Machine Translation
기계 번역은 어떤 언어(the source language)의 문장 x를 또 다른 언어(the target language)의 문장 y로 번역하는 태스크를 말합니다.

1990s-2010s: Statistical Machine Translation
초창기의 기계 번역은 통계적 기계 번역이었습니다. 이는 확률 모델을 통해 번역을 하는 것을 말하는데, 프랑스어 → 영어 번역 태스크의 경우 주어진 프랑스어 문장 x에 대한 완벽한 영어 문장 y를 찾고 싶을 때, 다음과 같은 식을 풀면 되는 것입니다:
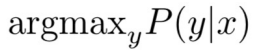
이 식에 베이즈 법칙을 적용하면 다음의 두 부분으로 쪼갤 수 있습니다:
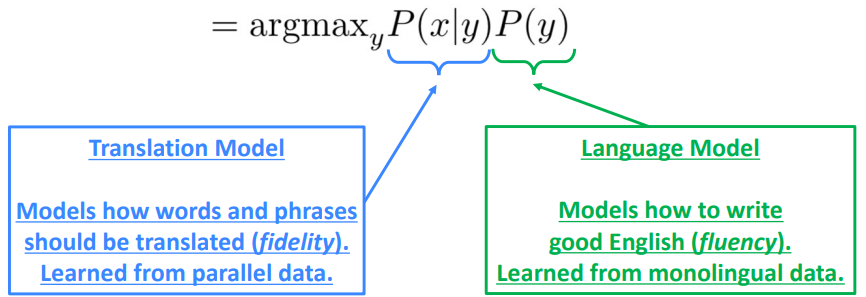
이 두 부분을 살펴보면, 앞쪽에 부분은 영어 문장 y에 대한 프랑스어 x의 확률로, 영어 → 프랑스어 번역 모델에 대해 설명하고 있습니다. 그 다음으로 뒷쪽 부분은 영어 문장 y에 대한 확률로, 이는 영어 문장의 생성에 대한 언어 모델에 대해 설명하고 있습니다. 그렇다면 앞부분 P(x|y)는 어떻게 구할 수 있을까요?
이는 영어 → 프랑스어에 해당하는 많은 양의 병렬 데이터가 필요합니다. 많은 양의 영어 to 프랑스어 데이터를 통해 P(x|y)를 잘 학습시키는 것입니다.
Decoding for SMT
그렇다면 어떻게 argmax y를 구할 수 있을까요? 만약 가능한 모든 영어 문장 y에 대해 확률을 계산한다면 비용이 매우 많이 드는 작업이 될 것입니다. 그렇기 때문에 굉장히 dynamic한 알고리즘을 이용해서 decoding을 수행합니다.
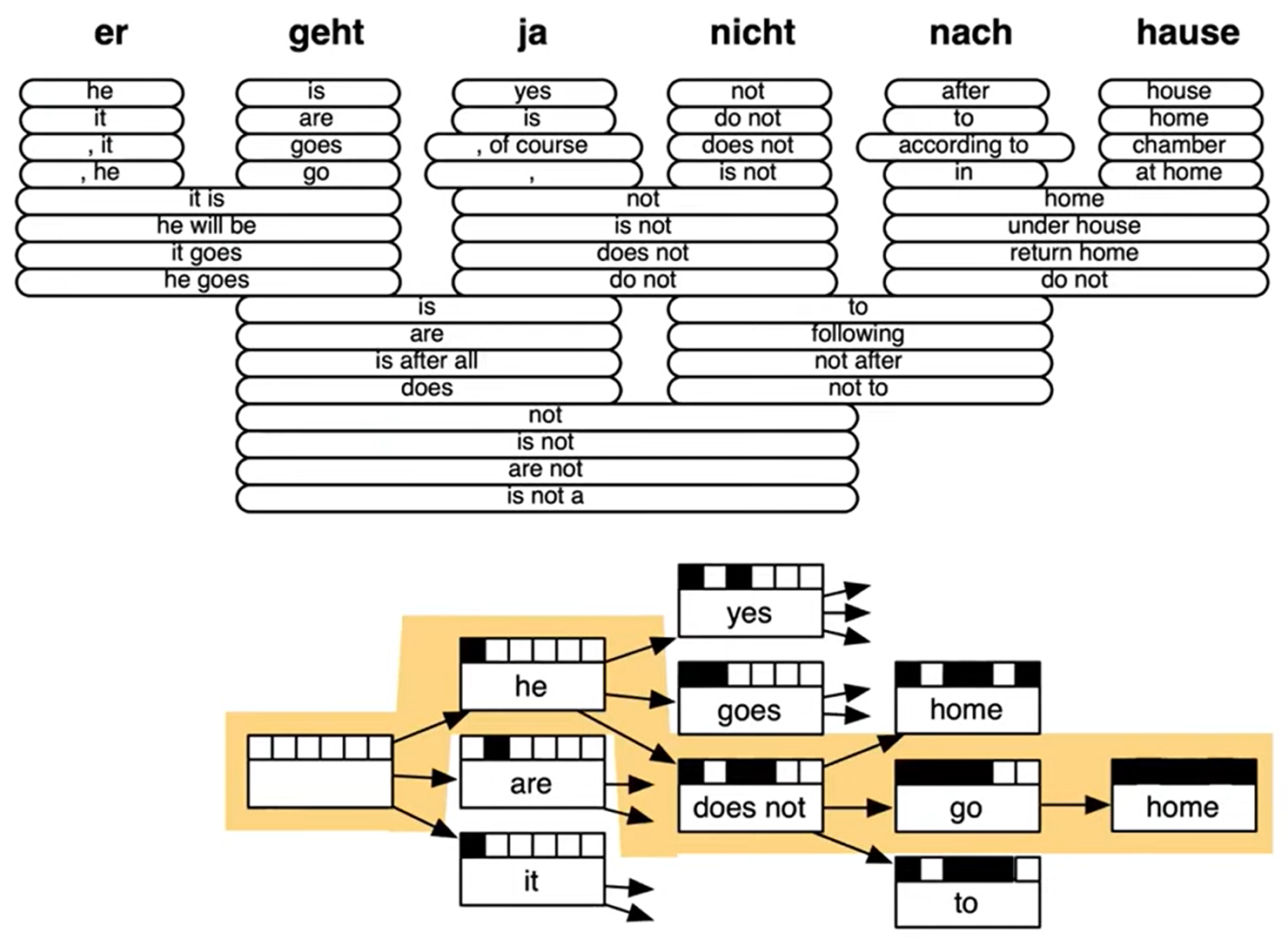
위 알고리즘은 통계적 기계 학습 모델의 디코딩 알고리즘입니다. 이는 가능한 모든 y에 대해 탐색하는 것이 아닌 문법 규칙에 기반하여, 그리고 다이나믹하게 문장 트리를 탐색하며 최적의 문장 y를 찾는 것입니다. 자세한 내용은 "Statistical Machine Translation", Chapter 6, Koehn, 2009를 참고하면 됩니다.
