
The skip-gram model with negative sampling
이전 강의에서 사용한 Skip-gram의 확률식을 살펴보면,
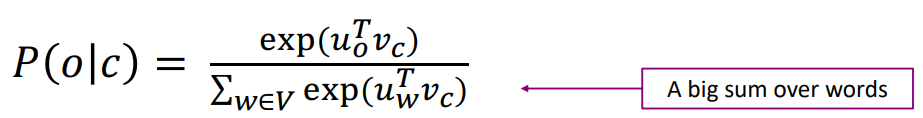
분모의 정규화식을 계산하는 데 모든 단어에 대해 exp의 합을 구하는 것을 알 수 있습니다. 만약 vocab의 크기가 50만이라면 해당 계산을 50만번 해야한다는 의미입니다. 이는 너무 계산비용이 비싸기 때문에 negative sampling이라는 기법을 통해 해당 문제를 해결하고자 합니다.
negative sampling의 핵심 아이디어는 실제 window안에 들어있는 중심 단어와 맥락 단어 쌍을 맞추고, 랜덤한 단어와 중심 단어 쌍의 틀리게 하는 방향으로 로지스틱 회귀를 진행하는 것입니다. 이때 랜덤한 단어는 10~15개의 단어로 기존 방식(=vocab size)에 비해 샘플링하는 단어의 수가 줄어 계산 비용을 줄일 수 있습니다.
09-04 네거티브 샘플링을 이용한 Word2Vec 구현(Skip-Gram with Negative Sampling, SGNS)
네거티브 샘플링(Negative Sampling)을 사용하는 Word2Vec을 직접 케라스(Keras)를 통해 구현해봅시다. ## 1. 네거티브 샘플링(Negative Samp…
wikidocs.net
이를 적용했을 때, 다음과 같은 목적함수를 갖습니다:
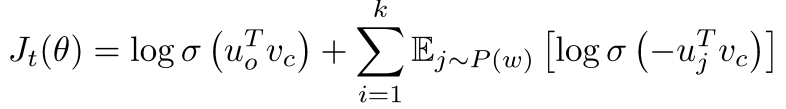
이때 σ()는 로지스틱/시그모이드 함수입니다. 해당 목적함수를 통해 중심 단어와 동시에 발생하는(실제 window안에 들어있는) 주변 단어의 확률을 높이고, 잡음(랜덤)한 단어와의 확률을 낮추는 방향으로 모델을 학습시킬 수 있습니다. 이를 비용함수로 바꿔보면 다음과 같습니다:
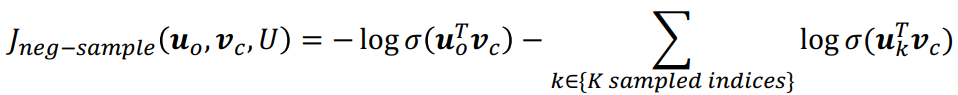
참고로 샘플링하는 단어는 유니그램 단어 분포를 따르며, 유니그램 분포의 3/4제곱을 한 분포를 따릅니다. 이를 통해 빈도가 작은 단어를 더 자주 샘플링할 수 있게, 빈도가 큰 단어를 덜 샘플링 할 수 있게 분포를 평탄화 할 수 있습니다.
(1) Q: 만약 샘플링한 k개의 단어들 중 일부가 실제 window안에 들어있는 단어여서 해당 단어가 negative sample이 아닌 경우, 해당 목적 함수가 틀릴 수 있지 않나?
A: k개의 단어가 실제 window안에 들어있는 단어일 확률은 0.01%이하입니다. 또한 그렇게 발생하는 오류를 막는 것보다 k개만 샘플링해서 정확한 단어 벡터를 얻는 것이 더 중요할 수 있습니다.
Stochastic gradients with negative sampling[aside]
negative sampling을 통해 SGD를 반복적으로 수행한다면, 각각의 window에 해당하는 단어들에 대해서만 경사를 구할 수 있을 것입니다(window안에 들어있는 단어들에 대해서만 비용함수에 따라 경사를 계산할 수 있기 때문에). 그렇다면 얻게 되는 경사 벡터는 매우 희소한 벡터(sparse vector)일 것입니다. 따라서 해당 경사를 효율적으로 계산하려면 특정 단어에 대해서만 경사 행렬을 만들어야합니다.
Why not capture co-occurrence counts directly?
그런데 왜 전체 말뭉치에 대해서 통계 데이터를 얻지 않는것일까요?
동시 등장 행렬을 만드는 방법에는 두 가지 방법이 있습니다:
- window를 활용하는 방법: 해당 방법은 word2vec과 유사합니다. 이는 단어들을 구문적, 의미론적으로 파악할 수 있습니다("word space").
- full document에 대해서 사용하는 방법: 문서-단어 동시발생 행렬은 LSA(Latent Semantic Analysis, 잠재 의미 분석)과 같은 일반적인 주제에 대해 도움이 됩니다("document space")
Example: Window based co-occurrence matrix
window기반의 동시 등장 행렬의 예시를 보겠습니다:
- window size: 1 (more common: 5~10)
- example corpus
- I like deep learning
- I like NLP
- I enjoy flying
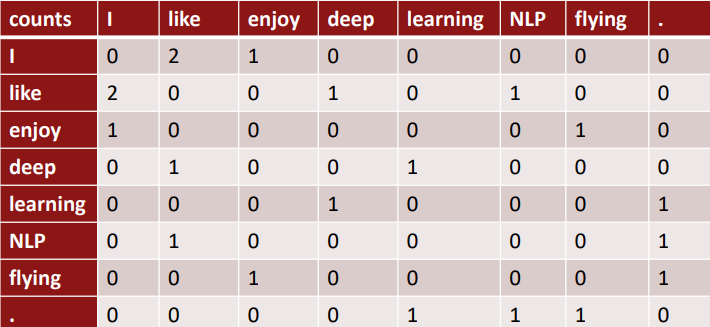
해당 동시 등장 행렬은 symmetric합니다. 그렇기 때문에 하나 하나의 열이나 행을 단어 벡터로 사용할 수 있습니다.
Co-occurrence vectors
그저 단순하게 count기반의 동시등장 행렬의 경우 (1) 벡터의 크기가 vocab size에 비례해서 커질 수 있습니다. (2) 이는 단어 벡터가 매우 큰 차원의 벡터가 될 수 있음을, 저장하는 데에 매우 많은 공간이 필요함을 의미합니다. (3) 또한 대부분의 단어 벡터가 sparse하기 때문에 해당 단어 벡터를 사용하는 모델의 성능을 보장할 수 없습니다.
하지만 저차원의 단어 벡터를 사용하는 것은 다릅니다. 중요한 정보들은 고정한 채, 차원의 크기만 줄인 해당 방법으로, word2vec을 예로 들 수 있습니다. 일반적으로 25~1000 차원을 사용합니다. 그렇다면 어떻게 차원을 축소할까요?
Classic Method: Dimensionality Reduction on X
동시 등장 행렬 X에 대해 특이값 분해(SVD, Singular Value Decomposition)를 수행할 수 있습니다.
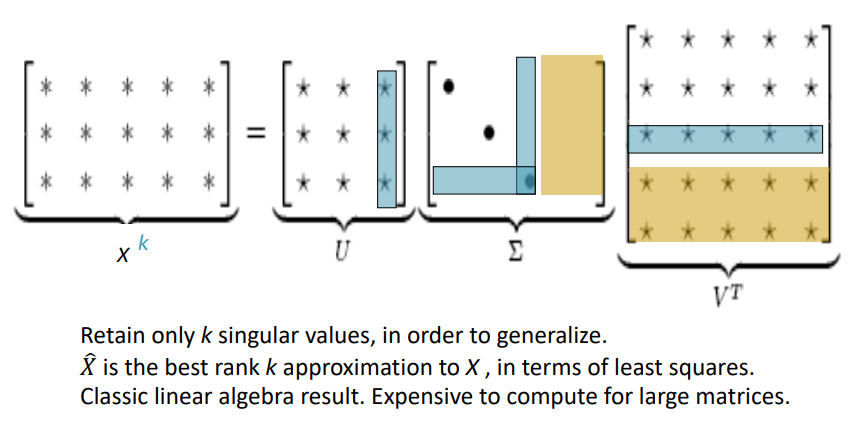
중간의 Σ행렬의 크기를 조절함으로써, 단어 벡터의 차원을 줄일 수 있고, 특이값의 크기를 통해 적절한 차원을 구할 수도 있습니다.
Hacks to X (several used in Rohde et al. 2005 in COALS)
하지만 그냥 개수 기반의 동시 등장 행렬에 SVD를 적용하는 것은 효과적이지 못합니다. 'the', 'he', 'has'와 같은 기능어들이 너무 자주 등장하기 때문에 의미론적으로 비교적 덜 등장하는 단어들에 대해 의미론적으로 분석하기가 힘들기 때문입니다. 또한 다양한 문제가 있을 수 있는데, 이를 해결하기 위한 방법은 다음과 같습니다:
- log the frequencies: 빈도에 log를 취함으로써, 빈도가 큰 단어들에 대해 패널티를 줍니다.
- min(X, t), with t ≒ 100: 특정 빈도수 이상의 단어들에 대해 패널치를 줍니다.
- Ignore the function words: 전처리를 통해 기능어들을 아에 빼줍니다.
- Ramped windows: 멀리 있는 단어보다 가까이 있는 단어의 중요도를 높여주는 특수한 window를 통해 동시 등장 행렬을 만들어줍니다.
- Using Person correlation: 개수(count) 대신 상관 계수를 사용합니다.
Interesting semantic patterns emerge in the scaled vectors
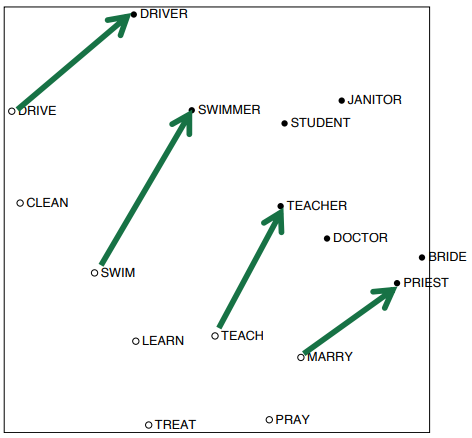
이를 통해 구해진 단어 벡터를 보면 재미있는 특징을 발견할 수 있습니다. 단어끼리의 관계가 벡터 공간에 투영된 것입니다. 예를 들어 위 그림은 어떤 동작과 해당 동작을 수행하는 사람과의 관계를 보여줍니다. 해당 관계를 나타내는 벡터들은 크기와 방향을 대략 유사함을 확인할 수 있습니다.
