. 이 전략은 encoder supervision을 효과적으로 강화하여, 모델의 수렴을 가속화할 수 있는 충분한 표현 능력을 갖추게 할 수 있습니다. O2M 매칭 알고리즘의 경우, PP-YOLOE head의 설정을 따라 학습 초기에는 ATSS matching algorithm을 사용하고, 이후에는 TaskAlign matching algorithm으로 전환합니다.
Note: PP-YOLOE는 Baidu에서 개발한 object detection 모델로, YOLO 시리즈의 고성능 버전 중 하나입니다. RT-DETRv3는 transformer based model이지만, PP-YOLOE의 head만 떼어와서 encoder 옆에 붙여놓고, encoder가 CNN based 모델의 dense supervision으로 학습할 수 있도록 합니다.
Note: ATSS와 TaskAlign 라벨 할당은 무엇일까요? ATSS는 Adaptive Training Sample Selection의 약자로, 학습 초기에 많이 사용합니다. 예전에는 "IoU가 0.5가 넘으면 정답"과 같은 고정된 기준을 사용했습니다. ATSS는 각 GT 주변에 있는 후보 anchor들의 IoU 평균과 표준편차를 계산하여, Threshold를 평균 + 표준편차로 설정하여, 이 기준을 넘는 것들만 정답이라고 인정하는 방법입니다. 이는 모델의 성능이 불안정한 학습 초기에는 통계적 기준을 통해 threshold를 잡아주는게 안정적입니다. 반면, TAL(Task Alignment Learning)은 학습 중후반에 사용하며, 분류도 잘하고 위치도 정확한 박스를 positive sample로 설정합니다.
https://arxiv.org/abs/2108.07755
TOOD: Task-aligned One-stage Object Detection
One-stage object detection is commonly implemented by optimizing two sub-tasks: object classification and localization, using heads with two parallel branches, which might lead to a certain level of spatial misalignment in predictions between the two tasks
arxiv.org
classification 및 regression task의 학습을 위해, VFL과 DFL(Distributed Focus Loss)를 각각 사용하며, 그중 VFL은 positive sample에 대한 타겟으로 IoU score를 사용하는데, 이는 높은 IoU를 가진 positive sample이 loss에 상대적으로 더 많이 기여하게 만듭니다. decoder head 또한 task 정의의 일관성을 보장하기 위해 VFL을 사용합니다. CNN auxiliary branch의 loss를 L_{aux}로 표기하며, 대응하는 loss 가중치는 α로 표기합니다.
Note: VFL은 Varifocal Loss의 약자로, negative sample은 focal loss와 같이 가중치를 깎지만, 귀중한 positive sample의 가중치는 깎지 않습니다. 대신 target 값인 IoU score를 가중치로 곱해줍니다. 즉, IoU가 높은 bbox일수록 더 강하게 학습할 수 있습니다. 한편, DFL은 bbox의 좌표를 예측할 때 사용하는 loss function으로, 이전에는 bbox의 좌표를 "10이면 10". 이런식으로 regression 문제로 풀었지만, DFL은 확률 분포로 예측합니다. 예를 들어, 이전에는 "10이면 10"이라고 예측했지만, 이제는 "9일 확률 20%, 10일 확률 60%, ... "으로 예측합니다. 이렇게 하면 경계가 모호한 물체에 대해서도 uncertainty을 고려하여 유연하게 학습할 수 있으며, 물체의 경계가 불분명하거나, 가려져 있는 경우 성능을 크게 높여줍니다.
Multi-Group Self-Attention Pertubation Branches Based on Transformer.
decoder는 일련의 transformer blocks들로 구성되며, 각 block은 self-attention, cross-attention, FFN 모듈을 포함합니다. 초기에, queries들은 feature representation을 강화하거나 약화시키기 위해 self-attention 모듈을 통해 서로 상호작용합니다. 이어서, 각 query는 cross-attention 모듈을 통해 encoder feature로부터 정보를 검색하여 자신을 업데이트 합니다. 마지막으로, FFN은 각 query에 대응하는 target class와 bbox 좌표를 예측합니다. 그러나, RT-DETR에서 O2O 집합 매칭은 sparse supervision을 초래하여, 궁극적으로 모델의 성능을 저해합니다.
동일한 target과 연관된 여러 관련 queries들이 positive sample 학습에 참여할 기회를 갖도록 보장하기 위해, 본 논문에서는 mask self-attention에 기반한 multiple self-attention perturbation modules를 제안합니다. 이 perturbation module의 구현 세부 사항은 위 그림 2.에 나와있으며, 먼저 queries selection module을 통해 여러 세트의 object queries들을 생성하며, 이를 OQ_i라고 표기합니다. 이에 대응하여, mask generator를 사용하여 각 OQ_i 세트에 대한 무작위 perturbation mask M_i를 생성합니다. OQ_i와 M_i는 모두 mask self-attention module에 입력되어, perturbation되고 융합된 feature를 결과로 내놓습니다.
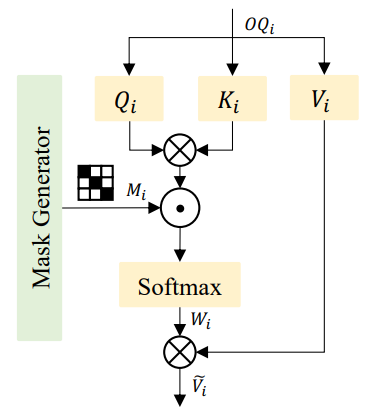
위 그림 3.은 mask self-attention 모듈의 상세한 구현입니다. OQ_i는 linear projection을 통해 Q_i, K_i, V_i를 얻습니다. 그런 다음, Q_i와 K_i를 곱하여 attention score를 계산하고, 이는 M_i와 추가로 곱해진 후 softmax 함수를 통과하여 perturbated attention score를 산출합니다. 마지막으로, 이 attention score는 V_i와 곱해져 융합된 \tildeV_i를 얻습니다. 이 과정은 다음과 같이 표현할 수 있습니다:
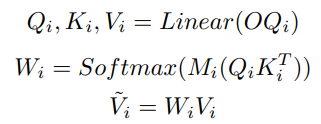
multiple set의 random perturbation은 queries의 특징을 다양화하여, 동일한 target과 연관된 여러 관련 queries들이 positive sample queries로 할당될 기회를 갖게 하고, 그에 따라 supervision 정보를 풍부하게 합니다. 학습 중에는, 여러 세트의 object queries들이 concatenation되어 단일 decoder branch로 입력되므로, 파라미터 공유를 가능하게 하고 학습 효율성을 높입니다. loss 계산과 라벨 할당은 RT-DETR과 일관되게 유지됩니다. i-th set의 loss를 L_i^{o2o}로 표기하며, N개의 perturbation set에 대한 총 loss는 다음과 같이 계산됩니다:
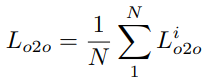
이에 대응하는 loss 가중치는 β로 표기합니다.
One-to-Many Dense Supervision Branch Based on Transformer.
multiple group self-attention perturbation branch의 이점을 극대화하기 위해, decoder에 가중치를 공유하는 추가적인 dense supervision branch를 도입합니다. 이는 GT에 매칭되는 고품질 queries가 더 많이 존재하도록 보장합니다. 고유한 object queries set를 생성하기 위해 queries selection module을 사용하며, sample matching 단계 동안, 학습 라벨을 m배(기본값 4)로 복제하여 증강된 target set가 생성됩니다. 이 증강된 세트는 이후 queries의 예측과 매칭됩니다. loss 계산은 원본 detection loss와 일관되게 유지되며, 이를 L_{o2m}으로 지정하고, 손실 가중치는 γ로 합니다.
따라서 total loss는 다음과 같습니다:
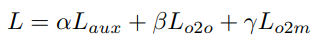
여기서 L_{aux}는 encoder의 dense supervision을 담당하고, L_{o2o}는 end-to-end 예측 특성을 보존하면서 decoder를 위한 O2O supervision 정보를 풍부하게 하며, L_{o2m}은 decoder에 O2M dense supervision을 제공합니다. 기본적으로 손실 가중치 α, β, γ는 1로 설정됩니다.
Experiments.
(... 자세한 실험 내용은 논문에서 ...)