이런 통계적 접근에는 한계가 있었습니다. (1) 많은 문법 규칙들이 적용될 수 있고, 적용되야 하므로, 좋은 모델이 될 수록 점점 더 모델이 복잡해졌습니다. (2) 또한 이런 추가 규칙들이나 디테일들을 유지하는 데 자원 비용이 너무 많이 들며, (3) 마지막으로 이를 유지 보수하기에 인간에 노력이 너무 많이 듭니다.
What is Neural Machine Translation?
Neural Machine Translation (NMT)는 두 개의 RNNs들을 포함하는 sequence-to-sequence 모델이라 불리는 신경망 모델을 말합니다.
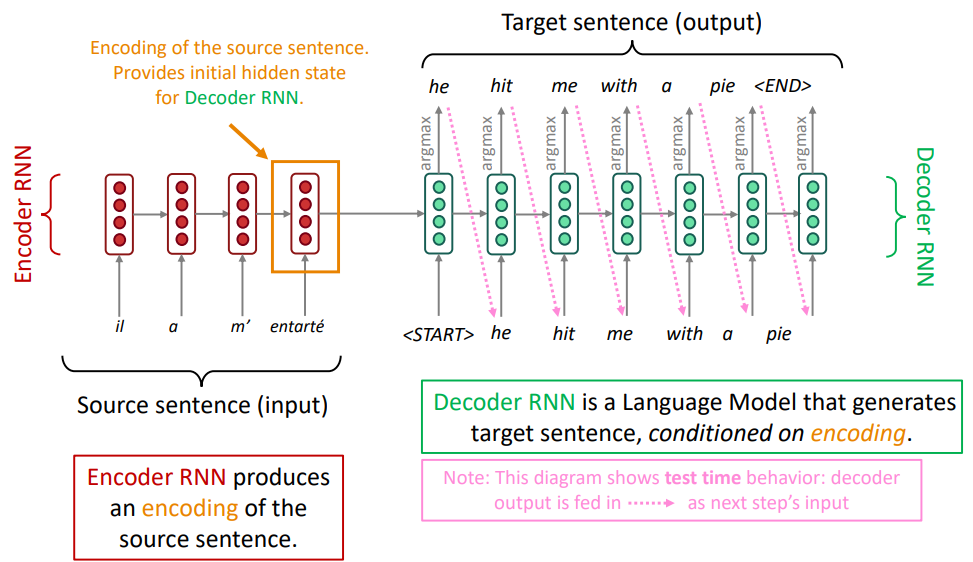
이 seq2seq모델은 일반적인 encoder-decoder모델의 구조를 띕니다. 이는 신경망을 통해 입력을 신경망 표현으로 변경하고, 출력 또한 신경망을 통해 신경망 표현으로 변경하는 것을 말합니다. 이는 그냥 Machine Translation 모델에 비해 매우 효과적입니다. 또한 MT가 아닌 다양한 NLP분야(Summarization, Dialogue, Parsing, Code generation, etc.)에서도 사용가능합니다.
Neural Machine Translation (NMT)
이 seq2seq모델은 조건부 언어 모델 (Coditional Language Model)의 대표적인 예 입니다. 이때 조건부란 어떤 입력 문장 x가 조건으로 사용되어 다음 예측을 한다는 것을 말합니다. 이런 조건부 언어 모델에 특징으로 NMT는 다음과 같은 확률 계산식을 갖습니다:

이는 이전의 문장들이 조건이 되어 다음 문장을 생성한다는 뜻으로, 조건부 확률을 이용해 확률 계산을 수행합니다.
Training a Neural Machine Translation system
그렇다면 NMT는 어떻게 학습시킬까요?
매우 매우 많은 양의 병렬(the source language and the target language) 말뭉치가 있으면 됩니다.
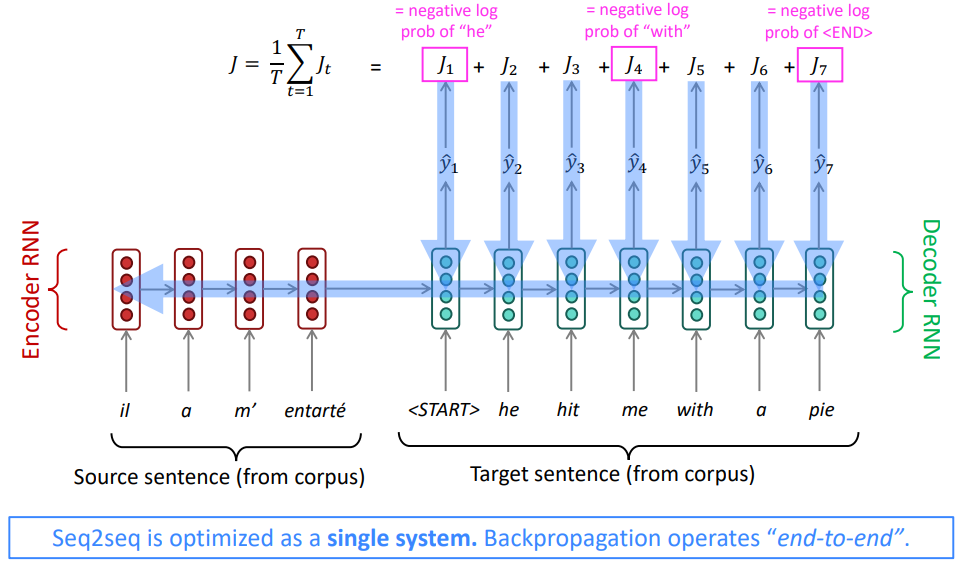
병렬 데이터를 통해, 그리고 역전파를 통해 인코더와 디코더의 가중치 행렬을 손실 함수를 따라 업데이트합니다.
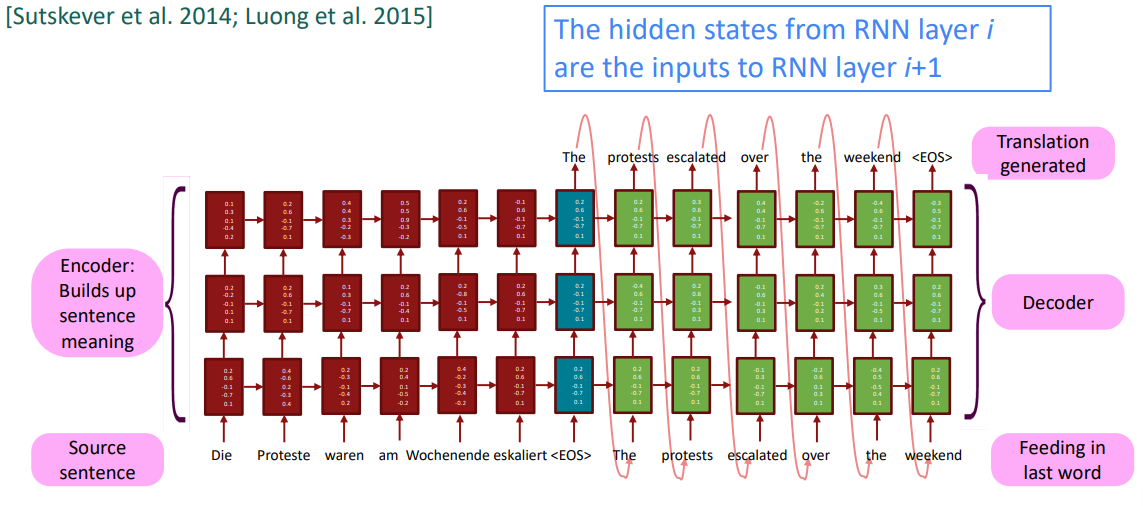
Multi-layer deep encoder-decoder machine translation net [Sutskever et al. 2014; Luong et al. 2015]
사실 seq2seq는 위 그림같이 하나의 차원만을 갖는 RNNs들의 조합으로 이루어지지 않고, 이전 강의의 마지막에 살펴보았던 다중 계층 RNNs을 통해 구현됩니다. 이를 통해 언어의 다양한 특징들을 깊이 있게 encoding하고, 이런 다양한 특징들에 따라 언어를 decoding합니다. 실제 구조는 다음과 같습니다:
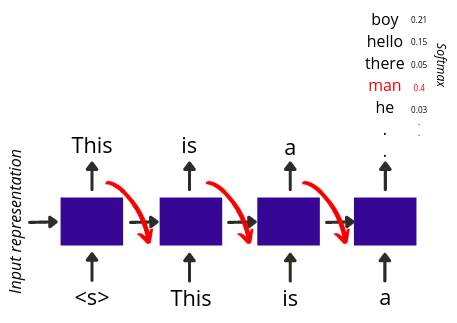
Greedy decoding
이때 decoding의 방법은 다양하게 존재합니다. 우선 지금까지 살펴봤던 decoding방법은 greedy decoding으로 매 timestep마다 argmax의 결과에 해당하는 토큰을 이용하여 target sentence를 생성하는 방법입니다.
하지만 이런 decoding방법에는 문제가 있을 수 있습니다. 뒤로 돌아갈 수 없다. 기술적으로 local optima에 빠질 수 있다는 문제가 있습니다.

입력에 해당하는 프랑스어 문장은 "그가 나를 파이로 때렸다." 이지만 이를 seq2seq의 구조에 따라 한 토큰씩 decoding을 수행하면 다음과 같은 문제가 발생합니다. he hit 까지 생성한 후 a 와 me 중에서 a 가 확률이 더 높은 선택일 수 있는 것입니다. 즉 그 순간의 좋은 선택이 전체 문장에 대한 가장 좋은 선택이 안 될 수도 있는 것입니다.
Exhaustive search decoding
greedy decoding은 전체 문장에 대한 가장 좋은 선택이 매 timestep에서의 좋은 선택들의 조합이 아닐 수 있다는 것이 문제였습니다. 그렇다면 애초에 전체 문장에 대한 가장 좋은 선택을 찾으면 어떨까요?
전체 target 문장 y에 대해서 입력 문장x가 있다면, P(y|x)를 구하려면 모든 가능한 y에 대해 확률을 구해 대소를 비교해야할 것입니다. 만약 target 문장의 길이가 T이고, 각 토큰의 종류가 V라면 가능한 모든 y는 V^t입니다.
즉, 모든 선택을 탐색하려면 O(V^t)의 시간 복잡도를 갖습니다. 이는 너무 오래걸립니다.

Beam search decoding
이를 해결하기 위해 Beam search를 활용한 decoding 방법론을 사용합니다.
2024.11.01 - [[학교 수업]/[학교 수업] 인공지능] - [인공지능] 경험적 탐색
[인공지능] 경험적 탐색
반복적 깊이 심화 탐색 깊이 한계가 있는 깊이 우선 탐색을 반복적으로 적용하는 방법으로,메모리 사용이 최적화된 DFS와 최적해를 탐색하는 것이 보장되어있는 BFS의 장점만을 이용해 탐색하는
hw-hk.tistory.com
매 timestep마다 가장 유망한 번역들(hypotheses)들을 계속해서 추적합니다. 유망한 가정들은 점수(score)를 통해 선택합니다. 이때 hypothesis y1, ..., yt의 score는 다음 식으로 계산합니다.
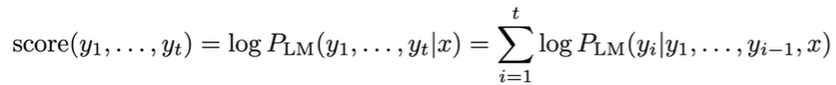
각 토큰들에 대한 확률이 0-1 사이의 수이기 때문에 각 가정들의 점수는 음수입니다. 만약 beam size가 k라면 매 timestep마다 가장 점수가 높은 k개의 가정들을 지속해서 추적합니다. 하지만 greedy search와 유사하게 해당 방법은 최적해를 보장하지는 않습니다. 다음은 beam search decoding의 예시입니다:
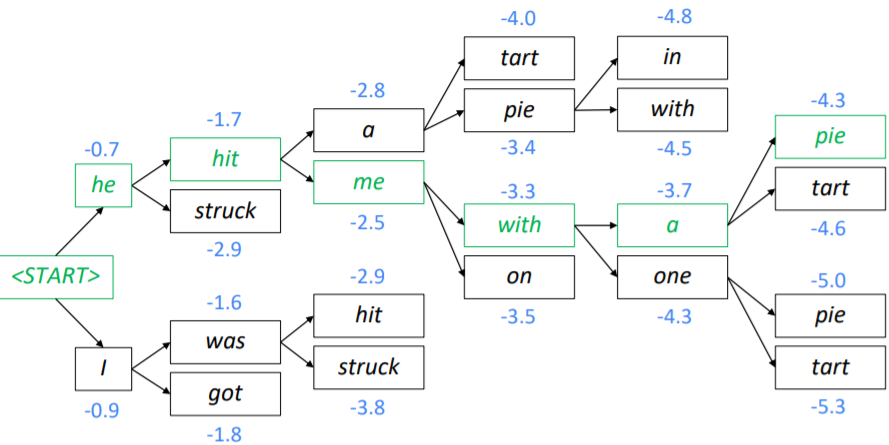
greedy decoding은 <END> 토큰이 나올 때까지만 decoding을 수행하면 되지만(예: <START> he hit me with a pie <END>), beam search decoding은 <END> 토큰이 나오느 timestep이 가정들 마다 다를 수 있습니다. 그렇기 때문에, 각 추적하고 있는 가정들에서 <END> 토큰이 나올 때까지 추적을 지속합니다. 하지만 탐색의 깊이가 너무 깊다면 비효율적이기 때문에, 일정한 timestep T를 설정하여 T이상의 timestep을 갖는 가정은 강제로 추적을 종료하거나, cutoff값 n을 설정하여, 최소 n개의 완성된 가정들이 나올 때까지 수행하는 방식으로 종단점을 설정할 수 있습니다.
이렇게 모든 가정들이 <END> 토큰을 생성했다면, 이들 중 가장 score가 좋은 가정을 최종 출력으로 선택합니다. 하지만 이때 문제가 있습니다. 각각의 score는 음수이고, 최종 score는 이들 score의 합으로 구하기 때문에 문장의 길이가 길어질수록 score가 낮아집니다. 따라서 이 문제를 해결하기 위해 최종 문장 길이 T로 정규화를 수행하여 최종 점수를 추출합니다:

Advantages of NMT
SMT와 비교해서 NMT는 어떤 장점이 있을까요?
- 더 나은 성능
- 더 유창한 표현과 맥락을 더 잘 이해합니다.
- 유지 보수를 위한 사람의 노력이 덜 합니다.
- feature engineering이나 여러가지 디테일들을 적용할 필요가 없습니다.
Disadvantages of NMT
그렇다면 어떤 단점이 있을까요?
- 해석이 힘들다
- 모델의 내부 구조를 알 수 없기 때문에(blackbox) 디버깅을 하기 어렵습니다.
- 통제하기 힘들다
- 예를 들어 어떤 특별한 규칙같은 것을 모델에 직접적으로 적용하기 힘듭니다.
- 안전 규칙들을 적용하기 힘듬
How do we evaluate Machine Translation?
번역 모델을 평가하는 방법은 정말 많습니다. 그 중 가장 대표적인 방법이 BLEU (Bilingual Evaluation Understudy)입니다. 이 방법은 n-gram 정확도(일반적으로 1,2,3 and 4-grams)를 이용해 인간이 작성한 번역본과 기계 모델이 작성한 번역본을 비교하는 것입니다.
하지만 BLEU는 완전하지는 않습니다. (1) 문장 번역에 대한 다양한 해석을 평가할 수 없다는 점 때문입니다. 정답 해석 문장은 오직 한 문장이고 이에 대한 유사도를 평가하는 것이기 때문에, 동일한 문장에 대한 다양한 표현을 포함할 수 없습니다. (2) 또한 높은 BLEU 점수는 그저 인간 번역과 n-gram이 겹치는 수준이 높다는 것을 의미하지, 해당 기계 번역 모델이 더 나은 모델이라는 것을 증명하지는 않습니다.
MT progress over time
MT에 신경망이 적용되면서 정말 많은 변화가 일어났습니다.
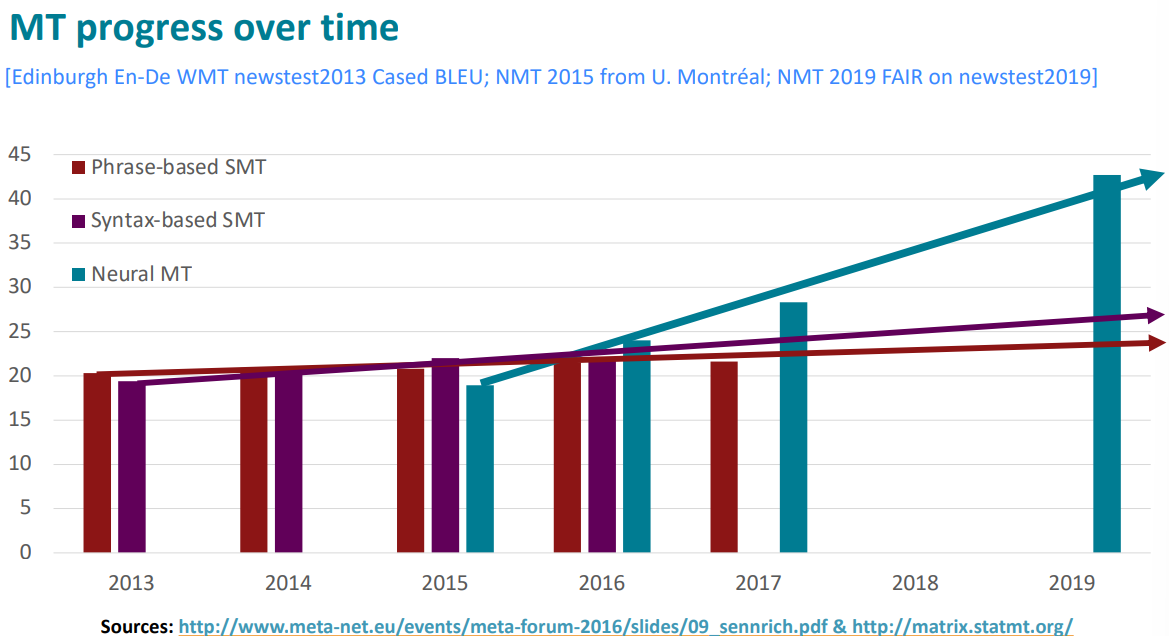
So is Machine Translation solved?
그렇다면 신경망이 적용되어서 MT분야에서는 모든 문제가 해결되었을까요?
아닙니다. 아직 많은 문제가 있습니다:
- Out-of-vocabulary words, 데이터에 없는 단어를 생성할 수는 없습니다.
- Domain mismatch between train and test data, 만약 뉴스데이터로 학습을 했다면, 의료 분야에서의 번역은 완벽하지 않을 수 있습니다.
- Maintaining context over longer text, 긴 문장에 대해 맥락을 잃어버릴 수 있습니다.
- ...
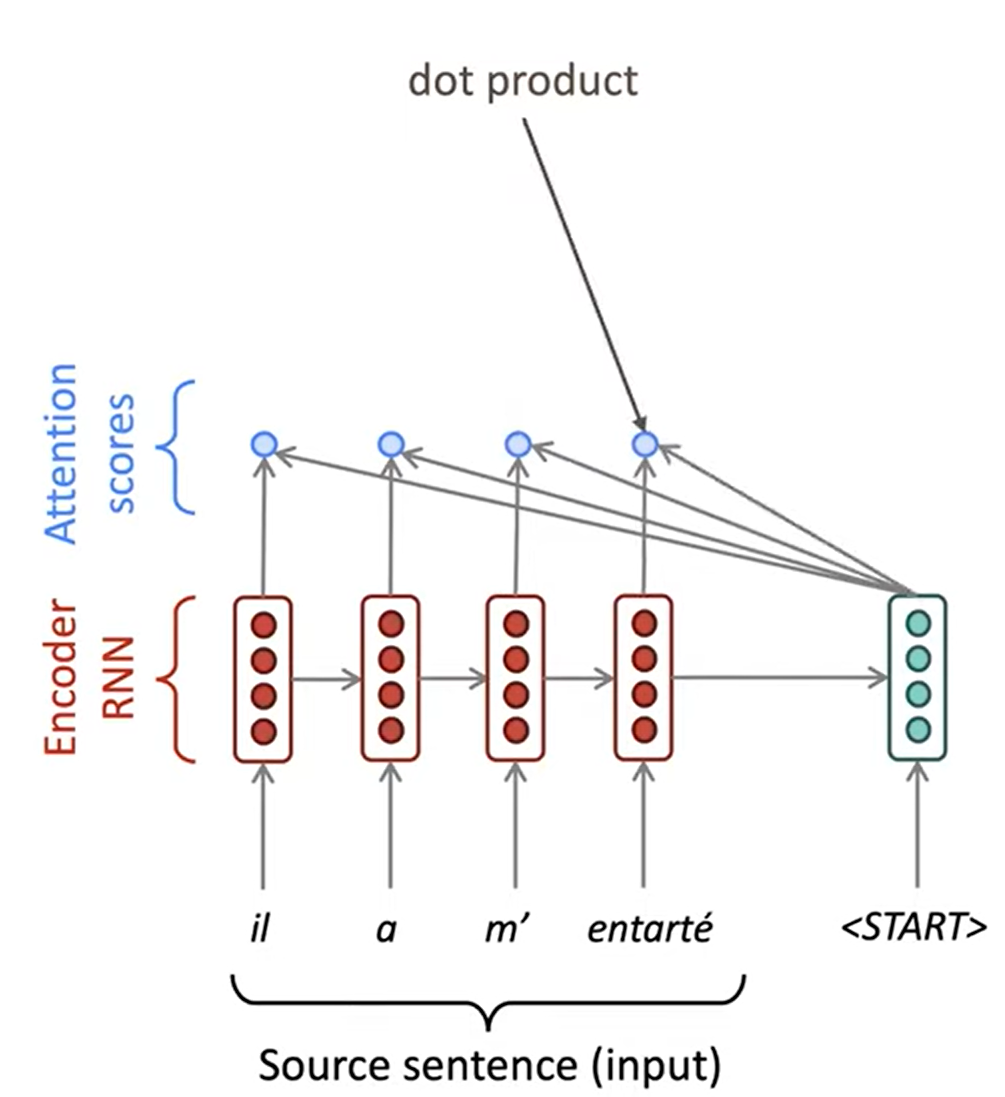
Attention
NMT는 NLP Deep Learning에 매우 중요한 일이었습니다. NMT 연구는 최근 NLP Deep Learning에서의 혁신의 선구자였습니다. 2021년에도 NMT연구는 계속 이루어지고, 기본이 되는 "vanilla" seq2seq NMT에서 정말 많은 발견과 발전을 이뤘습니다. 이때 가장 중요한 발전 한 가지를 설명하자면 바로 Attention입니다.
Sequence-to-sequence: the bottleneck problem
seq2seq의 문제는 encoding된 정보가 하나의 고정된 길이의 벡터로 압축된다는 점입니다. 이를 encoder와 decoder사이에 병목(bottleneck)이 있다고 표현합니다.
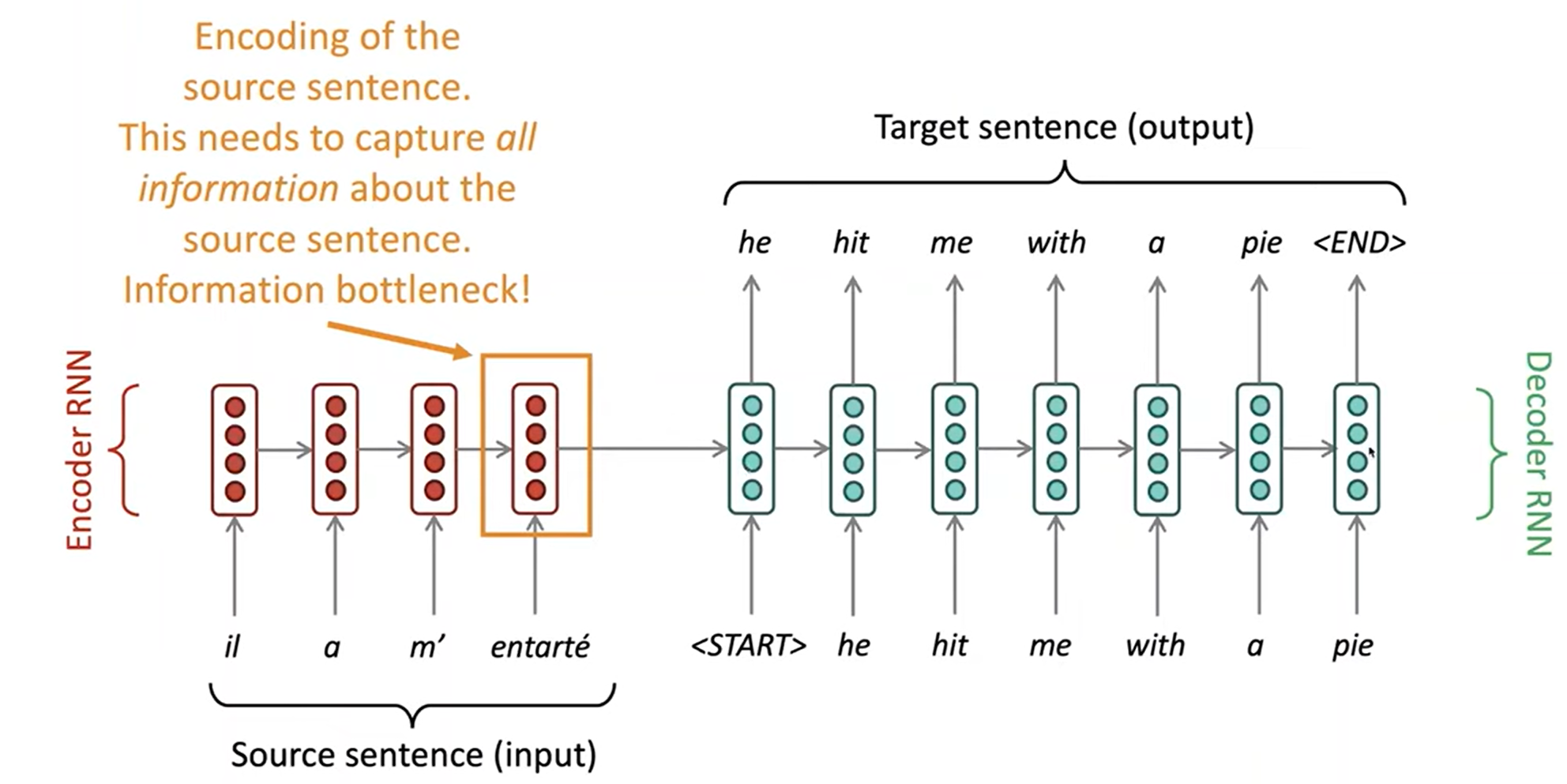
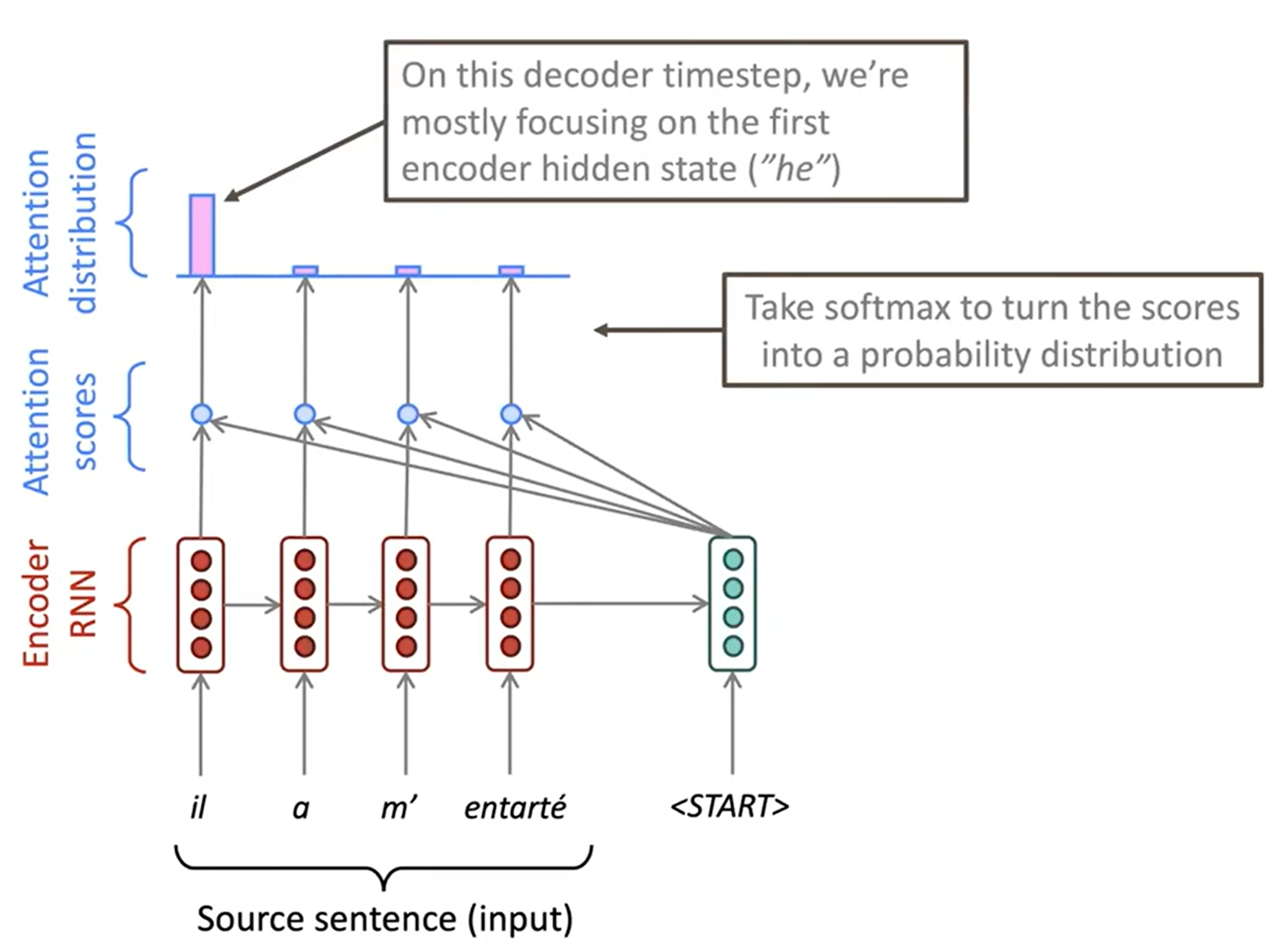
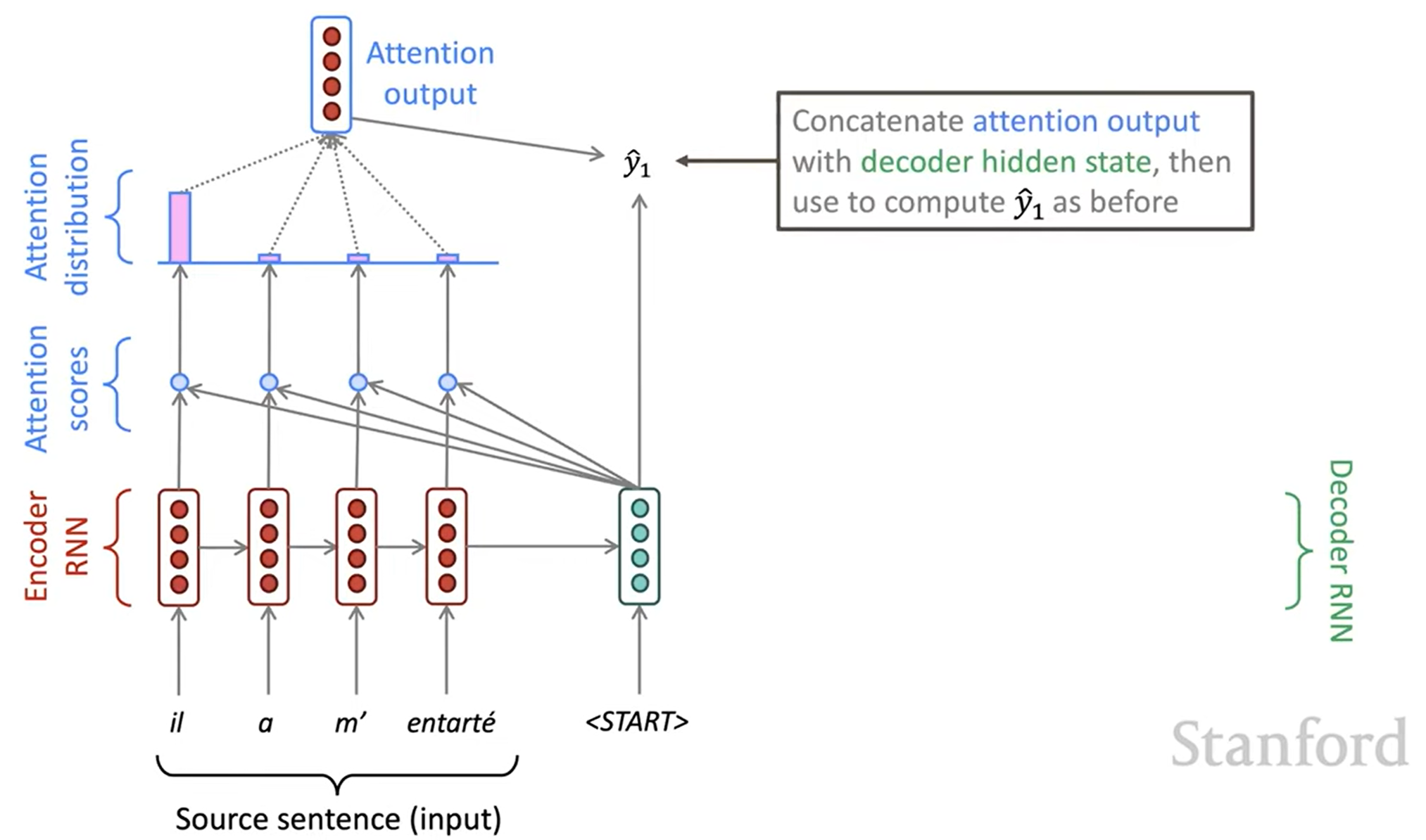
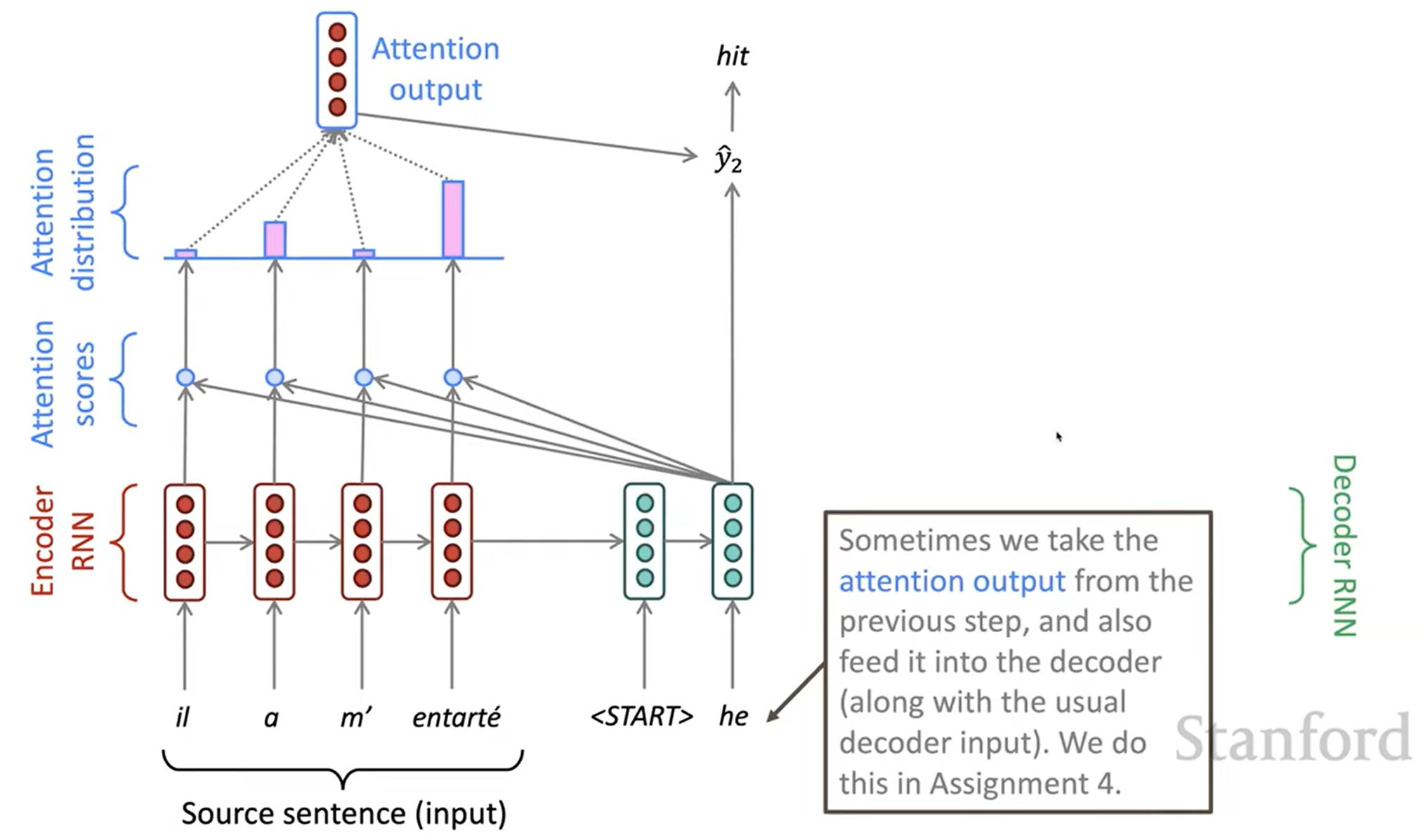
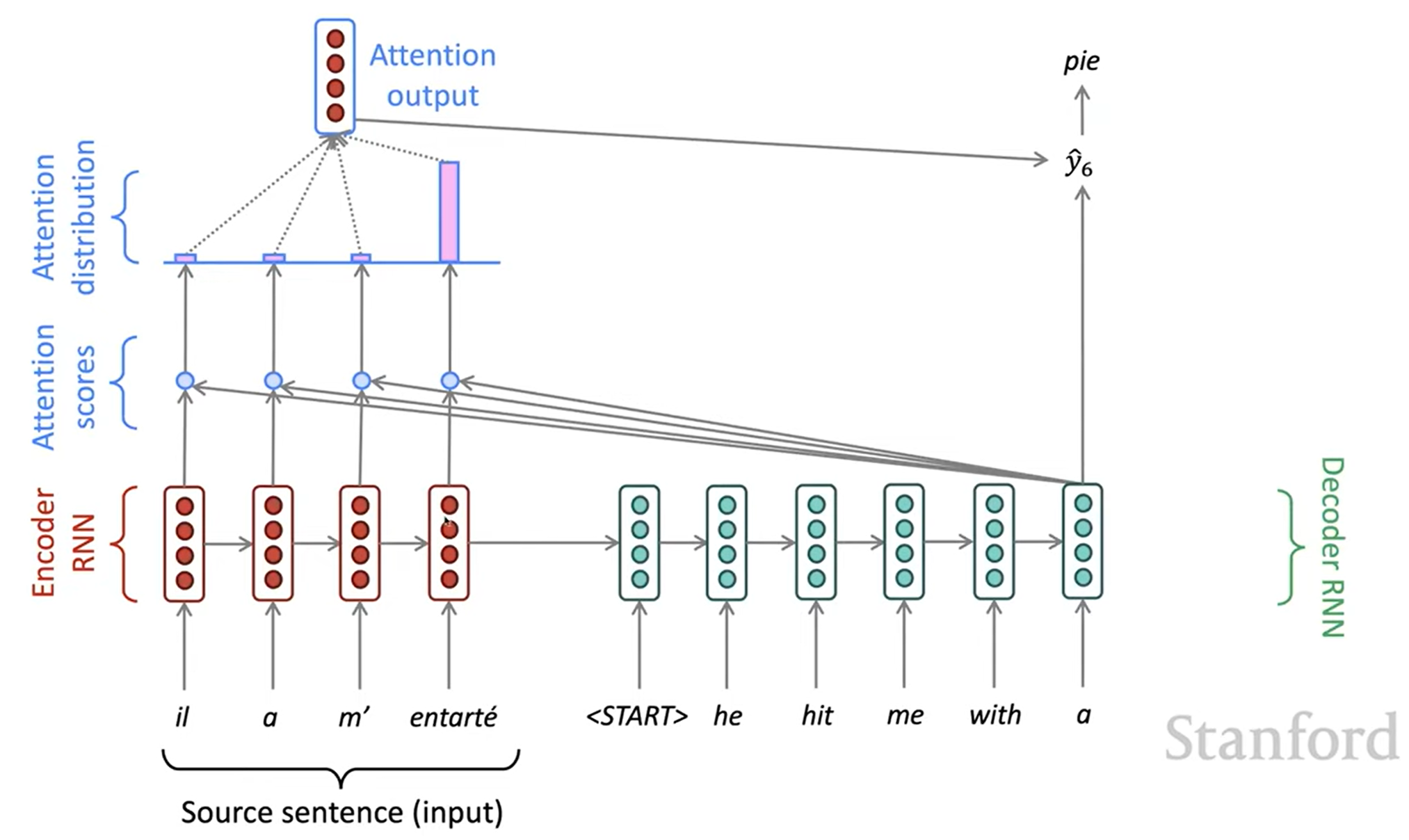
Attention
Attention은 bottleneck 문제를 해결할 수 있습니다. 핵심 아이디어는 decoder의 각 timestep마다 encoder의 직접적인 연결을 이용해 원본 문장(source sequence)의 특정한 부분에 집중하게 하는 것입니다. 다음은 Attention이 동작하는 것을 그림으로 나타낸 것입니다: