
0. 기본 세팅
우선 한글 폰트를 설치하고, seaborn 에 한글 폰트를 설정을 해야합니다.
# 한글 폰트 설치
# 이 셀을 실행시키고 '런타임 > 세션 다시 시작'을 해주세요
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rfimport matplotlib.pyplot as plt
import seaborn as sns
# 한글 폰트 설정
sns.set_theme(font ='NanumGothic',
rc = {'axes.unicode_minus' : False},
style ='whitegrid')
# 샘플 플롯 생성
plt.figure(figsize=(8, 6))
plt.plot([-2, -1, 1, 2], [1, 4, 9, 16], marker='o')
plt.title('한글 폰트 테스트')
plt.xlabel('X 축')
plt.ylabel('Y 축')
plt.grid(True)
# 플롯 표시
plt.show()
1. 주제 및 데이터 수집
포켓몬스터 데이터를 가져와 클러스터링을 기반으로 여러 클러스터로 나눠보는 것을 해보겠습니다.
이를 위해서 우선 포켓몬스터 데이터를 스크랩해줍니다.
# 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
import pandas as pd
import re
# soup 객체를 리턴해주는 함수 생성
def get_soup(url):
r = requests.get(url)
html = r.text
soup = BeautifulSoup(html, 'html.parser')
return soup
url 를 받아, soup 객체를 이용해 데이터를 받아옵니다.
# BeautifulSoup 으로 영문 포켓몬 도감 수집
url = 'https://pokemondb.net/pokedex/all'
soup = get_soup(url)
# 표 태그 찾기
html_tag = soup.find('table')
# 해당 url 에서 포켓몬에 대한 데이터는 table 태그로 구성되어있습니다.
# 만약 테이블로 구성되어있다면 이를 바로 DataFrame 으로 만들어줄 수 있습니다.
# 표를 데이터 프레임으로 바로 가져오기
from io import StringIO
html_table_str = str(html_table) # html_table은 soup의 데이터로 되어 있기 때문에 문자열 데이터로 변경해주어야 합니다.
html_table_io = StringIO(html_table_str) # StringIO() 는 String 을 file 객체처럼 만들어줍니다.
en_df = pd.read_html(html_table_io)[0] # 표를 리스트 형태로 반환하기 때문에 인덱싱을 해줘야 합니다.
# pd.read_html() 은 html 소스 코드를 매개변수로 받기 때문에, 만약 html 에 테이블이 많은 경우를 대비해서 list 의 형태로 반환합니다.
# 따라서 인덱싱이 필요한 것입니다.
결과
나머지 데이터를 얻기 위해 한글 포켓몬 도감을 수집해줍니다.
그리고 마찬가지로 데이터 프레임을 만들어서 저장해줍니다.
# 한글 포켓몬 도감 수집
url = 'https://pokemon.fandom.com/ko/wiki/%EC%A0%84%EA%B5%AD%EB%8F%84%EA%B0%90'
soup = get_soup(url)
# 한글 포켓몬 도감 데이터 프레임 생성
kr_df = pd.DataFrame()
for html_table in soup.find_all('table')[:-1]:
# soup tag -> string -> file -> DataFrame
kr_df_part = pd.read_html(StringIO(str(html_table)))[0]
kr_df_part['지방'] = [re.sub('도감', '지방', kr_df_part.columns[0])] * len(kr_df_part)
kr_df = pd.concat([kr_df, kr_df_part])
결과
2. 전처리
한글 데이터에서 전국 도감 데이터를 기준으로 포켓몬 이름과 지방 이름을 영문 데이터에 merge 해주겠습니다.
우선 병합하고자 하는 부분한 slicing 해줍니다.
kr_df kr_df.loc[:, ['전국도감', '포켓몬', '지방']]
병합의 기준이 되는 전국 도감의 format을 맞춰줍니다.
(* 영문: column 이름: #, 데이터 format: int // 한글: column 이름: 전국 도감, 데이터 format: # 이 붙어있는 String)
# 병합을 위해 전국 도감 텍스트 전처리
kr_df['전국도감'] = kr_df['전국도감'].map(lambda x: int(re.sub('#', '', x)))
# df 에 .map 을 하면 각 column 의 데이터가 input 으로 들어온다
# 중복값 확인
kr_df['전국도감'].duplicated().sum()
# duplicated() 를 사용하면 중복된 값은 True, 아니면 False 로 반환되기에
# sum() 을 통해 중복된 값의 개수를 count 할 수 있다.
# 중복값 제거
kr_df.drop_duplicates(subset = ['전국도감'], inplace = True)
# drop_duplicates() 함수를 통해 중복값을 누락시킨다. inplace = True 로 해줌으로써 원본 데이터를 수정한다.
데이터의 format 을 맞춰줬으니, 이제 칼럼의 이름을 바꿔주고 merge 를 수행해줍니다.
# 칼럼명 변경
kr_df.columns = ['#', 'Name', 'Region']
# 데이터 병합
df = pd.merge(en_df, kr_df, on = '#', suffixes = ['_EN', ''])
결과
추가 전처리
포켓몬의 타입의 경우, 두 가지 타입이 있을 때, 타입을 따로 나눠주는 작업을 수행합니다.
또한 물리 공격과 물리 방어 수치를 더해준 물리(* Physical) 칼럼을 추가해줍니다.
또한 특수 공격과 특수 방어 수치를 더해준 특수(* Special) 칼럼을 추가해줍니다.
# 타입 분리하기
type_ = df['Type'].str.split()
# 타입 컬럼 추가
df['Type_1'] = type_.str[0]
df['Type_2'] = type_.str[1]
# 컬럼 연산
df['Pyhsical'] = df['Attack'] + df['Defense']
df['Special'] = df['Sp. Atk'] + df['Sp. Def']
결과
3. 데이터 시각화
데이터 시각화를 통해 인사이트를 얻어볼 수 있습니다.
우선 기본적으로 필요한 라이브러리를 불러옵니다.
# 기본적으로 필요한 라이브러리를 불러오기
from matplotlib import font_manager, rc, rcParams
import matplotlib.pyplot as plt
import seaborn as sns
# 시각화 설정
# Seaborn 에서 기본 스타일을 지정할 수 있습니다.
sns.set_theme(font ='NanumGothic',
rc = {'axes.unicode_minus' : False},
style ='whitegrid')
우선 지방별 포켓몬 수를 시각화 해보겠습니다.
# Countplot | 지방별 포켓몬 수 시각화
plt.figure(dpi = 100) # 해상도 설정
plt.xticks(rotation = 45, ha = 'right') # 45 도 기울이고 오른쪽 정렬
sns.countplot(x = 'Region', data = df)
plt.show()
결과

히스이 지방의 포켓몬의 수가 가장 적고, 관동 지방의 포켓몬 수가 가장 많음을 알 수 있습니다.
그렇다면 타입별 포켓몬의 종족값을 파악해보겠습니다.
# 고윳값 추출
# 타입병 카운트를 알아보기 위해 타입들을 추출합니다.
type_list = list(df['Type_1'].unique())
print(type_list)
# Boxplot | 타입_1 별 포켓몬의 능력치
plt.figure(figsize = (10,3), dpi = 150)
plt.xticks(rotation = 45, ha = 'right')
sns.boxplot(x = 'Type_1', y = 'Total', data = df)
plt.show()
결과
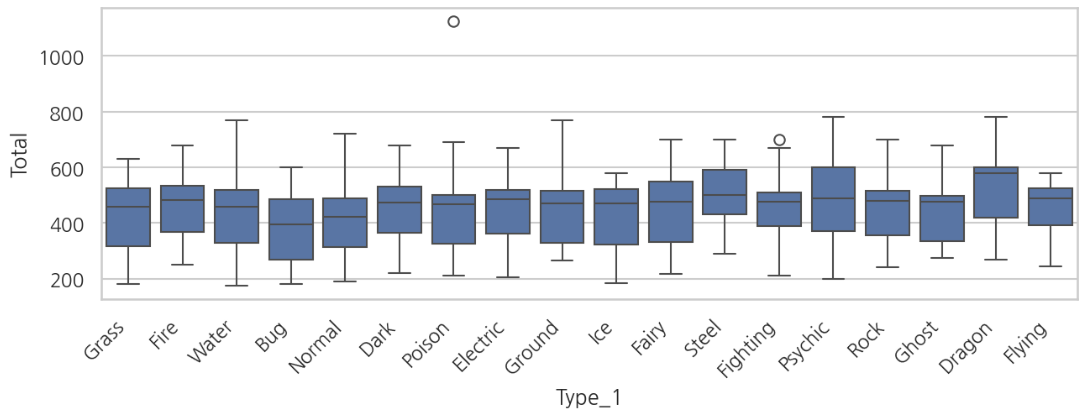
물, 땅, 드래곤 타입이 전체적으로 종족값이 높은것을 알 수 있습니다.
반면에 비행, 벌레 타입은 종족값이 낮습니다.
방어력과 스피드의 관계를 한 번 살펴보겠습니다.
# Scatterplot | 두 개의 연속형 데이터의 분포
# 두 개의 연속형 데이터가 있으면 거의 무조건 Scatterplot 을 그려보자
plt.figure(dpi=100)
sns.scatterplot(x = 'Defense', y = 'Speed', data = df)
plt.show()
결과
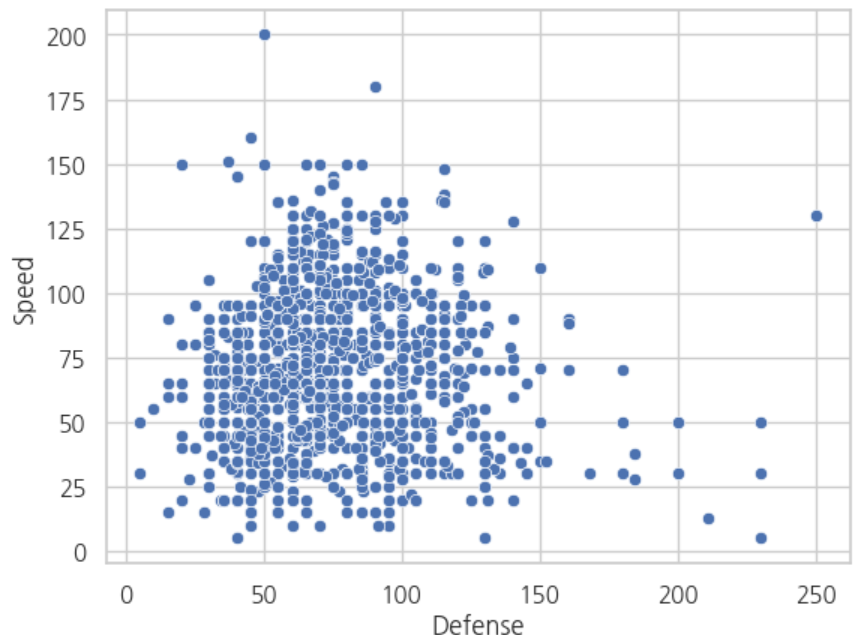
이 데이터에서 회귀선을 그려보면 어떨까요?
# Regplot | Scatterplot + Regression Line
plt.figure(dpi = 100)
sns.regplot(x = 'Defense', y = 'Speed', lowess = True, data = df, line_kws = {'color': 'skyblue'})
plt.show()
결과

회귀선을 통해 초반엔 방어력이 좋으면 스피드도 높다가, 가면 갈수록 반비례하는 모습을 볼 수 있습니다.
이를 통해, 방어력과 속도는 크게 관련이 없음을 알 수 있습니다.
그렇다면 모든 연속형 데이터의 Scatterplot 과 히스토그램을 보고 싶다면 어떻게 할까요?
Pairplot 을 사용하면 됩니다.
# Pairplot | 모든 연속형 데이터의 Scatterplot과 히스토그램을 보고 싶을 때
sns.pairplot(df[['HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed']])
plt.show()
4. 비지도 학습
2024.08.09 - [[Deep daiv.] 복습] - [Deep daiv.] 복습 - 3.1 차원축소와 클러스터링
[Deep daiv.] 복습 - 3.1 차원축소와 클러스터링
1. PCA 주성분 분석 고차원의 데이터를 낮은 차원의 데이터로 바꿀 때, 어떻게 바꿔야 최대한 특징을 살리면서 차원을 낮출 수 있을까를 고안하다가 나온것이 PCA 입니다. 그렇다면 어떻게 해야 '
hw-hk.tistory.com
데이터 군집화, Clustering 이라고도 불립니다. 이는 대표적인 비지도 학습 기법입니다. 포켓몬을 능력치에 따라 구분한다고 하더라도 어떤 기준으로 군집화해야 할지 모를 수 있습니다. 비지도 학습은 우리가 정답을 알지 못하더라고, 통계적인 기법을 이용해 군집을 나눌 수 있도록 도와줍니다.
하지만 이를 위해서는 차원 축소가 필수적입니다.
대표적인 차원축소 기법은 주성분 분석(* PCA) 와 t-SNE 가 있습니다.
우선 PCA 를 통한 차원축소를 해보겠습니다.
from sklearn.decomposition import PCA
pca = PCA(n_components = 2) # 차원을 2차원까지 축소합니다.
result_pca = pca.fit_transform(df.iloc[:, 4:10]) # 4 - 10 index 는 능력치에 관한 칼럼입니다.
df[['X', 'Y']] = result_pca # PCA 의 결과를 df 의 X, Y 칼럼에 저장해줍니다.
# PCA 차원 축소 결과
sns.scatterplot(x = 'X', y = 'Y', data = df)
plt.show()
결과

t-SNE 를 통한 차원 축소도 한 번 해보겠습니다.
from sklearn.mainfold import TSNE
tsne = TSNE(n_components = 2, learning_rate = 1000, random_state = 1201)
result_tsne = tsne.fit_transform(df.iloc[:, 4:10])
df[['X', 'Y']] = result_tsne
# t-SNE 차원 축소 결과
sns.scatterplot(x = 'X', y = 'Y', data = df)
plt.show()
결과
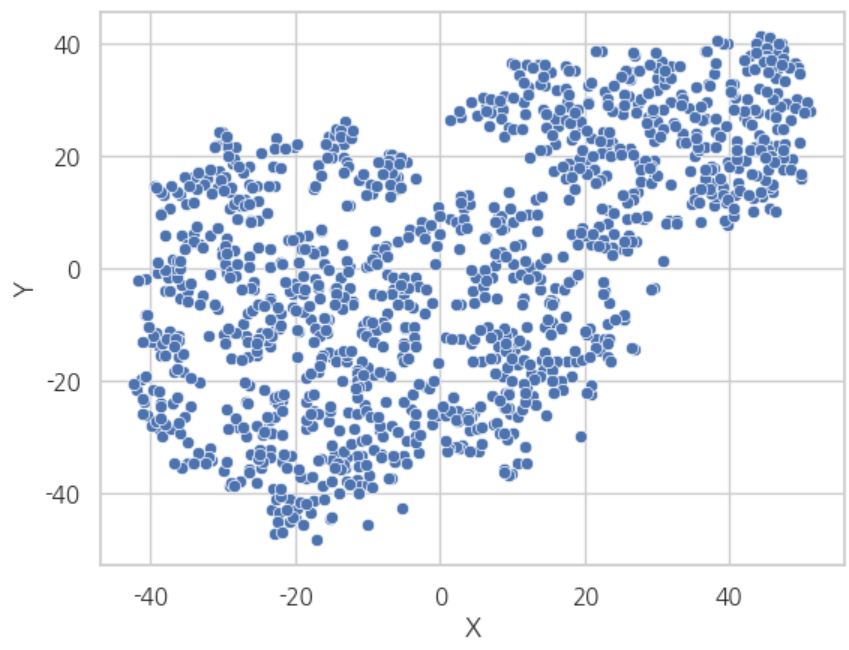
축소된 차원을 바탕으로 클러스터링을 진행하겠습니다.
클러스터링 모델은 크게 k-Means 알고리즘과 DBSCAN 이 있습니다.
간단하게 설명하자면,
k-Means 는 사전에 군집의 개수 k 를 하이퍼 파라미터로 주어주면 이를 바탕으로 군집을 나누는 모델입니다.
DBSCAN 은 밀도를 기반으로 군집을 나누는 모델입니다.
우선 k-Means 를 사용하겠습니다.
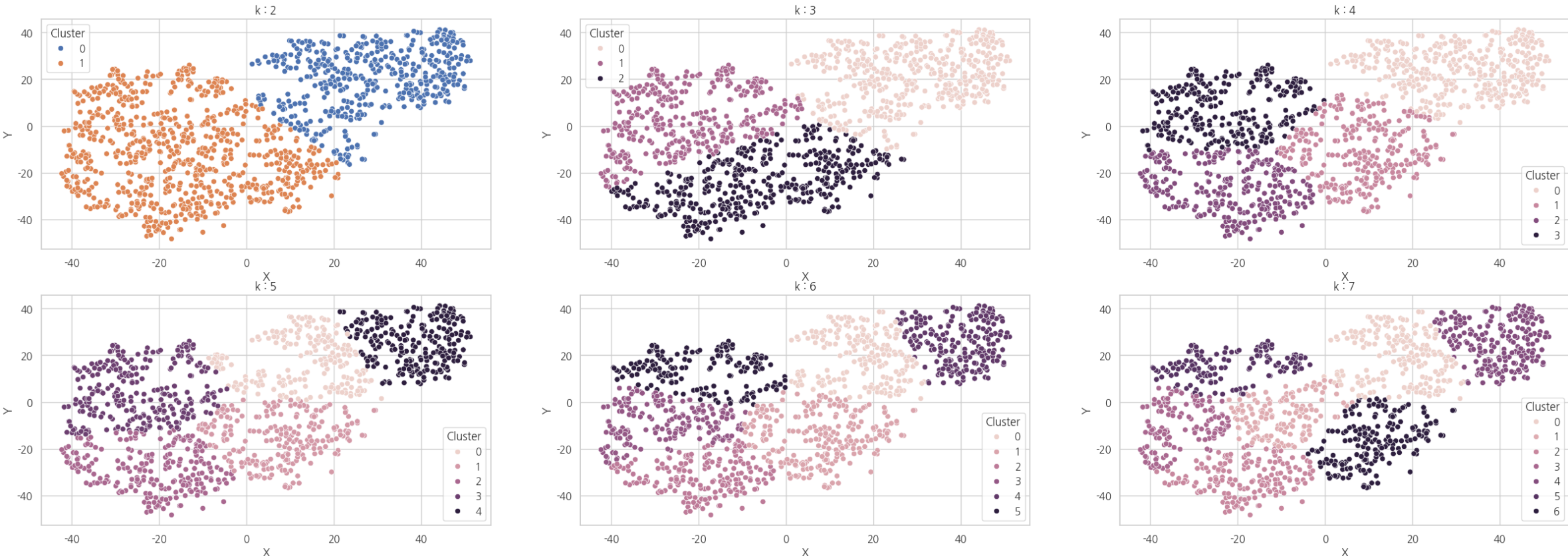
다음은 여러개의 k 를 파라미터로 넣었을 때의 군집 분석 결과입니다.
import numpy as np
Kmeans_hyper_params = np.arange(2, 8) # 2 부터 8 까지의 수를 k 로 넣습니다.
fig, axes = plt.subplots(2, 3, figsize = (30, 10))
for k, ax in zip(Kmeans_hyper_params, axes.flat): # axes 는 2차원이기에 .flat 을 해준다.
kmeans = KMeans(n_cluster = k, random_state = 1201, n_init = 'auto')
label = kmeans.fit_predict(df[['X', 'Y']])
df['Cluster'] = label
sns.scatterplot(x = 'X', y = 'Y', hue = 'Cluster', data = df, ax = ax)
ax.set_title(f'k = {k}')
plt.show()
결과
다음은 DBSCAN 을 이용한 군집 분석의 결과입니다.
import numpy as np
DBSCAN_hyper_params = np.arange(2, 5, 0.5) # 2부터 5까지(* 5 포함 x) 0.5 간격
fig, axes = plt.subplots(2, 3, figsize = (30, 10))
for eps, ax in zip(DBSCAN_hyper_params, axes.flat): # 축이 2차원이므로, 평탄화를 해준다.
cluster = DBSCAN(eps = eps)
label = cluster.fit_predict(df[['X', 'Y']])
df['Cluster'] = label
sns.scatterplot(x = 'X', y = 'Y', hue = 'Cluster', data = df, ax = ax)
ax.set_title(f'DBSCAN(epsilon = {eps})')
plt.show()
결과
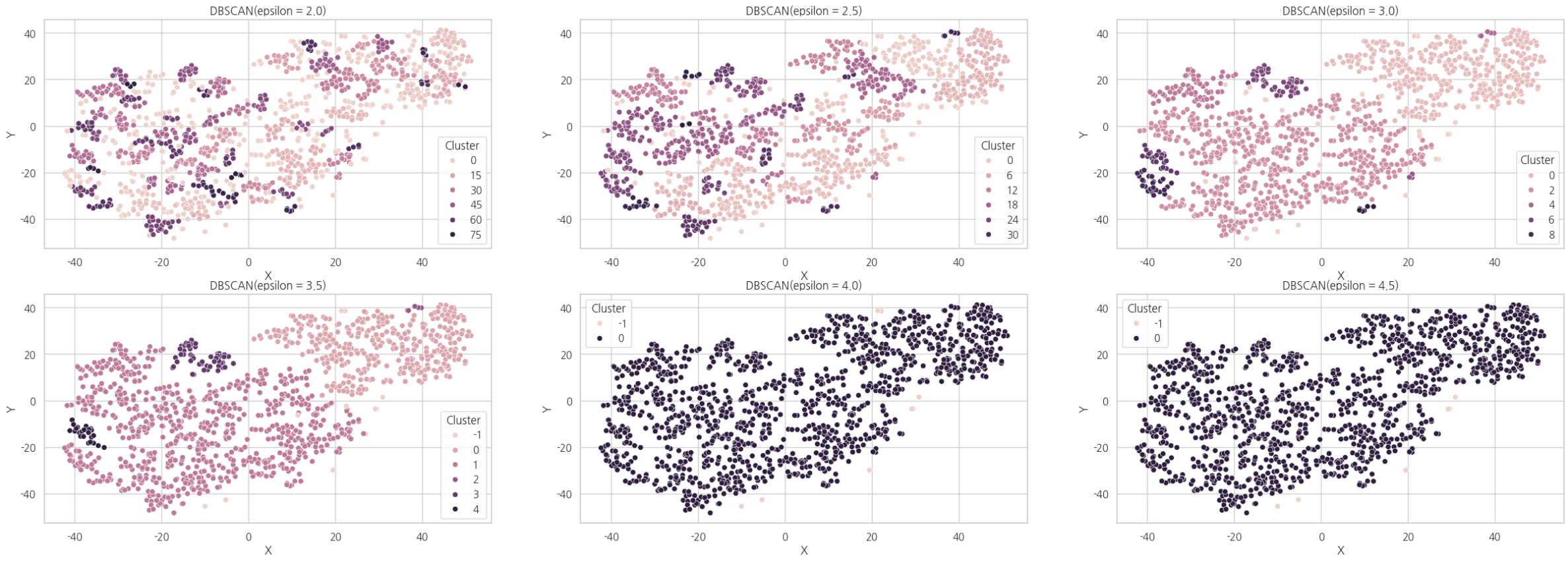
군집 분석 알고리즘이 어떤 기준으로 군집들을 나누었는지를 명시적으로는 알 수 없지만,
우리가 클러스터들 끼리 각종 데이터를 비교해가며 예측할 수는 있습니다.
먼저 용이한 분석을 위해 데이터를 재구조화 시킵니다.
(* pd.melt() 를 사용하여 각종 능력치 칼럼들을 데이터로 녹여냅니다.)
# 추출하고자 하는 컬럼명
cols = list(df.iloc[:,4:10].columns)
# 추출하고자 하는 컬럼명 추가
cols.extend(['Pysical', 'Special'])
# 데이터 재구조화 (pd.melt())
melted_df = pd.melt(df, id_vars = ['#', 'Cluster'], value_vars = cols, var_name = 'Stats', value_name = 'Stats', value_name = 'Value')
결과
이를 이용해 능력치 기준 클러스터들을 비교하거나, 클러스터 기준 능력치를 비교해볼 수 있습니다.
# 능력치 기준 클러스터 박스플롯
stats_list = list(melted_df['Stats'].unique())
fig, axes = plt.subplots(2, 4, figsize = (40, 10))
for stats, ax in zip(stats_list, axes.flat):
tmp_df = melted_df.loc[melted_df['Stats'] == stats, :]
sns.boxplot(x = 'Cluster', y = 'Value', data = tmp_df, ax = ax)
ax.set_title(stats)
ax.set_yticks(np.arange(0, 350, 50))
plt.show()
결과
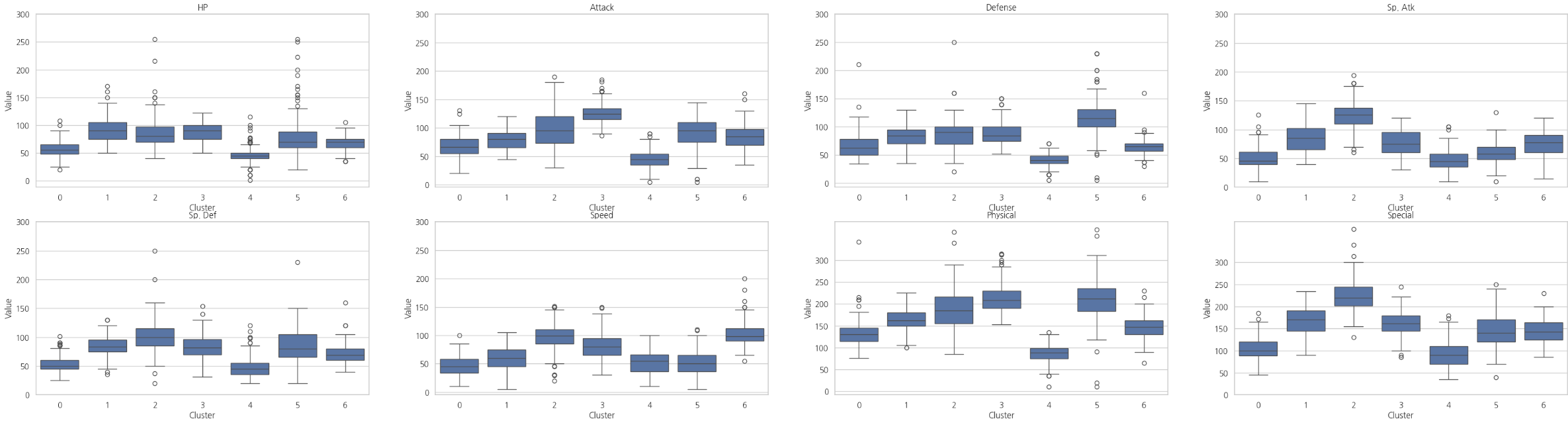
# 클러스터 기준 세부 능력치 박스플롯
cluster_list = np.arange(0, 7)
fig, axes = plt.subplots(2, 4, figsize = (40, 10))
for cluster, ax in zip(cluster_list, axes.flat):
tmp_df = melted_df.loc[melted_df['Cluster'] == cluster, :]
sns.boxplot(x = 'Stats', y = 'Value', data = tmp_df, ax = ax)
ax.set_title(cluster)
ax.set_yticks(np.arange(0, 350, 50))
plt.show()
결과

배움
html 의 table 태그의 경우 하나하나 df 로 옮길 필요없이 바로 옮길 수 있다는 점을 알았다.
군집분석을 하기 전에는 차원축소가 필요하다는 점을 알았다.
pd.melt 를 통해 df 의 분석을 좀 더 용이하게 할 수 있겠다...
subplots 의 axes 가 2차원일때 for 문을 돌리고 싶으면 .flat 을 사용하자
'[Deep daiv.] > [Deep daiv.] 복습' 카테고리의 다른 글
| [Deep daiv.] TIL - 4.1 k-NN 알고리즘과 의사 결정 나무 (1) | 2024.08.11 |
|---|---|
| [Deep daiv.] TIL - 4강. 지도 학습(분류) (0) | 2024.08.11 |
| [Deep daiv.] TIL - 3.1 차원축소와 클러스터링 (0) | 2024.08.09 |
| [Deep daiv.] TIL - 2. 동적 크롤링 (0) | 2024.08.09 |
| [Deep daiv.] TIL - 1. 정적 크롤링 (0) | 2024.08.07 |