GloVe: Encoding meaning components in vector differences
앞서 단어 벡터를 만드는 방법으로 두 가지 방법을 살펴봤습니다:
- window를 활용하는 방법
- 장점: 예측 기반으로 단어 간 유추 작업이나, 유사성을 분석하는 데에 유리합니다.
- 단점: 임베딩 벡터가 window 크기 내에서만 주변 단어를 고려하기 때문에 말뭉치(corpus)의 전체적인 통계 정보를 반영하지는 못합니다.
- count기반 동시 등장 행렬
- 장점: 말뭉치의 전체적인 통계 정보를 활용할 수 있고, 계산 속도가 빠릅니다.
- 단점: 왕:남자 = 여왕:? 과 같은 단어 의미의 유추 작업에는 성능이 떨어집니다.
GloVe의 목표는 바로 "임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 말뭉치에서의 동시 등장 확률이 되도록" 만드는 것입니다. 다시 말해, 확률 기반 동시 등장 행렬을 통해 얻은 것을 벡터 공간에 투영하는 것입니다. 이를 통해 두 가지 방법의 장점을 모두 잡고자합니다(Q: How can we capture ratios of co-occurence probabilities as linear meaning components in a word vector space?).
이는 다음과 같은 손실 함수를 갖는 모델을 통해 이루어집니다:
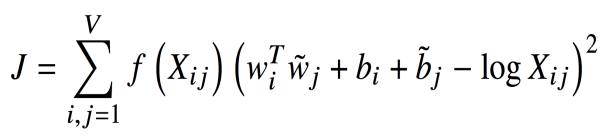
이는 단어 벡터 i와 j의 내적과 동시 등장 행렬에서의 단어 i와 j의 값, Xij가 같아지도록 합니다. 앞에 붙은 f()는 가중치항으로, 동시 등장 출현 빈도가 높은 단어 쌍에는 낮은 가중치(Loss값이 증가)를 부여하고, 빈도가 낮은 단어 쌍에는 높은 가중치를 부여해서 출연 빈도가 높은 단어 쌍에 대해서 더 정교하게 임베딩을 합니다. 이때의 f()함수는 다음과 같습니다:
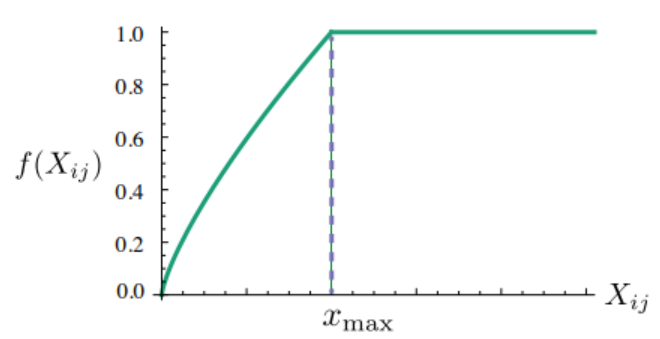
하지만 높은 빈도수를 가졌다고 지나치게 가중치가 높아서는 안됩니다. 따라서 일정 빈도(Xmax)이상이라면 최대값으로 가중치항이 고정됩니다.
결과적으로 이는 두 가지 방법의 장점을 모두 갖습니다. (1) 빠른 훈련속도를 달성하고, (2) 큰 말뭉치에 대해서도 통계적인 임베딩 모델을 구축할 수 있습니다.
09-05) 글로브(GloVe)
글로브(Global Vectors for Word Representation, GloVe)는 카운트 기반과 예측 기반을 모두 사용하는 방법론으로 2014년에 미국 스탠포드대학에서…
wikidocs.net
How to evaluate word vectors?
NLP에서의 평가 방법은 두 가지가 있습니다:
- Intrinsic:
- 특정 subtask에서나 중간 단계에서 평가를 진행하는 방법
- 시스템을 이해하는데 도움을 주고, 평가 계산이 빠릅니다.
- 하지만, 해당 평가가 실제 task에 좋은 영향을 줄 지는 모릅니다.
- Extrinsic:
- 실제 task에 대해서 평가합니다.
- 하지만, 결과가 아래의 subsystem이 문제인지, 아니면 subsystem끼리의 연결이 문제인지를 알 수 없습니다.
Intrinsic word vector evaluation
다양한 방법이 존재합니다. 앞서 말했던 Word Vector Analogies(단어 유추)가 Intrinsic한 평가에 해당합니다.

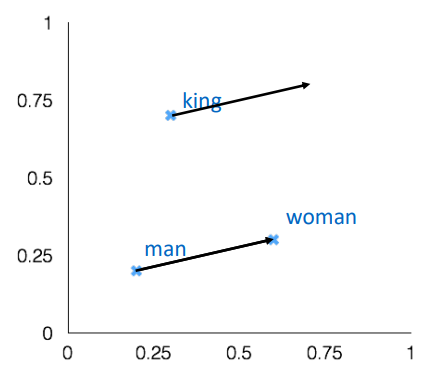
어떤 단어 벡터에 대해 특정 의미론적, 구문론적 유추 질문에 대한 벡터를 더하면 얼마나 잘 정답 단어 벡터를 예상할 수 있는지를 평가합니다. 하지만, 벡터 관계를 더하여 구할 수 있는 관계에 대해서만 평가를 할 수 있다는 단점이 있습니다. 즉, 어떤 관계가 선형으로 결합되는 관계가 아니라면 이를 평가할 수 없습니다.
GloVe Visualization
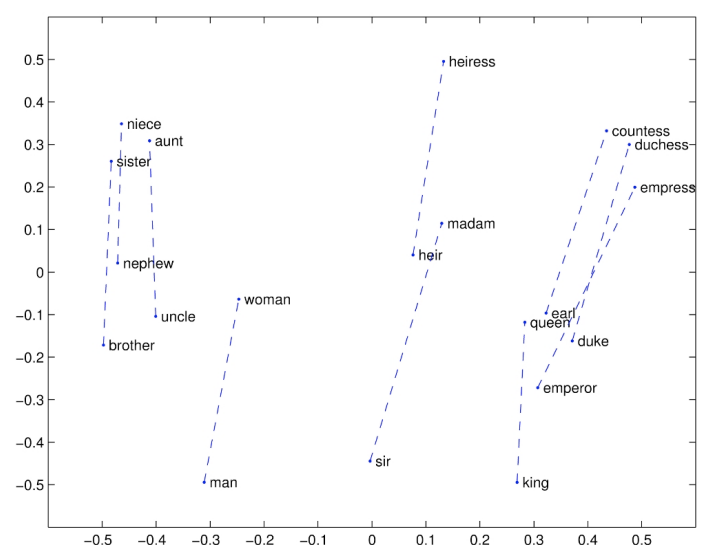
GloVe또한 잘 벡터 공간에서 단어들끼리의 관계가 선형으로 유지됨을 확인할 수 있습니다.
Meaning similarity: Another intrinsic word vecotr evaluation
어떤 단어 쌍에 대한 사람의 판단과 단어 벡터끼리의 유사도와 거리를 비교하여 평가할 수 있습니다. 예시 데이터 셋으로는 WordSim353이 있습니다(http://www.cs.technion.ac.il/~gabr/resources/data/wordsim353/).
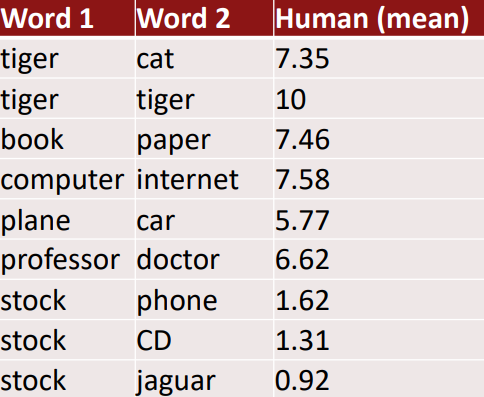
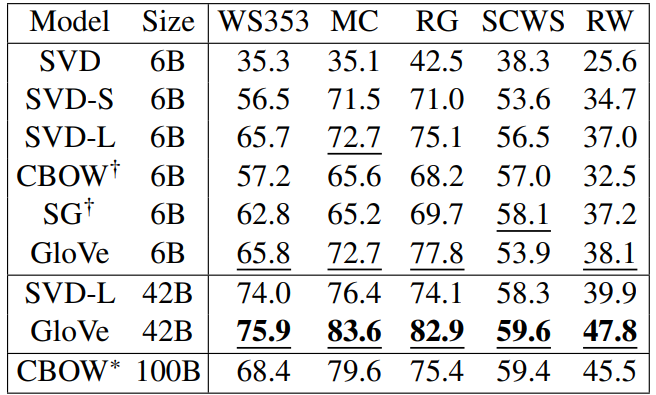
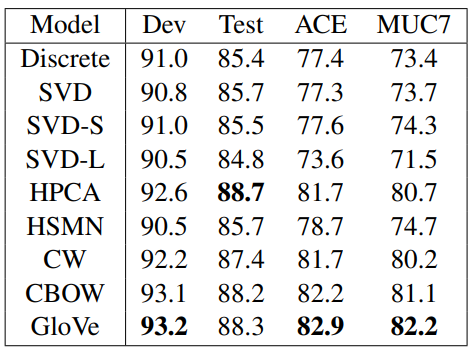
WordSim353 평가 결과 GloVe가 다른 방법들에 비해(SG(Skip-gram), SVD) 좋은 Intrinsic평가 결과를 갖습니다. 참고로 Chris Manning은 좋은 결과가 양질의 데이터 확보 유무 때문이라고 평가합니다(GloVe를 학습하는데 사용한 데이터는 당시 최신 데이터였음).
Extrinsic word vector evaluation
Extrinsic평가의 좋은 예로는 NER(named entity recognition, 개채명인식) task가 있습니다. 이를 통해 임베딩 모델의 성능을 유추할 수 있습니다.
Word senses and word sense ambiguity
하지만 지금까지 간과하고 있었던 사실이 있습니다. 사실 대부분의 단어들은 많은 뜻을 갖습니다. 이를 하나의 벡터로 임베딩하는 것은 과연 옳을까요?
예를 들어 "pike"라는 단어는 정말 많은 뜻을 갖습니다:
- A sharp point or staff
- A type of elongated fish
- A railroad line or system
- A type of road
- The future (coming down the pike)
- To kill or pierce with a pike
- To make one's way (pike along)
- In Australian English, pike means to pull out from doing something: I reckon he could have climbed that cliff, but he piked!
Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012)
해당 문제를 해결하기 위한 방법으로 단어들을 미리 클러스터링 해서 임베딩을 하는 방법이 있습니다. 아래의 그림은 그 결과 임베딩된 벡터들을 시각화한 결과입니다:

jaguar의 경우 왼쪽 위에 있는 luxury, convertible이라는 단어와 함께 있는 것으로 보아 자동차 브랜드 jaguar를 의미하고, 중간에 keyboard와 같이 있는 jaguar의 경우는 키보드 브랜드 jaguar를 의미하며, 오른쪽 아래의 jaguar는 hunter와 같이 있는것으로 보아 동물 jaguar를 의미합니다. 이렇게 미리 클러스터링하여 임베딩을 하면, 다양한 의미를 갖는 단어들을 따로 임베딩할 수 있습니다.
Linear Algebraic Structure of Word Senses, with Applications to Polysemy (Arora, ..., Ma, ..., TACL 2018)
하지만 위 방법은 한 단어가 갖는 의미들을 깔끔하게 클러스터링하기 힘들다는 단점이 있습니다. 예를 들어, "pike"의 뜻 중 "창의 끝, 꼬치부분"이라는 뜻과 "봉우리가 뾰족한 산"이라는 뜻은 뾰족한 부분을 의미한다는 점에서 아에 따로 임베딩할 필요가 없어 보입니다.
따라서 이를 선형 결합을 통해 해결하고자 합니다. 여러 단어 임베딩 벡터들의 가중합을 통해 단어 벡터를 구합니다.
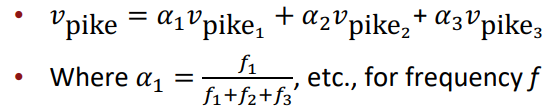
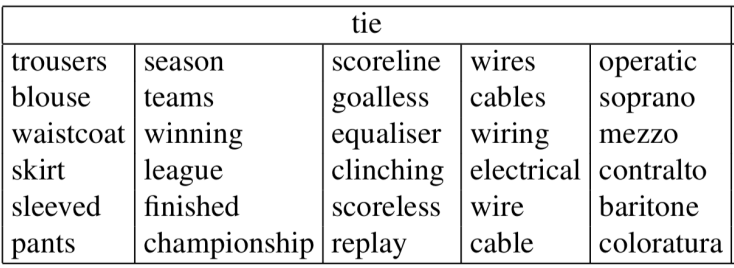
이렇게 한 번에 결합된 단어 벡터는 여러 단어의 의미를 모두 갖고있습니다. 또한 이는 sparse coding을 통해 분리할 수도 있습니다. 논문에서는 이를 통해 "tie"라는 단어로부터 분리된 다양한 단어들을 예시로 제시합니다:
https://velog.io/@jenesoolee/Sparse-Coding
Sparse Coding
Sparse의 사전적 의미는 "희미한"이라는 단어를 가지고 있다. ML의 관점에서 vector에서 대부분의 element가 0일때 sparse한 정보를 가지고 있다고 해서 이러한 상태를 sparse라고 한다.어떤 대상을 여러개
velog.io
Deep Learing Classification: Named Entity Recognition (NER)
다시 돌아와 NER에 대해 설명하자면, 어떤 텍스트 내에서 특정 단어의 태그를 달아주는 task를 말합니다. 예를 들어 다음과 같은 문장이 있을때, 다음과 같이 태그를 달아줄 수 있습니다:

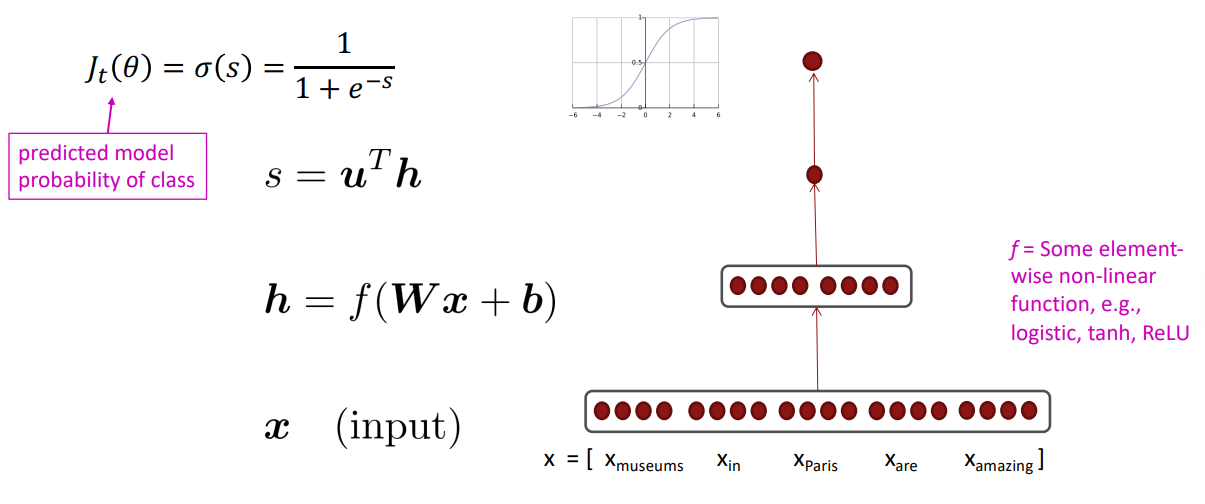
이는 어떤 단어 근처에 위치한 단어들로 구성된 context window 내에서 그 단어를 구별해주는 task입니다. 이는 window 내에 단어 벡터들을 concatenation한 벡터를 이용해서, logistic classifier를 통해 {yes/no} 태그를 붙여줍니다. 예를 들어, "Paris"라는 단어 근처 2개의 단어를 context window로 설정한다면 다음과 같은 input vector가 생성됩니다:
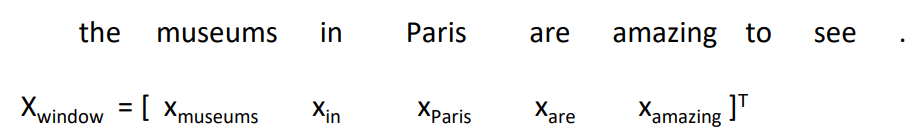
해당 벡터의 차원은 5d로 다음과 같은 과정을 따라 classify가 진행됩니다:
'[CS224N]' 카테고리의 다른 글
The skip-gram model with negative sampling
이전 강의에서 사용한 Skip-gram의 확률식을 살펴보면,
분모의 정규화식을 계산하는 데 모든 단어에 대해 exp의 합을 구하는 것을 알 수 있습니다. 만약 vocab의 크기가 50만이라면 해당 계산을 50만번 해야한다는 의미입니다. 이는 너무 계산비용이 비싸기 때문에 negative sampling이라는 기법을 통해 해당 문제를 해결하고자 합니다.
negative sampling의 핵심 아이디어는 실제 window안에 들어있는 중심 단어와 맥락 단어 쌍을 맞추고, 랜덤한 단어와 중심 단어 쌍의 틀리게 하는 방향으로 로지스틱 회귀를 진행하는 것입니다. 이때 랜덤한 단어는 10~15개의 단어로 기존 방식(=vocab size)에 비해 샘플링하는 단어의 수가 줄어 계산 비용을 줄일 수 있습니다.
09-04 네거티브 샘플링을 이용한 Word2Vec 구현(Skip-Gram with Negative Sampling, SGNS)
네거티브 샘플링(Negative Sampling)을 사용하는 Word2Vec을 직접 케라스(Keras)를 통해 구현해봅시다. ## 1. 네거티브 샘플링(Negative Samp…
wikidocs.net
이를 적용했을 때, 다음과 같은 목적함수를 갖습니다:
이때 σ()는 로지스틱/시그모이드 함수입니다. 해당 목적함수를 통해 중심 단어와 동시에 발생하는(실제 window안에 들어있는) 주변 단어의 확률을 높이고, 잡음(랜덤)한 단어와의 확률을 낮추는 방향으로 모델을 학습시킬 수 있습니다. 이를 비용함수로 바꿔보면 다음과 같습니다:
참고로 샘플링하는 단어는 유니그램 단어 분포를 따르며, 유니그램 분포의 3/4제곱을 한 분포를 따릅니다. 이를 통해 빈도가 작은 단어를 더 자주 샘플링할 수 있게, 빈도가 큰 단어를 덜 샘플링 할 수 있게 분포를 평탄화 할 수 있습니다.
(1) Q: 만약 샘플링한 k개의 단어들 중 일부가 실제 window안에 들어있는 단어여서 해당 단어가 negative sample이 아닌 경우, 해당 목적 함수가 틀릴 수 있지 않나?
A: k개의 단어가 실제 window안에 들어있는 단어일 확률은 0.01%이하입니다. 또한 그렇게 발생하는 오류를 막는 것보다 k개만 샘플링해서 정확한 단어 벡터를 얻는 것이 더 중요할 수 있습니다.
Stochastic gradients with negative sampling[aside]
negative sampling을 통해 SGD를 반복적으로 수행한다면, 각각의 window에 해당하는 단어들에 대해서만 경사를 구할 수 있을 것입니다(window안에 들어있는 단어들에 대해서만 비용함수에 따라 경사를 계산할 수 있기 때문에). 그렇다면 얻게 되는 경사 벡터는 매우 희소한 벡터(sparse vector)일 것입니다. 따라서 해당 경사를 효율적으로 계산하려면 특정 단어에 대해서만 경사 행렬을 만들어야합니다.
Why not capture co-occurrence counts directly?
그런데 왜 전체 말뭉치에 대해서 통계 데이터를 얻지 않는것일까요?
동시 등장 행렬을 만드는 방법에는 두 가지 방법이 있습니다:
- window를 활용하는 방법: 해당 방법은 word2vec과 유사합니다. 이는 단어들을 구문적, 의미론적으로 파악할 수 있습니다("word space").
- full document에 대해서 사용하는 방법: 문서-단어 동시발생 행렬은 LSA(Latent Semantic Analysis, 잠재 의미 분석)과 같은 일반적인 주제에 대해 도움이 됩니다("document space")
Example: Window based co-occurrence matrix
window기반의 동시 등장 행렬의 예시를 보겠습니다:
- window size: 1 (more common: 5~10)
- example corpus
- I like deep learning
- I like NLP
- I enjoy flying
해당 동시 등장 행렬은 symmetric합니다. 그렇기 때문에 하나 하나의 열이나 행을 단어 벡터로 사용할 수 있습니다.
Co-occurrence vectors
그저 단순하게 count기반의 동시등장 행렬의 경우 (1) 벡터의 크기가 vocab size에 비례해서 커질 수 있습니다. (2) 이는 단어 벡터가 매우 큰 차원의 벡터가 될 수 있음을, 저장하는 데에 매우 많은 공간이 필요함을 의미합니다. (3) 또한 대부분의 단어 벡터가 sparse하기 때문에 해당 단어 벡터를 사용하는 모델의 성능을 보장할 수 없습니다.
하지만 저차원의 단어 벡터를 사용하는 것은 다릅니다. 중요한 정보들은 고정한 채, 차원의 크기만 줄인 해당 방법으로, word2vec을 예로 들 수 있습니다. 일반적으로 25~1000 차원을 사용합니다. 그렇다면 어떻게 차원을 축소할까요?
Classic Method: Dimensionality Reduction on X
동시 등장 행렬 X에 대해 특이값 분해(SVD, Singular Value Decomposition)를 수행할 수 있습니다.
중간의 Σ행렬의 크기를 조절함으로써, 단어 벡터의 차원을 줄일 수 있고, 특이값의 크기를 통해 적절한 차원을 구할 수도 있습니다.
Hacks to X (several used in Rohde et al. 2005 in COALS)
하지만 그냥 개수 기반의 동시 등장 행렬에 SVD를 적용하는 것은 효과적이지 못합니다. 'the', 'he', 'has'와 같은 기능어들이 너무 자주 등장하기 때문에 의미론적으로 비교적 덜 등장하는 단어들에 대해 의미론적으로 분석하기가 힘들기 때문입니다. 또한 다양한 문제가 있을 수 있는데, 이를 해결하기 위한 방법은 다음과 같습니다:
- log the frequencies: 빈도에 log를 취함으로써, 빈도가 큰 단어들에 대해 패널티를 줍니다.
- min(X, t), with t ≒ 100: 특정 빈도수 이상의 단어들에 대해 패널치를 줍니다.
- Ignore the function words: 전처리를 통해 기능어들을 아에 빼줍니다.
- Ramped windows: 멀리 있는 단어보다 가까이 있는 단어의 중요도를 높여주는 특수한 window를 통해 동시 등장 행렬을 만들어줍니다.
- Using Person correlation: 개수(count) 대신 상관 계수를 사용합니다.
Interesting semantic patterns emerge in the scaled vectors
이를 통해 구해진 단어 벡터를 보면 재미있는 특징을 발견할 수 있습니다. 단어끼리의 관계가 벡터 공간에 투영된 것입니다. 예를 들어 위 그림은 어떤 동작과 해당 동작을 수행하는 사람과의 관계를 보여줍니다. 해당 관계를 나타내는 벡터들은 크기와 방향을 대략 유사함을 확인할 수 있습니다.
GloVe: Encoding meaning components in vector differences
앞서 단어 벡터를 만드는 방법으로 두 가지 방법을 살펴봤습니다:
- window를 활용하는 방법
- 장점: 예측 기반으로 단어 간 유추 작업이나, 유사성을 분석하는 데에 유리합니다.
- 단점: 임베딩 벡터가 window 크기 내에서만 주변 단어를 고려하기 때문에 말뭉치(corpus)의 전체적인 통계 정보를 반영하지는 못합니다.
- count기반 동시 등장 행렬
- 장점: 말뭉치의 전체적인 통계 정보를 활용할 수 있고, 계산 속도가 빠릅니다.
- 단점: 왕:남자 = 여왕:? 과 같은 단어 의미의 유추 작업에는 성능이 떨어집니다.
GloVe의 목표는 바로 "임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 말뭉치에서의 동시 등장 확률이 되도록" 만드는 것입니다. 다시 말해, 확률 기반 동시 등장 행렬을 통해 얻은 것을 벡터 공간에 투영하는 것입니다. 이를 통해 두 가지 방법의 장점을 모두 잡고자합니다(Q: How can we capture ratios of co-occurence probabilities as linear meaning components in a word vector space?).
이는 다음과 같은 손실 함수를 갖는 모델을 통해 이루어집니다:
이는 단어 벡터 i와 j의 내적과 동시 등장 행렬에서의 단어 i와 j의 값, Xij가 같아지도록 합니다. 앞에 붙은 f()는 가중치항으로, 동시 등장 출현 빈도가 높은 단어 쌍에는 낮은 가중치(Loss값이 증가)를 부여하고, 빈도가 낮은 단어 쌍에는 높은 가중치를 부여해서 출연 빈도가 높은 단어 쌍에 대해서 더 정교하게 임베딩을 합니다. 이때의 f()함수는 다음과 같습니다:
하지만 높은 빈도수를 가졌다고 지나치게 가중치가 높아서는 안됩니다. 따라서 일정 빈도(Xmax)이상이라면 최대값으로 가중치항이 고정됩니다.
결과적으로 이는 두 가지 방법의 장점을 모두 갖습니다. (1) 빠른 훈련속도를 달성하고, (2) 큰 말뭉치에 대해서도 통계적인 임베딩 모델을 구축할 수 있습니다.
09-05) 글로브(GloVe)
글로브(Global Vectors for Word Representation, GloVe)는 카운트 기반과 예측 기반을 모두 사용하는 방법론으로 2014년에 미국 스탠포드대학에서…
wikidocs.net
How to evaluate word vectors?
NLP에서의 평가 방법은 두 가지가 있습니다:
- Intrinsic:
- 특정 subtask에서나 중간 단계에서 평가를 진행하는 방법
- 시스템을 이해하는데 도움을 주고, 평가 계산이 빠릅니다.
- 하지만, 해당 평가가 실제 task에 좋은 영향을 줄 지는 모릅니다.
- Extrinsic:
- 실제 task에 대해서 평가합니다.
- 하지만, 결과가 아래의 subsystem이 문제인지, 아니면 subsystem끼리의 연결이 문제인지를 알 수 없습니다.
Intrinsic word vector evaluation
다양한 방법이 존재합니다. 앞서 말했던 Word Vector Analogies(단어 유추)가 Intrinsic한 평가에 해당합니다.
어떤 단어 벡터에 대해 특정 의미론적, 구문론적 유추 질문에 대한 벡터를 더하면 얼마나 잘 정답 단어 벡터를 예상할 수 있는지를 평가합니다. 하지만, 벡터 관계를 더하여 구할 수 있는 관계에 대해서만 평가를 할 수 있다는 단점이 있습니다. 즉, 어떤 관계가 선형으로 결합되는 관계가 아니라면 이를 평가할 수 없습니다.
GloVe Visualization
GloVe또한 잘 벡터 공간에서 단어들끼리의 관계가 선형으로 유지됨을 확인할 수 있습니다.
Meaning similarity: Another intrinsic word vecotr evaluation
어떤 단어 쌍에 대한 사람의 판단과 단어 벡터끼리의 유사도와 거리를 비교하여 평가할 수 있습니다. 예시 데이터 셋으로는 WordSim353이 있습니다(http://www.cs.technion.ac.il/~gabr/resources/data/wordsim353/).
WordSim353 평가 결과 GloVe가 다른 방법들에 비해(SG(Skip-gram), SVD) 좋은 Intrinsic평가 결과를 갖습니다. 참고로 Chris Manning은 좋은 결과가 양질의 데이터 확보 유무 때문이라고 평가합니다(GloVe를 학습하는데 사용한 데이터는 당시 최신 데이터였음).
Extrinsic word vector evaluation
Extrinsic평가의 좋은 예로는 NER(named entity recognition, 개채명인식) task가 있습니다. 이를 통해 임베딩 모델의 성능을 유추할 수 있습니다.
Word senses and word sense ambiguity
하지만 지금까지 간과하고 있었던 사실이 있습니다. 사실 대부분의 단어들은 많은 뜻을 갖습니다. 이를 하나의 벡터로 임베딩하는 것은 과연 옳을까요?
예를 들어 "pike"라는 단어는 정말 많은 뜻을 갖습니다:
- A sharp point or staff
- A type of elongated fish
- A railroad line or system
- A type of road
- The future (coming down the pike)
- To kill or pierce with a pike
- To make one's way (pike along)
- In Australian English, pike means to pull out from doing something: I reckon he could have climbed that cliff, but he piked!
Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012)
해당 문제를 해결하기 위한 방법으로 단어들을 미리 클러스터링 해서 임베딩을 하는 방법이 있습니다. 아래의 그림은 그 결과 임베딩된 벡터들을 시각화한 결과입니다:
jaguar의 경우 왼쪽 위에 있는 luxury, convertible이라는 단어와 함께 있는 것으로 보아 자동차 브랜드 jaguar를 의미하고, 중간에 keyboard와 같이 있는 jaguar의 경우는 키보드 브랜드 jaguar를 의미하며, 오른쪽 아래의 jaguar는 hunter와 같이 있는것으로 보아 동물 jaguar를 의미합니다. 이렇게 미리 클러스터링하여 임베딩을 하면, 다양한 의미를 갖는 단어들을 따로 임베딩할 수 있습니다.
Linear Algebraic Structure of Word Senses, with Applications to Polysemy (Arora, ..., Ma, ..., TACL 2018)
하지만 위 방법은 한 단어가 갖는 의미들을 깔끔하게 클러스터링하기 힘들다는 단점이 있습니다. 예를 들어, "pike"의 뜻 중 "창의 끝, 꼬치부분"이라는 뜻과 "봉우리가 뾰족한 산"이라는 뜻은 뾰족한 부분을 의미한다는 점에서 아에 따로 임베딩할 필요가 없어 보입니다.
따라서 이를 선형 결합을 통해 해결하고자 합니다. 여러 단어 임베딩 벡터들의 가중합을 통해 단어 벡터를 구합니다.
이렇게 한 번에 결합된 단어 벡터는 여러 단어의 의미를 모두 갖고있습니다. 또한 이는 sparse coding을 통해 분리할 수도 있습니다. 논문에서는 이를 통해 "tie"라는 단어로부터 분리된 다양한 단어들을 예시로 제시합니다:
https://velog.io/@jenesoolee/Sparse-Coding
Sparse Coding
Sparse의 사전적 의미는 "희미한"이라는 단어를 가지고 있다. ML의 관점에서 vector에서 대부분의 element가 0일때 sparse한 정보를 가지고 있다고 해서 이러한 상태를 sparse라고 한다.어떤 대상을 여러개
velog.io
Deep Learing Classification: Named Entity Recognition (NER)
다시 돌아와 NER에 대해 설명하자면, 어떤 텍스트 내에서 특정 단어의 태그를 달아주는 task를 말합니다. 예를 들어 다음과 같은 문장이 있을때, 다음과 같이 태그를 달아줄 수 있습니다:
이는 어떤 단어 근처에 위치한 단어들로 구성된 context window 내에서 그 단어를 구별해주는 task입니다. 이는 window 내에 단어 벡터들을 concatenation한 벡터를 이용해서, logistic classifier를 통해 {yes/no} 태그를 붙여줍니다. 예를 들어, "Paris"라는 단어 근처 2개의 단어를 context window로 설정한다면 다음과 같은 input vector가 생성됩니다:
해당 벡터의 차원은 5d로 다음과 같은 과정을 따라 classify가 진행됩니다: