
1. Selenium
Selenium 은 웹을 동작시키는 하나의 도구입니다. Selenium 패키지가 자주 업데이트 되기 때문에 Selenium 을 설치하는 방법은 매번 달라집니다. 우선 Colab 환경에서 Selenium 을 설치하는 방법입니다.
from google.colab import drive
drive.mount('/content/drive')
!pip install selenium
!apt-get update
!apt install chromium-chromedriver
# !cp /usr/lib/chromium-browser/chromedriver '/content/drive/MyDrive/Colab Notebooks' # (최초 1회)
!pip install chromedriver-autoinstaller
그 후 Selenium 의 설치를 확인하기 위해 다음과 같은 코드를 실행합니다.
# selenium 설치 확인
!python --version
import selenium
print(selenium.__version__)
# out: Python 3.10.12 \n 4.31.1
그리고 설치된 Selenium 을 세팅해줍니다.
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import sys
from selenium.webdriver.common.keys import Keys
import urllib.request
import os
from urllib.request import urlretrieve
import time
import pandas as pd
import chromedriver_autoinstaller # setup chrome options
chrome_path = "/content/drive/MyDrive/Colab Notebooks/chromedriver"
sys.path.insert(0,chrome_path)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') # Colab은 새창을 지원하지않기 때문에 창을 띄우지 않는 Headless 모드로 실행해야 합니다.
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage') # set path to chromedriver as per your configuration
chrome_options.add_argument('lang=ko_KR') # 한국어
chromedriver_autoinstaller.install() # set the target URL
모든 세팅이 끝나면 이제 동적 크롤링을 할 준비가 완료된 것입니다.
2. 동적 크롤링
동적 크롤링을 위해 driver 를 생성 해주고, driver 에 url 을 넣어줘 동적 크롤링을 준비합니다.
driver = webdriver.Chrome(options = chrome_options)
# 네이버에서 제공하는 PARIS 2024 링크
url = 'https://m.sports.naver.com/paris2024/news?date=20240803&sort=popular&isPhoto=N' # URL을 자세히 살펴보면 우리가 검색한 정보를 찾아볼 수 있습니다.
# 드라이버로 URL 접속하기
driver.get(url) # .get() 을 통해 driver 를 url 에 접속시킬 수 있습니다.
driver 객체는 requests 와 마찬가지로 BeautifulSoup 에 HTML 소스 코드를 넣어주는 것이 가능합니다.
.page_source 라는 속성 변수를 통해서 HTML 소스 코드에 접근 가능합니다. 이를 이용하여 soup 객체를 만들어줍니다.
html = driver.page_source
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
2024.08.07 - [[Deep daiv.] 복습] - [Deep daiv.] TIL - 1. 정적 크롤링
[Deep daiv.] TIL - 1. 정적 크롤링
1. 웹 크롤링 크롤링? 스크래핑? 웹 크롤링은 인터넷 상에 존재하는 모든 웹 페이지를 방문하며 데이터를 수집하는 방법입니다. 크롤링은 대부분의 검색 엔진에서 사용되며(* Page Rank) 이를 통해
hw-hk.tistory.com
에서 살펴보았듯이 soup 의 .find() 나 .find_all() 메소드의 인자로 정규 표현식을 넣어줄 수 있는데,
re 모듈을 통해 사용 가능합니다.
이를 이용하여, 뉴스들을 가져오겠습니다.
# 정규표현식 라이브러리
import re
# BeautifulSoup 으로 뉴스 리스트 영역 설정
news_section = soup.find('div', re.compile('NewsList_comp_news_list'))
# 영역 내에서 뉴스 리스트 불러오기
news_tag_list = news_section.find_all('li', re.compile('NewsList'))
이때 List 의 형태로 저장되어있는 뉴스 리스트의 내용을 활용하여
원하는 내용을 Map 함수를 통해 List 의 형태로 저장합니다.
# Map 함수를 활용해 뉴스 제목 리스트 만들기
list(map(lambda x: x.find('span', re.compile('NewsList_title')).text, news_tag_list))
# Map 함수를 활용해 뉴스 속성 리스트 만들기
list(map(lambda x: x.find('a', re.compile('NewsList_link')).get('href'), news_tag_list))
Selenium 의 기능을 활용하면, 동적으로 웹을 탐색할 수 있습니다.
아래는 뉴스의 '더보기' 버튼을 눌러 더 많은 뉴스를 탐색하는 예시입니다.
(* 참고로 버튼의 Xpath 는 개발자모드의 복사 > Xpath 복사 를 통해 얻을 수 있습니다. 그리고 반드시 Xpath 가 아닌 ID 나 Class, CSS 선택자를 통해서도 얻을 수 있습니다.)
# Selenium의 기능을 활용해 Xpath로 요소를 찾고, 버튼 클릭하기
news_more_button = driver.find_element(By.XPATH, '//*[@id="content"]/div[2]/div/div[1]/div[1]/div[2]/button')
news_more_button.click()
# Python 응용: 반복문을 활용해 버튼 클릭하기
import time
n = 0
for i in range(10):
news_more_button.click()
time.sleep(2) # 웹을 동작시킨 후, 정보를 불러올 수 있도록 충분히 시간을 기다려야 합니다.
n += 1
print(f'{n}회 클릭했습니다.')
