
A bit more about Neural Networks
We have models with many parameters! Regularization!
규제 혹은 정규화는 매우 중요합니다. L2 정규화가 그 예시입니다:

전통적인 관점에서 정규화는 모델의 과적합(overfitting)을 막는데 매우 중요한 역할을 합니다. 이때 과적합이란 Training set에 너무 과하게 적합하여 실제 데이터 분포에 대해서는 성능이 좋지 못한 것을 말합니다:
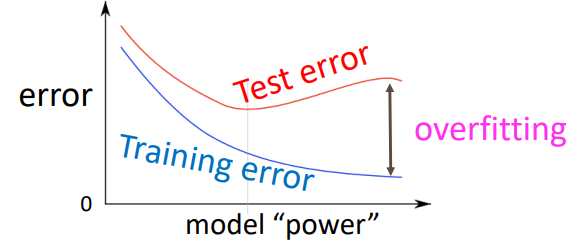
이렇게 과적합이 심한 모델의 경우, 실제 데이터 분포에 대해서는 정확하게 예측할 수 없기 때문에 적절한 수준에서 학습을 끝내줌으로써 과적합을 막는 것이 매우 중요합니다. 하지만 위에서 설명한 L2 정규화는 신경망에는 적용하기 힘듭니다. 신경망의 경우는 파라미터의 수가 너무 많고, 하나하나의 파라미터가 어떤 것을 의미하는지 모르기 때문에, 파라미터의 절댓값을 줄인다하여 과적합을 막는것을 보장하기 힘들기 때문입니다.
2024.03.30 - [[Deep daiv.]/머신러닝] - 머신러닝 공부 4.1 - 규제 Regularization
머신러닝 공부 4.1 - 규제 Regularization
0. 오버피팅 문제 모델을 한정된 데이터로 학습시키다 보면 모델이 학습 데이터셋에 대한 손실함수가 과하게 작아지는 경우가 생길 수 있습니다. 이런 경우 우리는 모델이 과적합되었다고 합니
hw-hk.tistory.com
그렇기 때문에 최근에는 파라미터의 절댓값을 줄이는 방향으로 정규화를 진행하지 않고, 일반화를 잘 할 수 있는 방향으로 정규화를 진행합니다. 그렇다면 일반화를 잘 하는 방법으로 무엇이 있을까요?
Dropout (Srivastava, Hinton, Krizhevsky, Sutskever, & Salakhutdinov 2012/JMLR 2014)
원어 그대로 표현하면 Dropout은 다음과 같은 효과를 낸다고 합니다:
"Preventing Feature Co-adaptation"
이는 특징 행렬들의 공동 적응을 막는다는 뜻인데, 이를 확률(~50%)에 따라서 일정 입력을 0으로 세팅함으로써 달성합니다(참고로 첫번째 입력 레이어에 대해서는 아에 dropout을 진행하지 않거나, ~15%의 확률로 dropout을 진행합니다. 이는 임베딩부터 dropout을 진행할 필요는 없기 때문일 것으로..?). 일부 입력을 0으로 세팅하면 일부 파라미터들의 출력 또한 0이 되고, 이에 대한 기울기 업데이트 또한 0이 될것입니다. 이는 출력이 살아있는 부분에 대한 파라미터 업데이트와 확률에 의해 출력이 죽은 부분에 대한 파라미터 업데이트를 분리합니다. 이를 특징 행렬들의 공동 적응을 막는다 표현한 것입니다.
머신 러닝 개념으로 이를 살펴본다면 bagging의 효과를 낸다고 볼 수도 있습니다. 하나의 큰 특징 행렬을 사용하는 것이 아닌, dropout을 통해 살아남은 행렬들끼리의 결합을 통해 일반화 성능을 끌어올렸기 때문입니다.
최근에는 feature-dependent regularizer(Wager, Wang & Liang 2013)을 사용하기도 합니다. 기존 dropout이 뉴런 단위로 출력을 0으로 만들어서 미니 배치들 사이에서도 0이 되는 차원이 달라지는 반면, 이는 특정 미니 배치에 대해 0으로 출력하는 차원이 정해집니다. 이를 통해 특정 차원에 대한 독립 학습이 더 강화되는 효과를 냅니다. *하지만 차원 자체를 통으로 삭제하기 때문에 정보 유실이 클 수 있습니다.
지금까지의 dropout은 훈련 단계에서 이루어지고, 테스트 단계에서는 dropout이 진행되지 않습니다.
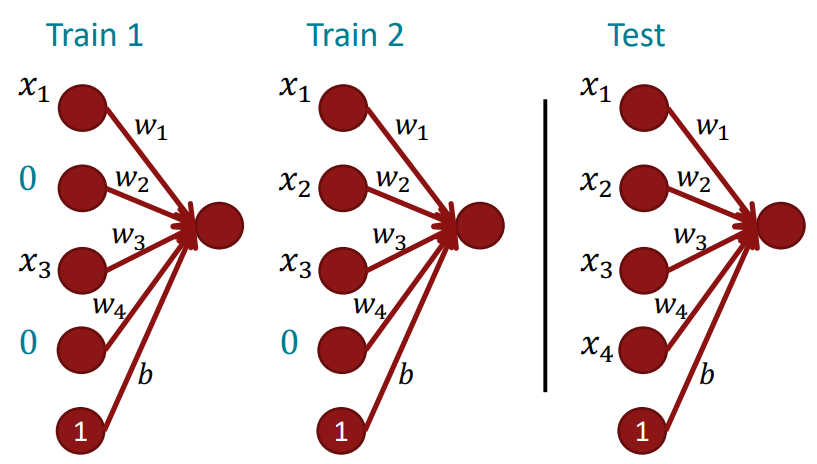
Parameter Initialzation
일반적으로 파라미터 행렬의 초기화는 매우 작은 랜덤한 값으로 이루어집니다. 이때 0행렬은 허용하지 않습니다. 이는 여러가지 문제를 일으킬 수 있습니다. (1) 우선 해당 특징 행렬을 통과하는 뉴런의 값이 똑같아집니다. (2) 따라서 서로 다른 특징들에 대한 학습이 이루어질 수 없습니다. 그렇기 때문에 대부분의 특징 행렬은 Uniform(-r,r)의 분포를 따라 초기화가 이루어집니다. 이때의 분산은 Xavier initialization을 통해 구할 수 있는데 다음과 같은 식을 갖습니다:
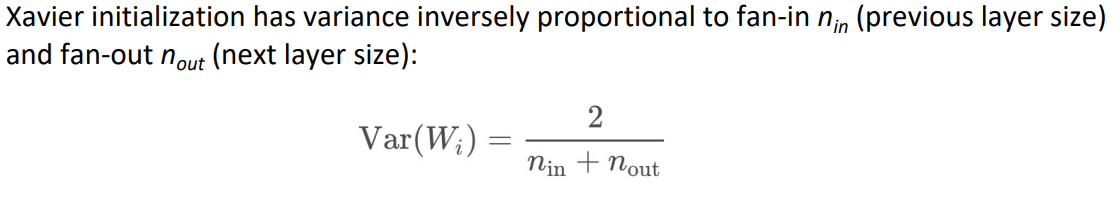
하지만 추후 배울 layer normalization을 제대로 수행하기만 한다면 특징 행렬 초기화는 그렇게 큰 영향을 주지 않습니다.
Opimizers
학습을 진행하는 optimizer로 지난번에 살펴보았던 SGD는 꽤 괜찮은 성능을 보입니다. 하지만 SGD를 통해 좋은 성능을 내기 위해서는 학습률이나 여러가지 튜닝들이 필요하기도 합니다(e.g., start it higher and halve it every k epochs (passes through full data, shuffled or sampled)). *데이터에 shuffle은 필수적입니다. 태스크와 상관없는 데이터 입력의 순서가 모델의 학습에 영향을 줄 수 있기 때문입니다.
이에 SGD를 대신하여 정말 많은 optimizer들이 생겼습니다. 이에 대해서는 아래의 글을 참고...
2025.01.08 - [[Deep daiv.]/[Deep daiv.] NLP] - [Deep daiv.] NLP - Optimizer 정리
[Deep daiv.] NLP - Optimizer 정리
Optimizer란? Optimizer는 머신러닝 혹은 딥러닝 모델이 주어진 목표 함수를 최소화(혹은 최대화)하도록 모델 파라미터(가중치, 편향 등)를 업데이트하는 절차나 알고리즘을 말합니다. 예를 들어 모
hw-hk.tistory.com
Learning Rates
학습률로 그냥 상수를 사용할 수도 있습니다. 이때 학습률은 너무 크다면 수렴할 수 없고, 너무 작으면 학습을 진행하는데 매우 오랜 시간이 걸리기 때문에 적절한 학습률을 선택하는 것이 중요합니다. 하지만 학습률을 크게 시작하여 점점 줄이는 것이 더 좋을 때가 많습니다. 손으로 학습률을 계산할 때는 하나의 epoch마다 학습률을 절반씩 줄이는 방법을, 아니면 cyclic learning rates와 같은 더 멋진 방법을 사용하기도 합니다.
Language Modeling
언어 모델(Language Model)은 어떤 단어가 들어왔을 때, 다음 단어로는 어떤 것이 나올지를 예측하는 모델을 말합니다:
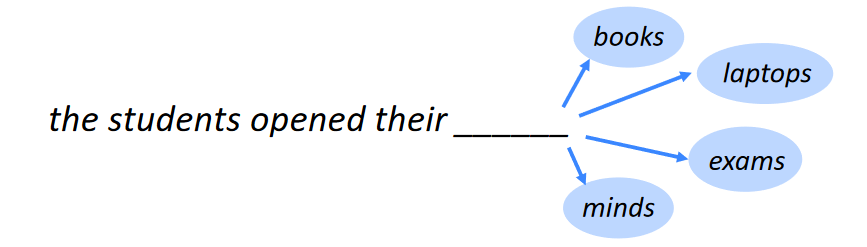
이를 좀 더 공식적으로 표현하면 다음과 같습니다:
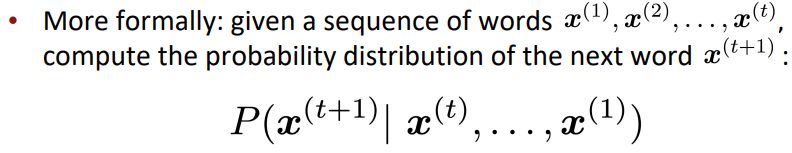
어떤 단어들이 순서대로 x1, x2, ..., xt일 때, 조건부 확률 P(xt+1 | xt, ..., x1)을 구하는 것입니다. 즉 이전의 단어들이 들어왔을 때, 다음 단어 xt+1이 나올 확률을 구하여 다음 단어를 예측하는 것입니다.
이때 조건부 확률의 and확률은 다음과 같은 방법으로 구할 수 있습니다:

You use Language Models every day!
이런 언어 모델은 여러 분야에서 다양하게 사용됩니다:
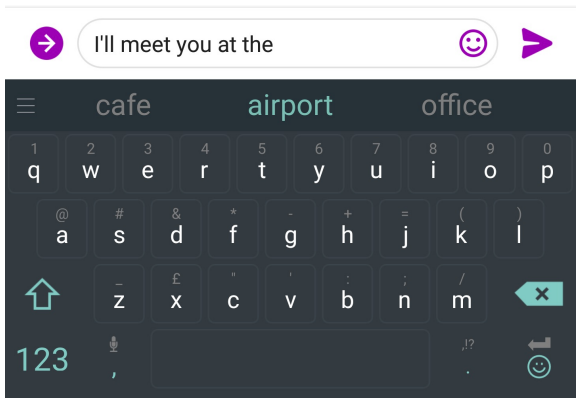
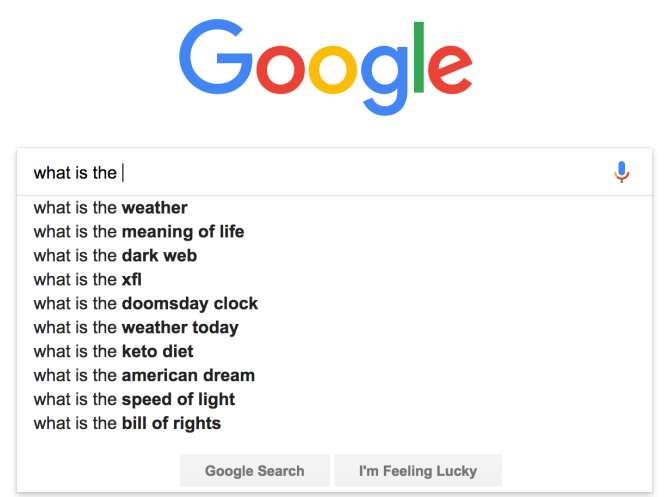
n-gram Language Models
신경망이 나오기 전 언어 모델은 n-gram언어 모델이었습니다:
Question: How to learn a Language Model?
Answer: (pre-Deep Learning): Learn an n-gram Language Model!
그렇다면 n-gram이 무엇일까요?
이는 연속하는 n개 단어의 묶음을 말합니다:

이에 대해서 각기 다른 n-gram들의 통계를 구하여 다음 단어를 예측하는 대에 사용할 수 있지 않을까 하는 아이디어를 통해 언어 모델을 구축했습니다.
n-gram을 통한 언어 모델 구축에는 Markov assumption이 있습니다.
2024.12.11 - [[학교 수업]/[학교 수업] 인공지능] - [인공지능] 마르코프 체인
[인공지능] 마르코프 체인
마르코프 체인 마르코프 성질을 가진 이산시간 확률과정마르코프 성질:과거와 현재 상태가 주어졌을 때의 미래 상태의조건부 확률 분포가 과거 상태와는 독립적으로 현재 상태에 의해서만 결
hw-hk.tistory.com
Markov가정은 x(t+1)라는 단어를 예측하는 데에는 선행하는 n-1개의 단어만이 영향을 준다는 것을 말합니다. 이를 통해 다음과 같은 확률값을 구할 수 있습니다:

n-gram Language Models: Example
만약 4-gram 언어 모델을 학습할 때의 예시를 살펴보겠습니다:

students opened their 이라는 연속된 단어들 다음의 단어를 예측하는 데에 students opened their을 포함하는 4-gram의 개수를 통해 확률을 사용합니다. students opened their가 1000번 나왔을 때, 그 다음 books가 400번, exams가 100번 등장했다면, books가 나올 확률을 400/1000으로, exams가 나올 확률을 100/1000으로 계산하는 것입니다. 이런 확률 계산을 통해서 다음 단어를 예측하는 것입니다.
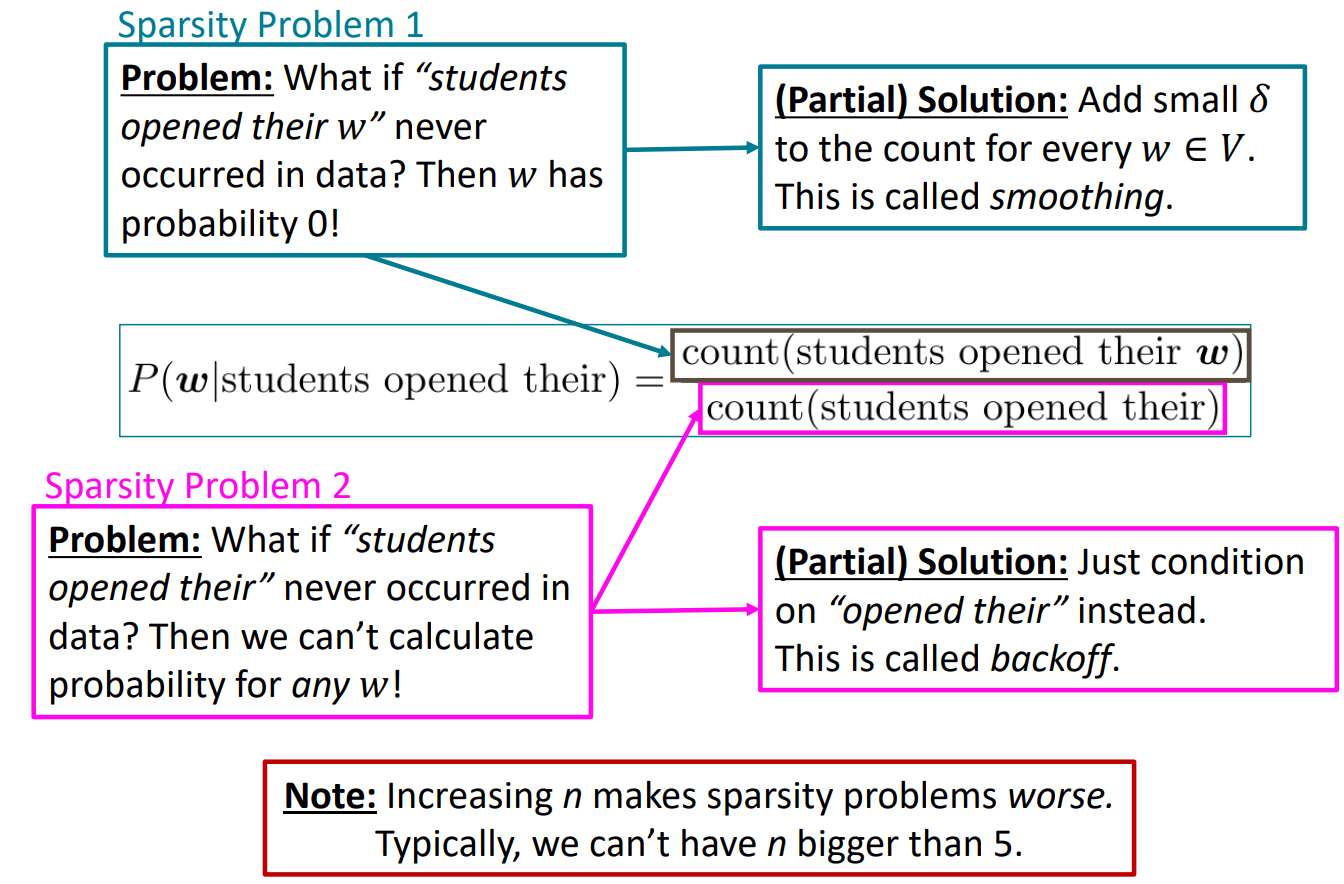
Sparsity Problems with n-gram Language Models
하지만 이런 n-gram 언어 모델에는 단점이 있습니다. 바로 sparsity problem입니다. 이는 발생하는 단어 조합의 개수가 절대적으로 부족한 경우 발생하는 문제입니다. 예를 들어 students opened their w라는 말 자제가 한 번도 발생하지 않았다면, w가 다음 단어로 나올 확률 자체가 0이 되버리는 문제가 발생합니다. 즉, 학습하는 데이터에 나오지 않았던 문장의 경우에는 예측할 수 없다는 문제가 생기는 것입니다.
그래서 이를 smoothing이라는 방법을 통해 해결합니다. 이는 매우 작은 수를 발생 횟수에 더해줌으로써 발생 횟수가 0이 되는 상황 자체를 만들지 않는 것입니다. 하지만 이래도 문제는 발생합니다. 바로 애초에 student opened their라는 말 자체가 한 번도 발생하지 않았다면 확률의 분모가 0이 되기 때문에 확률 자체를 계산할 수 없다는 문제가 발생합니다.
또 이는 n-gram의 n을 줄임으로써, 4-gram이었다면 tri-gram으로 줄임으로써 간접적으로 해결할 수 있습니다. 즉, n이 커질수록 sparsity problem이 발생할 확률이 증가합니다. 그래서 일반적으로 n은 5를 넘기지 않습니다.
Storage Problems with n-gram Language Models
저장 용량의 문제도 존재합니다. 예를 들어, n-gram에서 n의 수가 증가하면 증가할 수록 저장해야하는 부분 단어들의 개수가 증가하기 때문에 모델 사이즈 자체가 증가합니다. 그래서 일반적으로 이런 언어 모델들은 클라우드 아래에서 작동하는 경우가 대다수입니다.

Generating text with a n-gram Language Model
상위 5개의 단어들 중 랜덤하게 다음 단어를 생성하는 방식으로 텍스트를 생성하는 모습입니다:

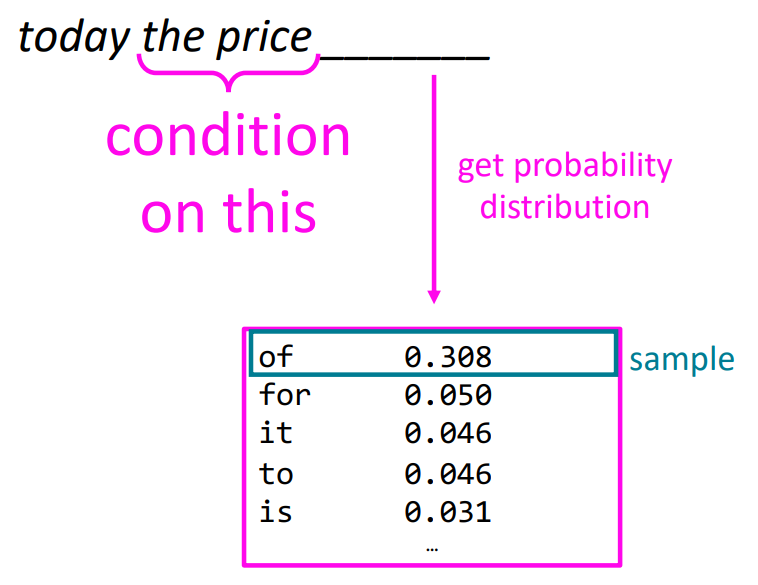


How to build a neural Language Model?
이를 두 번째 강의에서 살펴보았던 NER의 방식을 이용하면 신경망을 통해 언어 모델을 만들 수 있습니다:
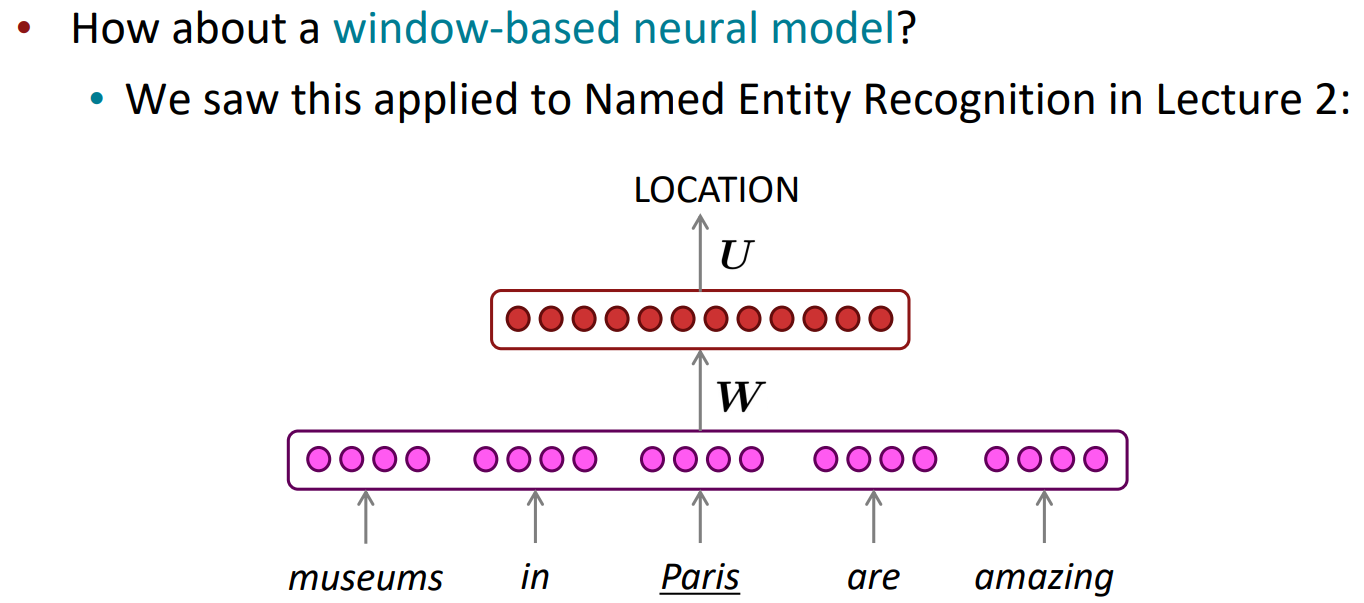
A fixed-window neural Language Model
NER과 마찬가지로, 고정된 window안에 있는 단어들을 통해 다음 단어를 예측하는 것으로, 아래 그림과 같은 방식으로 해결할 수 있습니다:
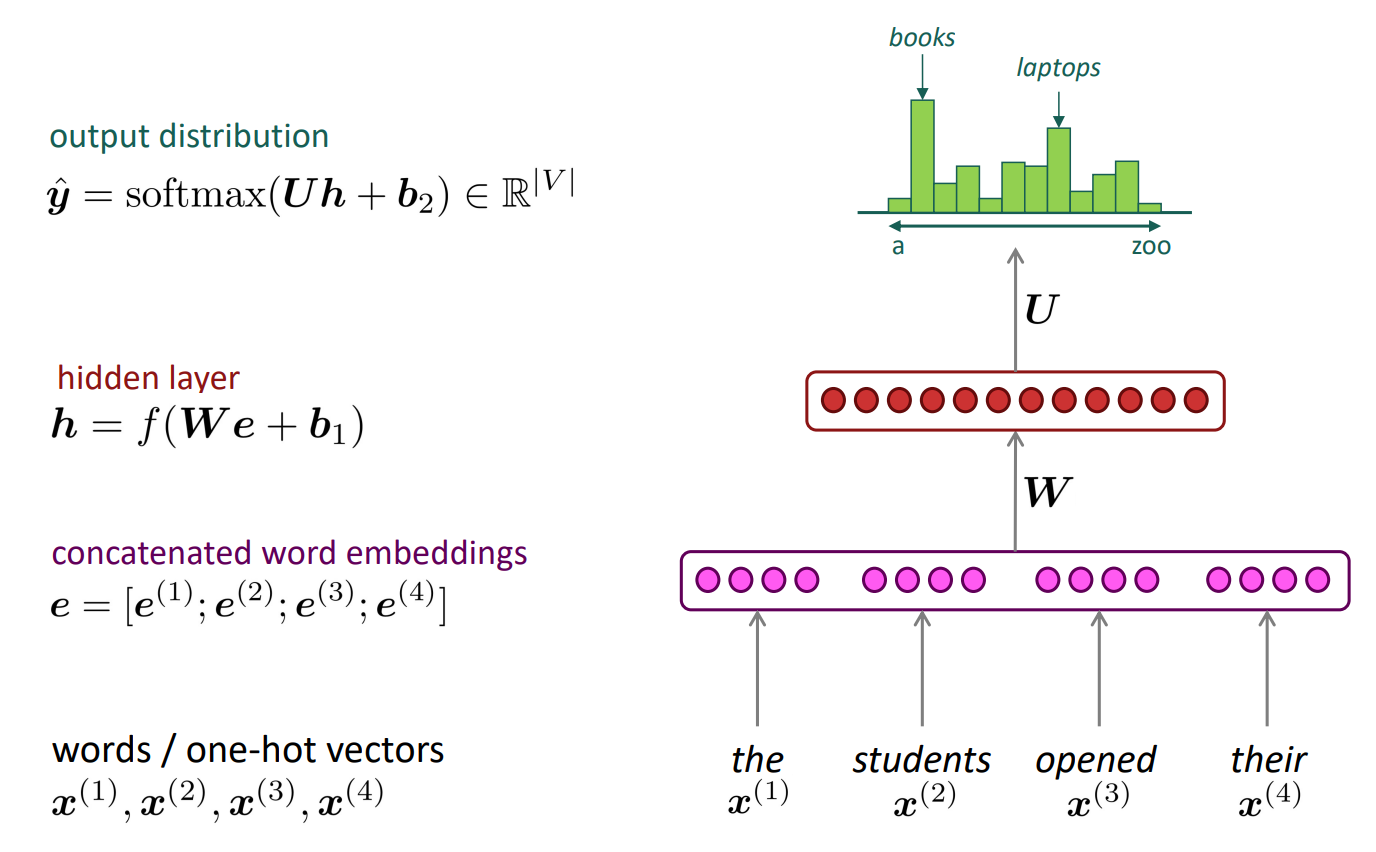
이런 방식은 기존의 n-gram 언어 모델에 비해 (1) Sparsity Promblem이 발생할 확률을 줄여주고, (2) n-gram의 정보들을 모두 저장하고 다닐 필요(Storage Promblem)가 없습니다.
하지만 여전히 남아있는 문제가 있습니다. (1) 고정된 window의 크기가 매우 작습니다. 언어적인 관점에서 다음 단어를 예측하는 데에는 맥락이 매우 중요합니다. 하지만 window의 크기가 4-5단어 정도의 크기라면 이런 맥락은 파악하기 힘들며 좋은 퀄리티의 단어를 예측하는 데에는 한계가 있을 수 있습니다. (2) 또한 여러개의 단어들이 내부 가중치행렬 W에 의해 동시에 계산된다는 문제도 있습니다. 즉, 어순을 반영할 수 없다는 것입니다. 영어의 경우 "the" 다음에는 명사가 나오는 등 어순에 따라 나올 수 있는 단어들이 있습니다. 이를 반영할 수 없다는 문제가 있다는 것입니다.
Recurrent Neural Networks (RNN)
하지만 RNN은 이런 문제를 해결했습니다. 고정된 window를 사용하지 않기 때문에 아무리 문장이 길어도 모두 사용할 수 있었으며, 차례로 가중치행렬을 곱해줌으로써 어순을 반영할 수 있었습니다:
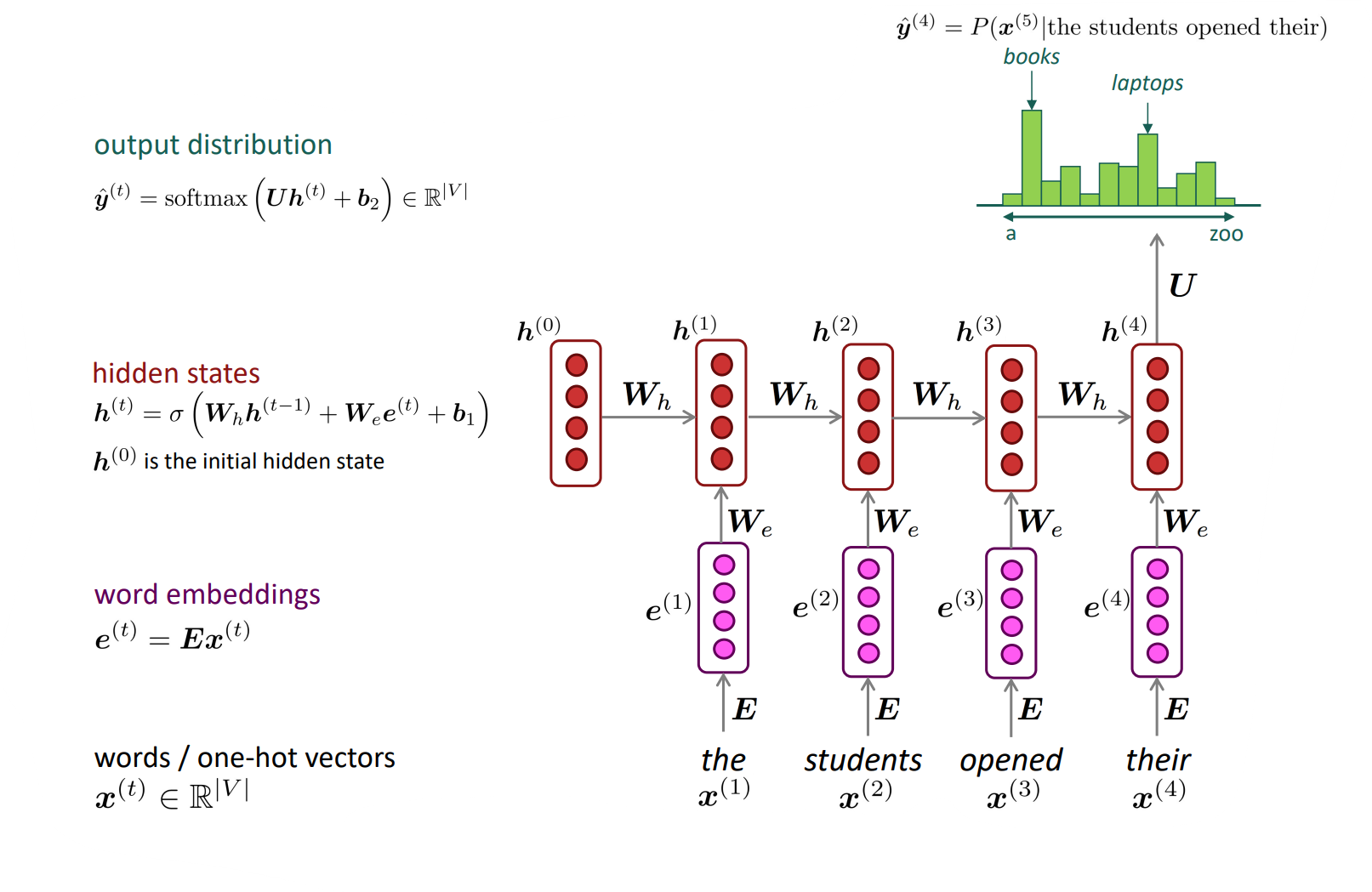
하지만 여전히 문제점은 남아있었습니다. (1) 기존에는 각 단어들을 한 번에 가중치 행렬에 곱해줌으로써 계산을 한 번에 수행할 수 있었지만, RNN은 한 단어씩 계산을 하기 때문에 계산 시간이 늘어나는 문제가 있었습니다. (2) 또한 window의 크기가 매우 길어질 수 있지만, 정보가 뒤로 갈수록 손실되는 문제가 있어서 사실상 늘릴 수 있는 window의 크기에 한계가 있었습니다.
'[CS224N]' 카테고리의 다른 글
A bit more about Neural Networks
We have models with many parameters! Regularization!
규제 혹은 정규화는 매우 중요합니다. L2 정규화가 그 예시입니다:
전통적인 관점에서 정규화는 모델의 과적합(overfitting)을 막는데 매우 중요한 역할을 합니다. 이때 과적합이란 Training set에 너무 과하게 적합하여 실제 데이터 분포에 대해서는 성능이 좋지 못한 것을 말합니다:
이렇게 과적합이 심한 모델의 경우, 실제 데이터 분포에 대해서는 정확하게 예측할 수 없기 때문에 적절한 수준에서 학습을 끝내줌으로써 과적합을 막는 것이 매우 중요합니다. 하지만 위에서 설명한 L2 정규화는 신경망에는 적용하기 힘듭니다. 신경망의 경우는 파라미터의 수가 너무 많고, 하나하나의 파라미터가 어떤 것을 의미하는지 모르기 때문에, 파라미터의 절댓값을 줄인다하여 과적합을 막는것을 보장하기 힘들기 때문입니다.
2024.03.30 - [[Deep daiv.]/머신러닝] - 머신러닝 공부 4.1 - 규제 Regularization
머신러닝 공부 4.1 - 규제 Regularization
0. 오버피팅 문제 모델을 한정된 데이터로 학습시키다 보면 모델이 학습 데이터셋에 대한 손실함수가 과하게 작아지는 경우가 생길 수 있습니다. 이런 경우 우리는 모델이 과적합되었다고 합니
hw-hk.tistory.com
그렇기 때문에 최근에는 파라미터의 절댓값을 줄이는 방향으로 정규화를 진행하지 않고, 일반화를 잘 할 수 있는 방향으로 정규화를 진행합니다. 그렇다면 일반화를 잘 하는 방법으로 무엇이 있을까요?
Dropout (Srivastava, Hinton, Krizhevsky, Sutskever, & Salakhutdinov 2012/JMLR 2014)
원어 그대로 표현하면 Dropout은 다음과 같은 효과를 낸다고 합니다:
"Preventing Feature Co-adaptation"
이는 특징 행렬들의 공동 적응을 막는다는 뜻인데, 이를 확률(~50%)에 따라서 일정 입력을 0으로 세팅함으로써 달성합니다(참고로 첫번째 입력 레이어에 대해서는 아에 dropout을 진행하지 않거나, ~15%의 확률로 dropout을 진행합니다. 이는 임베딩부터 dropout을 진행할 필요는 없기 때문일 것으로..?). 일부 입력을 0으로 세팅하면 일부 파라미터들의 출력 또한 0이 되고, 이에 대한 기울기 업데이트 또한 0이 될것입니다. 이는 출력이 살아있는 부분에 대한 파라미터 업데이트와 확률에 의해 출력이 죽은 부분에 대한 파라미터 업데이트를 분리합니다. 이를 특징 행렬들의 공동 적응을 막는다 표현한 것입니다.
머신 러닝 개념으로 이를 살펴본다면 bagging의 효과를 낸다고 볼 수도 있습니다. 하나의 큰 특징 행렬을 사용하는 것이 아닌, dropout을 통해 살아남은 행렬들끼리의 결합을 통해 일반화 성능을 끌어올렸기 때문입니다.
최근에는 feature-dependent regularizer(Wager, Wang & Liang 2013)을 사용하기도 합니다. 기존 dropout이 뉴런 단위로 출력을 0으로 만들어서 미니 배치들 사이에서도 0이 되는 차원이 달라지는 반면, 이는 특정 미니 배치에 대해 0으로 출력하는 차원이 정해집니다. 이를 통해 특정 차원에 대한 독립 학습이 더 강화되는 효과를 냅니다. *하지만 차원 자체를 통으로 삭제하기 때문에 정보 유실이 클 수 있습니다.
지금까지의 dropout은 훈련 단계에서 이루어지고, 테스트 단계에서는 dropout이 진행되지 않습니다.
Parameter Initialzation
일반적으로 파라미터 행렬의 초기화는 매우 작은 랜덤한 값으로 이루어집니다. 이때 0행렬은 허용하지 않습니다. 이는 여러가지 문제를 일으킬 수 있습니다. (1) 우선 해당 특징 행렬을 통과하는 뉴런의 값이 똑같아집니다. (2) 따라서 서로 다른 특징들에 대한 학습이 이루어질 수 없습니다. 그렇기 때문에 대부분의 특징 행렬은 Uniform(-r,r)의 분포를 따라 초기화가 이루어집니다. 이때의 분산은 Xavier initialization을 통해 구할 수 있는데 다음과 같은 식을 갖습니다:
하지만 추후 배울 layer normalization을 제대로 수행하기만 한다면 특징 행렬 초기화는 그렇게 큰 영향을 주지 않습니다.
Opimizers
학습을 진행하는 optimizer로 지난번에 살펴보았던 SGD는 꽤 괜찮은 성능을 보입니다. 하지만 SGD를 통해 좋은 성능을 내기 위해서는 학습률이나 여러가지 튜닝들이 필요하기도 합니다(e.g., start it higher and halve it every k epochs (passes through full data, shuffled or sampled)). *데이터에 shuffle은 필수적입니다. 태스크와 상관없는 데이터 입력의 순서가 모델의 학습에 영향을 줄 수 있기 때문입니다.
이에 SGD를 대신하여 정말 많은 optimizer들이 생겼습니다. 이에 대해서는 아래의 글을 참고...
2025.01.08 - [[Deep daiv.]/[Deep daiv.] NLP] - [Deep daiv.] NLP - Optimizer 정리
[Deep daiv.] NLP - Optimizer 정리
Optimizer란? Optimizer는 머신러닝 혹은 딥러닝 모델이 주어진 목표 함수를 최소화(혹은 최대화)하도록 모델 파라미터(가중치, 편향 등)를 업데이트하는 절차나 알고리즘을 말합니다. 예를 들어 모
hw-hk.tistory.com
Learning Rates
학습률로 그냥 상수를 사용할 수도 있습니다. 이때 학습률은 너무 크다면 수렴할 수 없고, 너무 작으면 학습을 진행하는데 매우 오랜 시간이 걸리기 때문에 적절한 학습률을 선택하는 것이 중요합니다. 하지만 학습률을 크게 시작하여 점점 줄이는 것이 더 좋을 때가 많습니다. 손으로 학습률을 계산할 때는 하나의 epoch마다 학습률을 절반씩 줄이는 방법을, 아니면 cyclic learning rates와 같은 더 멋진 방법을 사용하기도 합니다.
Language Modeling
언어 모델(Language Model)은 어떤 단어가 들어왔을 때, 다음 단어로는 어떤 것이 나올지를 예측하는 모델을 말합니다:
이를 좀 더 공식적으로 표현하면 다음과 같습니다:
어떤 단어들이 순서대로 x1, x2, ..., xt일 때, 조건부 확률 P(xt+1 | xt, ..., x1)을 구하는 것입니다. 즉 이전의 단어들이 들어왔을 때, 다음 단어 xt+1이 나올 확률을 구하여 다음 단어를 예측하는 것입니다.
이때 조건부 확률의 and확률은 다음과 같은 방법으로 구할 수 있습니다:
You use Language Models every day!
이런 언어 모델은 여러 분야에서 다양하게 사용됩니다:
n-gram Language Models
신경망이 나오기 전 언어 모델은 n-gram언어 모델이었습니다:
Question: How to learn a Language Model?
Answer: (pre-Deep Learning): Learn an n-gram Language Model!
그렇다면 n-gram이 무엇일까요?
이는 연속하는 n개 단어의 묶음을 말합니다:
이에 대해서 각기 다른 n-gram들의 통계를 구하여 다음 단어를 예측하는 대에 사용할 수 있지 않을까 하는 아이디어를 통해 언어 모델을 구축했습니다.
n-gram을 통한 언어 모델 구축에는 Markov assumption이 있습니다.
2024.12.11 - [[학교 수업]/[학교 수업] 인공지능] - [인공지능] 마르코프 체인
[인공지능] 마르코프 체인
마르코프 체인 마르코프 성질을 가진 이산시간 확률과정마르코프 성질:과거와 현재 상태가 주어졌을 때의 미래 상태의조건부 확률 분포가 과거 상태와는 독립적으로 현재 상태에 의해서만 결
hw-hk.tistory.com
Markov가정은 x(t+1)라는 단어를 예측하는 데에는 선행하는 n-1개의 단어만이 영향을 준다는 것을 말합니다. 이를 통해 다음과 같은 확률값을 구할 수 있습니다:
n-gram Language Models: Example
만약 4-gram 언어 모델을 학습할 때의 예시를 살펴보겠습니다:
students opened their 이라는 연속된 단어들 다음의 단어를 예측하는 데에 students opened their을 포함하는 4-gram의 개수를 통해 확률을 사용합니다. students opened their가 1000번 나왔을 때, 그 다음 books가 400번, exams가 100번 등장했다면, books가 나올 확률을 400/1000으로, exams가 나올 확률을 100/1000으로 계산하는 것입니다. 이런 확률 계산을 통해서 다음 단어를 예측하는 것입니다.
Sparsity Problems with n-gram Language Models
하지만 이런 n-gram 언어 모델에는 단점이 있습니다. 바로 sparsity problem입니다. 이는 발생하는 단어 조합의 개수가 절대적으로 부족한 경우 발생하는 문제입니다. 예를 들어 students opened their w라는 말 자제가 한 번도 발생하지 않았다면, w가 다음 단어로 나올 확률 자체가 0이 되버리는 문제가 발생합니다. 즉, 학습하는 데이터에 나오지 않았던 문장의 경우에는 예측할 수 없다는 문제가 생기는 것입니다.
그래서 이를 smoothing이라는 방법을 통해 해결합니다. 이는 매우 작은 수를 발생 횟수에 더해줌으로써 발생 횟수가 0이 되는 상황 자체를 만들지 않는 것입니다. 하지만 이래도 문제는 발생합니다. 바로 애초에 student opened their라는 말 자체가 한 번도 발생하지 않았다면 확률의 분모가 0이 되기 때문에 확률 자체를 계산할 수 없다는 문제가 발생합니다.
또 이는 n-gram의 n을 줄임으로써, 4-gram이었다면 tri-gram으로 줄임으로써 간접적으로 해결할 수 있습니다. 즉, n이 커질수록 sparsity problem이 발생할 확률이 증가합니다. 그래서 일반적으로 n은 5를 넘기지 않습니다.
Storage Problems with n-gram Language Models
저장 용량의 문제도 존재합니다. 예를 들어, n-gram에서 n의 수가 증가하면 증가할 수록 저장해야하는 부분 단어들의 개수가 증가하기 때문에 모델 사이즈 자체가 증가합니다. 그래서 일반적으로 이런 언어 모델들은 클라우드 아래에서 작동하는 경우가 대다수입니다.
Generating text with a n-gram Language Model
상위 5개의 단어들 중 랜덤하게 다음 단어를 생성하는 방식으로 텍스트를 생성하는 모습입니다:
How to build a neural Language Model?
이를 두 번째 강의에서 살펴보았던 NER의 방식을 이용하면 신경망을 통해 언어 모델을 만들 수 있습니다:
A fixed-window neural Language Model
NER과 마찬가지로, 고정된 window안에 있는 단어들을 통해 다음 단어를 예측하는 것으로, 아래 그림과 같은 방식으로 해결할 수 있습니다:
이런 방식은 기존의 n-gram 언어 모델에 비해 (1) Sparsity Promblem이 발생할 확률을 줄여주고, (2) n-gram의 정보들을 모두 저장하고 다닐 필요(Storage Promblem)가 없습니다.
하지만 여전히 남아있는 문제가 있습니다. (1) 고정된 window의 크기가 매우 작습니다. 언어적인 관점에서 다음 단어를 예측하는 데에는 맥락이 매우 중요합니다. 하지만 window의 크기가 4-5단어 정도의 크기라면 이런 맥락은 파악하기 힘들며 좋은 퀄리티의 단어를 예측하는 데에는 한계가 있을 수 있습니다. (2) 또한 여러개의 단어들이 내부 가중치행렬 W에 의해 동시에 계산된다는 문제도 있습니다. 즉, 어순을 반영할 수 없다는 것입니다. 영어의 경우 "the" 다음에는 명사가 나오는 등 어순에 따라 나올 수 있는 단어들이 있습니다. 이를 반영할 수 없다는 문제가 있다는 것입니다.
Recurrent Neural Networks (RNN)
하지만 RNN은 이런 문제를 해결했습니다. 고정된 window를 사용하지 않기 때문에 아무리 문장이 길어도 모두 사용할 수 있었으며, 차례로 가중치행렬을 곱해줌으로써 어순을 반영할 수 있었습니다:
하지만 여전히 문제점은 남아있었습니다. (1) 기존에는 각 단어들을 한 번에 가중치 행렬에 곱해줌으로써 계산을 한 번에 수행할 수 있었지만, RNN은 한 단어씩 계산을 하기 때문에 계산 시간이 늘어나는 문제가 있었습니다. (2) 또한 window의 크기가 매우 길어질 수 있지만, 정보가 뒤로 갈수록 손실되는 문제가 있어서 사실상 늘릴 수 있는 window의 크기에 한계가 있었습니다.