
Human langauge and word meaning
인간의 언어는 맥락이 있고, 상황마다 다르게 해석될 수 있습니다. 그래서 사람들에게 언어는 유용한 도구가 될 수 있지만, 반대로 컴퓨터에게는 이해하기 어려운 지점입니다.
How do we represent the meaning of a word?
어떤 단어의 뜻을 표현할 때는 흔히 어떤 생각이나 실제 물체와 단어를 연관짓는 방법을 사용합니다. 예를 들어 나무의 뜻을 표현할 때는 나무를 나타내는 그림이나, 나무에 대한 다른 생각들을 이용해서 표현합니다.

How do we have usable meaning in a computer?
하지만, 이런 단어의 뜻을 컴퓨터에 이식할 수는 없습니다(그림을 그려서 넣어줄 수도 없고). 그래서 이전에 NLP에서 사용하던 가장 흔한 방법으로는 WordNet이 있습니다. 이는 "is a"관계로 엮인 다양한 동의어들과 상/하위어들을 표현합니다.

Problems with resources like WordNet
이러한 WordNet기반의 단어 표현 방법은 여러 가지 문제점들을 갖고 있습니다. (1) 예를 들어, "proficient"와 "good"은 동의어로 연관되어있지만, 이는 일부 특별한 맥락에서만 그러합니다. 다른 단어들도 마찬가지 입니다. 즉, 맥락에 따라 달라질 수 있는 동의어관계를 파악할 수 없습니다. (2) 또한 어떤 단어의 새로운 뜻을 파악하기 힘듭니다. 사람이 직접 뜻을 만들어주고 적용해야하기 때문입니다. (3) 이에 따라 주관적인 기준에 따라 동의어관계가 설정된다는 문제도 있습니다. (4) 마지막으로 단어들간의 유사도를 정확하게 표현할 수 없다는 문제도 있습니다(다음 챕터 참조).
Representing words as discrete symbols
전통적인 NLP에서 단어은 이산적인(discrete) 심볼로서 표현됩니다. 이를 지역적인 표현(a localist representation)이라 하고, 이러한 심볼들은 흔히 원-핫 벡터(one-hot vector, means one 1, the rest 0s)로 표현됩니다.

이때 원-핫 벡터의 차원은 단어 vocabulary의 수와 동일합니다.
Problem with words as discrete symbols
이런 원-핫 벡터 표현방식에도 문제점이 있습니다. 예를 들어 웹 검색 시, "Seattle motel"과 "Seattle hotel"은 유사한 의미로서 사용될 수 있습니다. 하지만 원-핫 벡터로 표현할 때의 "motel"과 "hotel"은 위에 표현한 그림처럼 나타납니다. 이 두 벡터는 직교(orthogonal)하기 때문에, 유사도를 표현할 방법이 없습니다.
Representing words by their context
You shall know a word by the company it keeps
J.R. Firth 1957: 11
주변 단어의 의미를 통해 해당 단어의 의미를 유추하는 방법은 현대 통계 NLP에서 가장 성공한 아이디어 중 하나였습니다. 어떤 단어 w를 표현할 때, 맥락(context)은 단어 w의 주변에 있는 단어들의 집합으로 이뤄집니다. 따라서 단어 w를 표현할 때는 매우 다양한 맥락을 사용할 수 있습니다.

Word vectors
어떤 단어를 dense vector(one-hot vector는 sparse vector로 대부분의 요소가 0으로 채워져있는 vector 표현을 의미한다. 반대로 대부분의 요소가 0이 아닌 vector를 dense vector라고 부른다)로 표현할 때, 어떤 단어 벡터끼지의 유사도를 계산하려면 내적(dot product)를 수행하면 됩니다(spase vector와 달리 dense vector끼리는 직교하지 않기 때문에).

Word meaning as a neural word vector - visualization
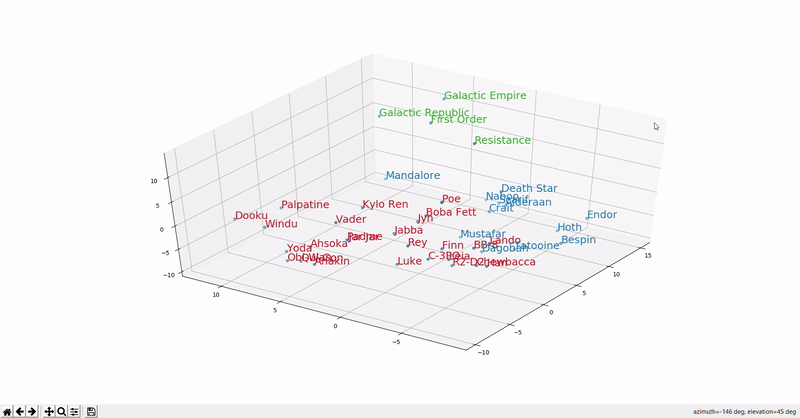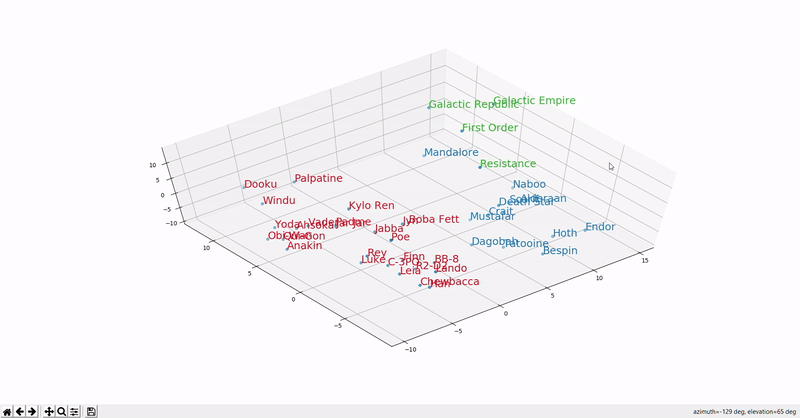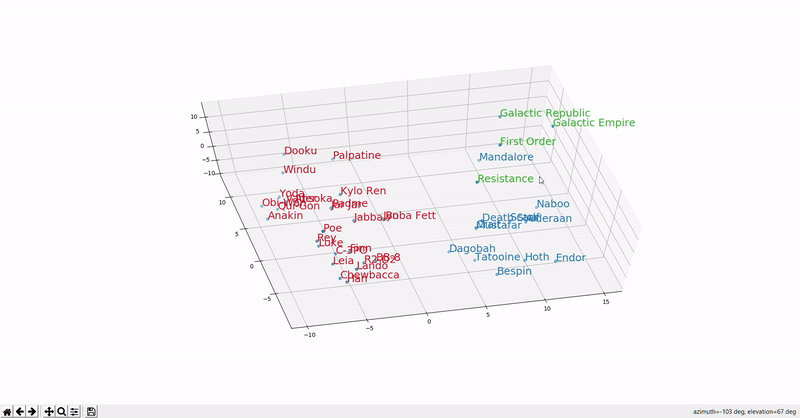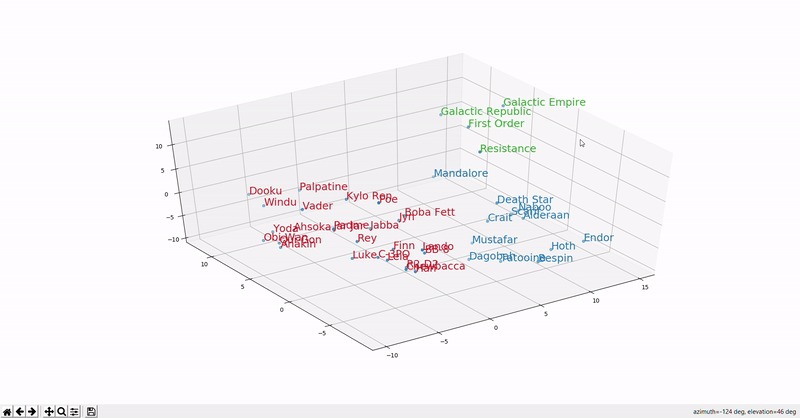
Word2vec: Overview
Word2vec (Mikolov et al. 2013)은 유명한 단어 임베딩 프레임워크입니다.
2024.08.16 - [[Deep daiv.]/[Deep daiv.] 복습] - [Deep daiv.] TIL - 6. Word2Vec을 활용한 단어 임베딩
[Deep daiv.] TIL - 6. Word2Vec을 활용한 단어 임베딩
0. 현재 상황 2024.08.14 - [[Deep daiv.] 복습] - [Deep daiv.] TIL & WIL - 5. 자연어 처리 & 텍스트 처리 (Contd.) [Deep daiv.] TIL & WIL - 5. 자연어 처리 & 텍스트 처리 (Contd.)이전 글2024.08.09 - [[Deep daiv.] NLP] - [Deep daiv.
hw-hk.tistory.com
많은 양의 말뭉치(corpus)가 있을 때, 모든 단어들을 하나의 고정된 벡터로 표현해야합니다. 이를 중심 단어 c와 맥락(outside) 단어 o를 이용해서 표현합니다. 중심 단어 c가 주어졌을 때, 주변 단어들 o가 나올 확률을 계산하기 위해서 c와 o의 유사도를 계산합니다. 그리고 이 확률을 최대화하는 방향으로 단어 벡터를 조정하는 것입니다.


Word2vec: object function
임의의 위치 t(= 1, ...,T)에 대해서, 고정된 window크기 m과 중심 단어 wt가 주어졌을 때, 맥락 단어에 대한 θ의 우도(likelyhood)는 다음과 같습니다:

이때의 목적함수(때로는 손실함수라고도 불리는) J(θ)는 negative log likelyhood입니다:
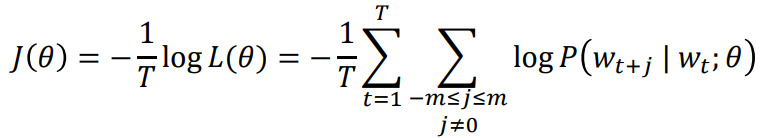
목적함수를 최소화하는 것은 예상 정확도를 최대화하는 것과 동일합니다.
이 목적함수를 최소화하려 할 때, 궁금한 점은 "P(|)에 해당하는 조건부 확률을 어떻게 구하냐?" 입니다. 이는 단어 w에 대한 두 가지의 벡터 표현을 통해 구할 수 있습니다. v_w는 단어 w에 대한 중심 단어 표현이고, u_w는 단어 w에 대한 맥락 단어 표현이라고 할 때, 조건부 확률은 다음과 같이 구할 수 있습니다:

해당 식을 다시 살펴보면,
(1) 분자에 있는 벡터들의 내적을 통해 중심 단어 c와 주변 맥락 단어 o의 유사도를 계산합니다. (2) 그리고 해당 값을 exp에 넣어서 값을 양수로 바꿔줍니다. (3) 마지막으로 모든 단어 벡터에 대해 정규화를 해주면, 중심 단어 c에 대한 맥락 단어 o의 조건부 확률을 계산할 수 있습니다.
참고로, 다음과 같은 식을 softmax함수라고 합니다.

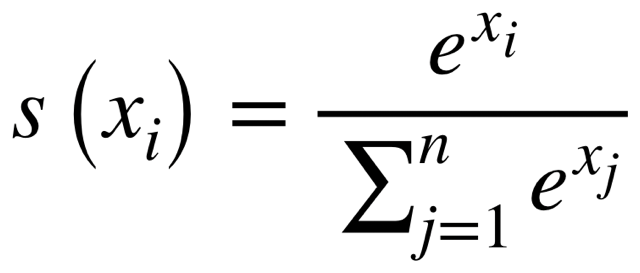
Softmax함수는 실수 집합에 대해 (0,1)의 확률 표현으로 매핑할 수 있는 함수입니다.
To train the model: Optimaize value of parameters to minimize loss
해당 모델을 학습하기 위해, loss값을 줄이는 방향으로 파라미터들을 적응시켜야합니다. Word2vec의 파라미터는 하나의 단어 표현에 대해 중심 단어 표현과 주변 단어 표현, 두 가지의 벡터 표현이 있을 수 있고, Word2vec의 임베딩 사이즈 d, 단어 vocabulary의 크기가 V일 때, θ는 는 2*d*V차원이 됩니다.

이에 대해 미분을 통해 loss를 줄이는 방향을 구할 수 있습니다:




Optimization: Gradient Descent
J(θ)를 줄이기 위해 GD(Gradient Descent) 알고리즘을 사용합니다. 이는 θ에 대해서 J(θ)의 미분값(경사)을 구한 후, 그 방향의 반대 방향으로 조금씩 이동하여 최적점을 찾는 방법을 말합니다.

이때의 새로운 θ값은 다음과 같은 식으로 구할 수 있습니다:

Stochastic Gradient Descent
이때 GD의 문제점이 있습니다. 만약 말뭉치에 있는 모든 window에 대해 해당 함수를 적용한다면, J(θ)를 계산하는 비용이 매우 클 것입니다. window의 개수, θ의 크기가 매우 크기 때문입니다. 따라서 SGD(Stochastic gradient descent)방식을 사용합니다. 이는 모든 window들에 대해 update를 하는 것이 아닌, 특정한 sample window에 대해서 단 한 번의 update만을 하는 방법입니다.
2025.01.08 - [[Deep daiv.]/[Deep daiv.] NLP] - [Deep daiv.] NLP - Optimizer 정리
[Deep daiv.] NLP - Optimizer 정리
Optimizer란? Optimizer는 머신러닝 혹은 딥러닝 모델이 주어진 목표 함수를 최소화(혹은 최대화)하도록 모델 파라미터(가중치, 편향 등)를 업데이트하는 절차나 알고리즘을 말합니다. 예를 들어 모
hw-hk.tistory.com
질문들
(1) Q: 어떤 단어에 대한 표현이 중심 단어 표현과 맥락 단어 표현, 이렇게 두 가지가 있다면, 최종적으로 사용하는 벡터 표현을 무엇인가요?
A: 두 벡터를 평균을 내서 사용하거나, 다양하게 사용할 수 있습니다.
출처
https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1234/index.html
Stanford CS 224N | Natural Language Processing with Deep Learning
Content What is this course about? Natural language processing (NLP) or computational linguistics is one of the most important technologies of the information age. Applications of NLP are everywhere because people communicate almost everything in language:
web.stanford.edu