다시 돌아와서 동적으로 모은 데이터들을 List 로 저장했는데,
이를 zip() 을 활용해 tuple 형태로 만든 다음 다시 List 의 형태로 저장해줍니다.
이를 통해 DataFrame 에 저장하기 쉬운 형태로 바뀌었습니다.
# 다시 소스 코드 불러오기
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
news_section = soup.find('div', re.compile('NewsList_comp_news_list'))
news_tag_list = news_section.find_all('li', re.compile('NewsList'))
news_title_list = list(map(lambda x: x.find('span', re.compile('NewsList_title')).text, news_tag_list))
news_link_list = list(map(lambda x: x.find('a', re.compile('NewsList_link').get('gref'), news_tag_list))
# 수집된 뉴스 개수 확인
print(f'뉴스 제목 수: {len(news_title_list)}, 뉴스 링크 수: {len(news_link_list)}')
# Zip 함수를 활용해 뉴스 리스트 만들기
news_list = list(zip(news_title_list, news_link_list))
이를 Pandas 를 활용해 데이터 프레임에 저장해줍니다.
import pandas as pd
df = pd.DataFrame(news_list, columns = ['title', 'url'])
결과
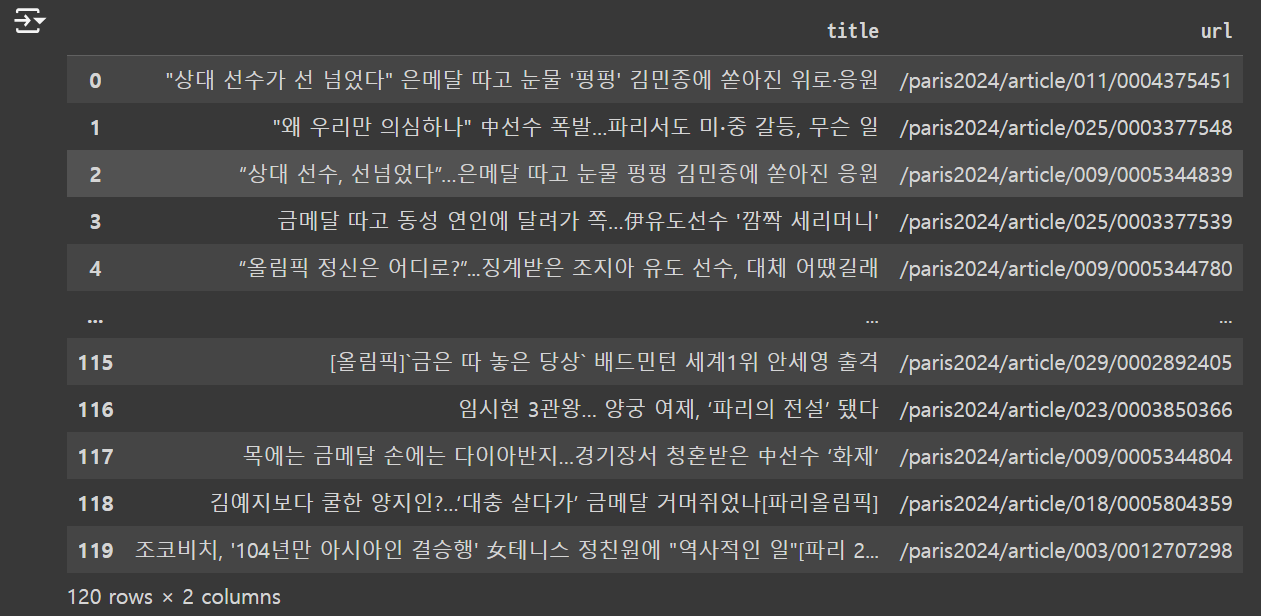
3. 추가
url 은 많은 정보를 담고 있습니다. 예를 들어 네이버 스포츠의 url 을 보겠습니다.
'https://m.sports.naver.com/paris2024/news?date=20240803&sort=popular&isPhoto=N'
뉴스, PARIS NOW : 네이버 스포츠
PARIS NOW의 모든 것, 네이버 스포츠와 함께 하세요
m.sports.naver.com
여기에서 date = {} 부분을 우리가 원하는 날짜로 바꿔준다면,
원하는 날의 뉴스 기사를 볼 수 있을 것입니다.
또한 sort = {} 부분을 우리가 원하는 정렬방식으로 바꿔준다면
또 다른 형태의 뉴스 기사들을 볼 수 있을 것입니다.
이를 활용하여 날짜별로 데이터를 수집할 수 있습니다.
date_range = pd.date_range('2024-07-15', '2024-08-04').strftime('%Y%m%d')
# 2024-07-15 부터 2024-08-04 까지의 date_range 를 만들어줍니다.
# .strftime 을 통해 원하는 형태로 date_range 를 포매팅 해줍니다.
# 반복문을 활용해 날짜별로 데이터 수집하기
from tqdm.auto import tqdm # 반복문의 반복 수를 바(bar) 로 표현해주는 모듈
total_news_list = []
for date in tqdm(date_range):
url = f'https://m.sports.naver.com/paris2024/news?date={date}&sort=popular&isPhoto=N'
driver.get(url)
time.sleep(2) # url 로 driver 가 이동하는 것을 기다려 줌
news_more_button = driver.find_element(By.XPATH, value = '//*[@id="content"]/div[2]/div/div[1]/div[1]/div[2]/button')
for i in range(5):
try:
news_more_button.click()
time.sleep(2)
print(f'{date}: {i+1}회 클릭했습니다.')
except:
next
html = diver.page_source
soup = BeautifulSoup(html, 'html.parser')
news_section = soup.find('div', re.compile('NewsList_comp_news_list'))
news_tag_list = news_section.find_all('li', re.compile('NewsList'))
news_title_list = list(map(lambda x: x.find('span', re.compile('NewsList_title')).text, news_tag_list))
news_link_list = list(map(lambda x: x.find('a', re.compile('NewsList_link')).get('href'), news_tag_list))
date_list = [date] * len(news_link_list)
daily_news_list = list(zip(news_title_list, news_link_list, date_list))
total_news_list.extend(daily_news_list)
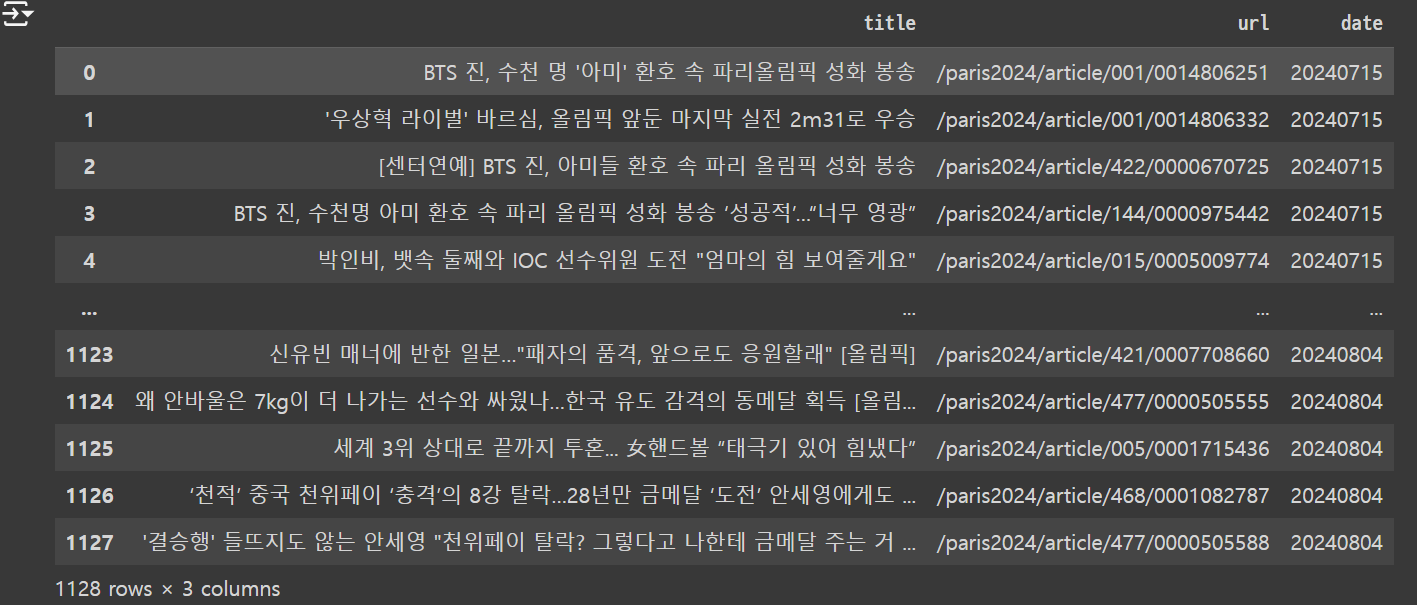
df = pd.DataFrame(total_news_list, columns = ['title', 'url', 'date'])
결과
배움
requests 를 통해서는 html 소스 코드가 전부 불러올 수 없을 때도 있다. 이럴 때는 Selenium 을 사용해보자
'[Deep daiv.] > [Deep daiv.] 복습' 카테고리의 다른 글
| [Deep daiv.] TIL - 4.1 k-NN 알고리즘과 의사 결정 나무 (1) | 2024.08.11 |
|---|---|
| [Deep daiv.] TIL - 4강. 지도 학습(분류) (0) | 2024.08.11 |
| [Deep daiv.] TIL - 3.1 차원축소와 클러스터링 (0) | 2024.08.09 |
| [Deep daiv.] TIL - 3. 비지도 학습 (0) | 2024.08.09 |
| [Deep daiv.] TIL - 1. 정적 크롤링 (0) | 2024.08.07 |