Word structure and subword models
Pretraining에 대해 알아보기 전에 단어들을 어떻게 파싱하는 지에 대해 알아보겠습니다. 지금까지는 정해진 vocab에 대해 embedding을 진행했습니다. 그리고 정해진 vocab에 들어있지 않은 단어들은 UNK (unknown)처리를 했습니다. 하지만 그렇게 된다면 철자를 실수로 틀렸거나, 신조어등은 임베딩하지 못하게 되며, 많은 양의 정보들을 잃을 수도 있습니다.
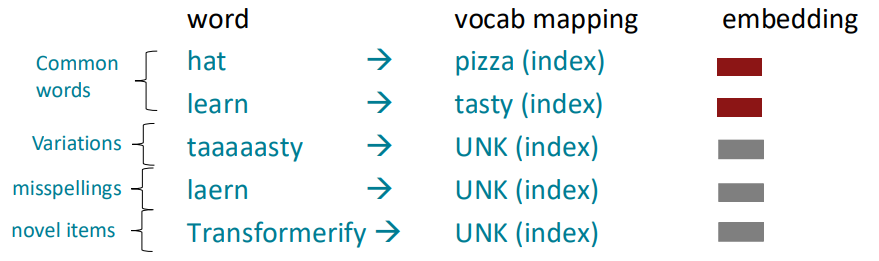
예를 들어, Swahili의 동사들은 수백여개의 파생형 동사들이 존재합니다. 이를 모두 다른 index로 처리한다면 vocab의 크기가 매우 매우 커질 수 있습니다. 하지만 해당 동사의 파생형들은 앞 부분에 공통적인 character들을 갖고 있기 때문에 subword vocab을 사용한다면 이를 효율적으로 처리할 수 있습니다.
The byte-pair encoding algorithm
이처럼 이런 문제를 해결하기 위해서 기존의 word를 잘게 쪼개서 인코딩하는 형태의 subword modeling 방식이 등장했습니다. 그 방식들 중 Byte-pair encoding은 간단하면서 매우 효율적으로 subword vocabulary를 만드는 방법입니다. 이는 아래와 같은 알고리즘을 따릅니다:
- Start with a vocabulary containing only characters and an "end-of-word" symbol; 처음 vocab에는 가장 기본 문자들과 eow 만을 넣습니다.
- Using a corpus of text, find the most common adjacent characters "a,b"; add "ab" as a subword; 코퍼스를 이용해 가장 자주 등장하는 인접한 문자들을 하나의 subword로 하여 vocab에 추가합니다.
- Replace instances of the character pair with the new subword; repeat until desired vocab size; 이렇게 나온 subword들을 이용해 또 다른 subword들을 만들며 원하는 vocab size가 될 때까지 반복합니다.
BPE을 통해서 위 그림의 예시를 다시 분석해보면 다음과 같이 embedding할 수 있습니다:
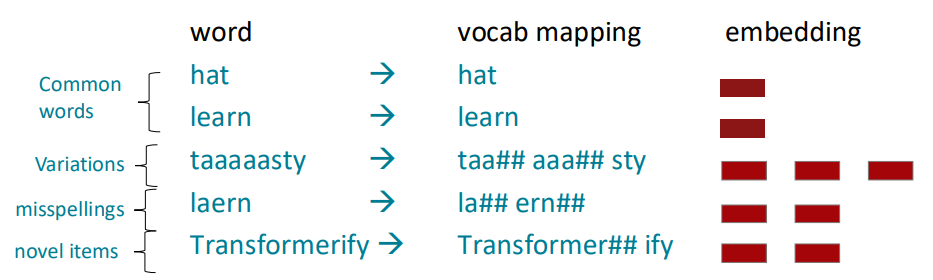
*한 단어 내에서 가장 적은 수의 subword가 등장하는 방향으로 선택합니다. 만약 너무 잘게 subword를 선택한다면 seq의 길이가 늘어나며, 이는 모델이 입력으로 받을때 overhead를 증가시킬 수 있습니다. 예를 들어, Tansformerify의 경우 if도 많이 등장하는 subword이기 때문에 Transformer##if##y 로 나눌 수도 있습니다.
Motivating word meaning and context
J.R Firth의 말을 다시 한 번 인용해보겠습니다:
"... the complete meaning of a word is always contextual, and no study of meaning apart from a complete context can be taken seriously."
J. R. Firth 1935
즉 맥락을 이용해서 그 뜻을 파악하라는 뜻인데요.
예를 들어 I record the record 라는 문장이 있을 때, 앞에 있는 record와 뒤에 있는 record는 다른 뜻이 됩니다. 하지만 word2vec의 경우 record를 여러 의미를 중첩해서 가지고 있는 하나의 벡터로 embedding할 것입니다. record가 사용되는 순간의 맥락을 파악하지 못하고 그 뜻을 embedding하는 것으로 이는 word2vec의 한계입니다.
Where we were: pretrained word embeddings
2017년 쯔음, word2vec의 진화한 버전으로서 여전히 맥락을 이용하지 않는 word embedding모델들이 사용되었습니다.
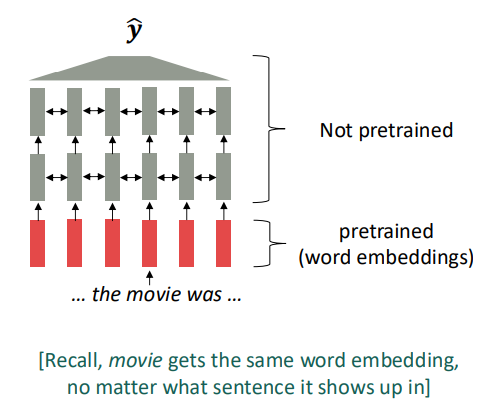
이는 여러 가지 문제점들이 있었습니다. 예를 들어 (1) 하위 태스크를 훈련 시키는데에 필요한 데이터의 양이 충분하지 않다면 언어의 맥락적인 모든 요소들을 학습시키기 충분하지 않을 수 있습니다. 그리고 대부분의 하위 태스크 데이터는 불충분한 경향이 있습니다. (2) 또한 대부분의 파라미터가 랜덤하게 초기화됩니다. 이는 word embedding부분만 pretrained되었지만, 다른 부분들은 pretrained되지 않음으로써 데이터들이 단어의 맥락을 파악하는데 파라미터들을 업데이트하지 않을 수 있습니다.
Where we're going: pretrained whole models
현대의 NLP에서는 모든 네트워크들을 pretraining을 통해 초기화합니다.
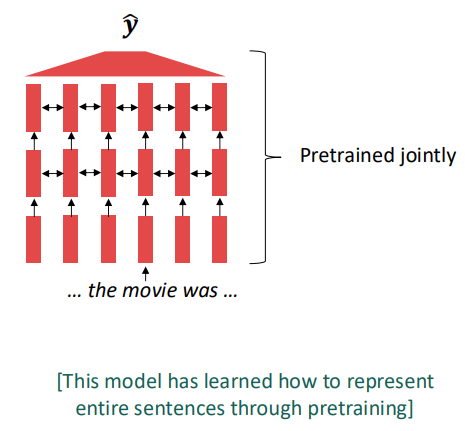
이를 통해 (1) 맥락에 따라, 학습하는 데이터에 따라 단어의 뜻이 다르게 임베딩 될 수 있으며, (2) 모든 파라미터들을 사전학습 시키기 때문에 랜덤한 값으로 초기화하는 것보다 더 나은 모델이 될 수 있습니다.
Pretraining through language modeling [Dai and Le, 2015]
language modeling 태스크로 돌아와보면 이는 이전의 어떤 입력들이 들어왔을 때, 그 다음 토큰을 예측해서 출력하는 태스크입니다. 이 태스크를 위한 데이터는 정말 많습니다. 그냥 매우 매우 많은 양의 텍스트 줄글 데이터만 있으면 되기 때문입니다.
이렇게 사전학습을 언어 모델에 대해 수행하면, 사전학습이 된 파라미터는 그대로 저장되어 이후 하위 태스크에 맞게 파인튜닝 됩니다.
The Pretraining / Finetuning Paradigm
사전학습 후 미세조정을 하는 이 패러다임은 많은 NLP 태스크에서 사용됩니다.
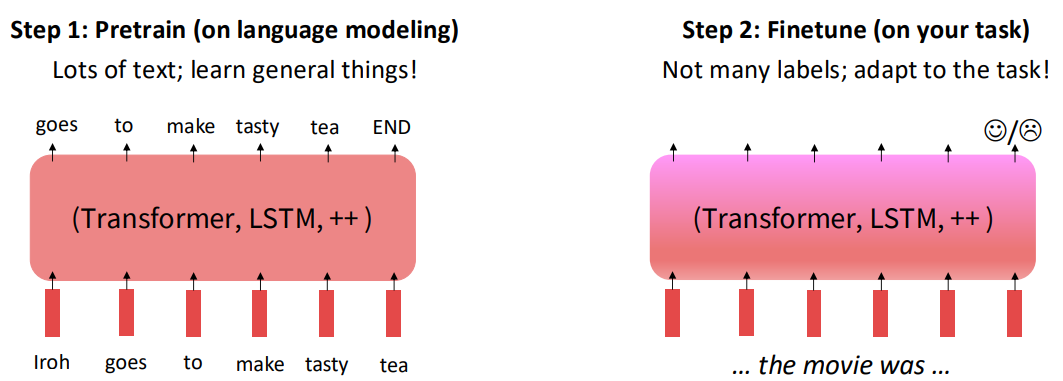
*사전 학습에 사용되는 데이터의 양은 매우 많은데 비해, downstream task에 대한 레이블링된 데이터의 경우 데이터를 확보하기 매우 어렵습니다. 이 때문에 먼저 사전학습을 통해 많은 양의 데이터를 학습하며 언어의 일반적인 특징들을 학습하며, downstream task에 맞는 데이터를 통해 내가 수행하고자 하는 태스크에 모델을 적응시키는 것입니다.
*transformer의 층이 여러개인 것은 층마다 입력을 context에 맞게 변형하는 것으로 해석할 수 있습니다. Multi-layered LSTM을 이용해서 word embedding을 수행하는 것과 유사한 맥락입니다. 이를 통해 w2v은 한 단어에 대해 하나의 벡터밖에 없었다는 점을 보완합니다.
Stochastic gradient descent and pretrain/finetune
경사 하강, 손실 함수의 측면에서 이를 해석해보면 다음과 같습니다:

다시 말해, pretrain을 통해서 내려가는 경사는 큰 범위에서 downstream task가 내려가야하는 경사와 유사할 것입니다. 이런 관점에서 미리 사전학습을 통해 어느정도 경사를 내려온 후 downstream task 데이터를 이용해 해당 태스크에 맞는 경사로 내려온다면 더욱 효율적으로 학습할 수 있는 것입니다.
Pretraining for three types of architectures
인코더, 인코더-디코더, 디코더 이 세 종류의 구조의 사전학습에 대해 알아보겠습니다.

Pretraining encoders: what pretraining objective to use?
지금까지는 language modeling의 사전학습에 대해서만 봤습니다. 그렇다면 양방향으로 참조가 가능한 인코더의 경우는 어떻게 학습시킬 수 있을까요? 바로 MASK입니다.
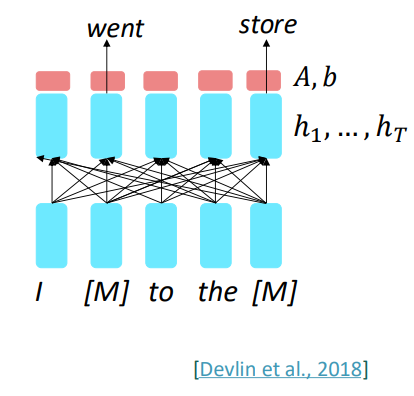
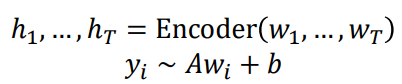
입력 문장들 중 임의의 단어들을 스페셜 토큰 [MASK]를 통해 가려준 후, 해당 단어를 예측하는 방식으로 학습합니다. 그리고 mask된 단어들에 대해서만 loss값을 구해 더해줌으로써 loss값을 구합니다. 즉, masked된 입력 x_tilda가 주어졌을 때, x를 예측 (Pθ(x|x_tilda))하는 태스크입니다. 이를 Masked LM이라고 부릅니다.
BERT: Bidirectional Encoder Representations from Transformers
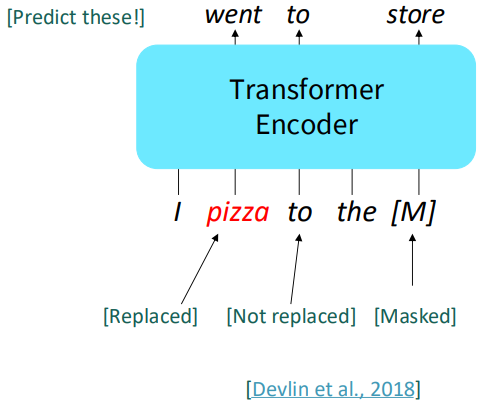
BERT는 Masked LM을 이용해 나온 트랜스포머 모델입니다. 이는 입력 문장의 80%를 [MASK]처리, 10%를 랜덤한 토큰으로 바꾸고, 나머지 10%를 그대로 냅둔 후, 진짜 문장 x를 예측하는 방식으로 학습됩니다.
이때 사전학습 시에 BERT의 입력은 다음과 같이 두 청크로 나뉩니다:
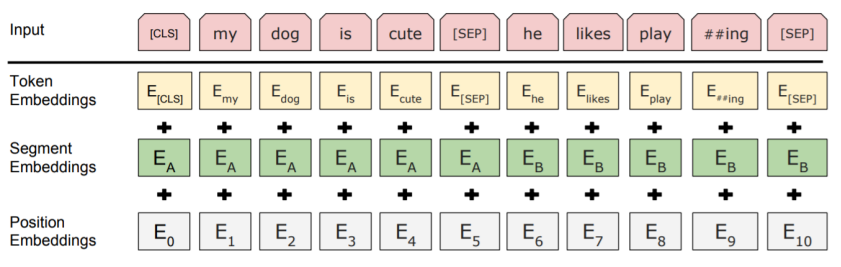
청크의 구분은 segment embedding의 값을 보면 알 수 있습니다. Token embedding, segment embedding, position embedding의 값을 element-wise addition을 통해 합쳐서 입력 문장을 구성합니다. BERT는 두 청크가 바로 이어지는 청크인지, 아니면 랜덤하게 선택된 청크인지를 판단하는 방식으로 학습하기도 합니다. 이를 통해 long distance dependency 또한 학습할 수 있는 것입니다. *[CLS]의 output이 chunk A와 chunk B가 연결되어있는지 아닌지를 return합니다.
BERT는 110m params를 갖는 BERT-base와 340m params를 갖는 BERT-large로 구분되며, 64개의 TPU를 통해 4일동안 사전학습 시켰습니다.
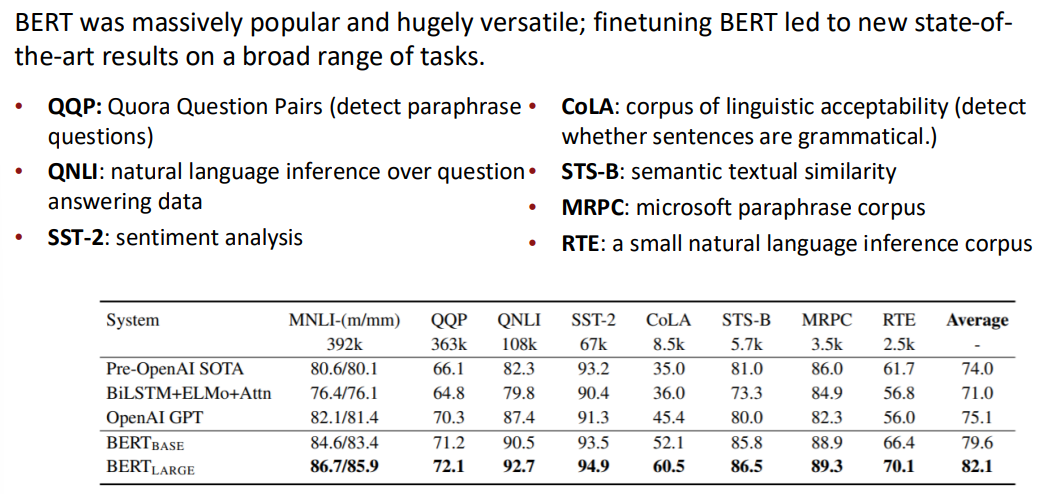
BERT는 여러 태스크에서 우수한 결과를 보였습니다:
Limitations of pretrained encoders
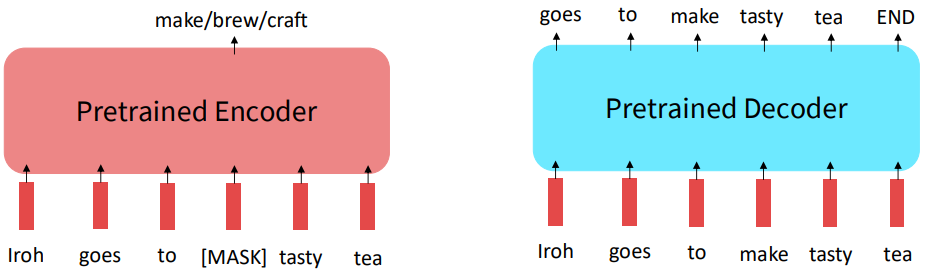
하지만 사전학습한 인코더의 경우 디코더와 달리 출력의 형태가 제한적이라는 단점이 있습니다.
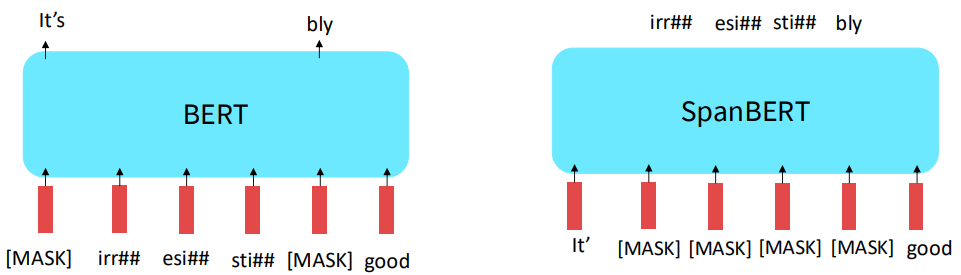
Extensions of BERT
그래서 BERT의 확장판인 RoBERTa와 SpanBERT등등이 등장했습니다. RoBERTa의 경우 next sentence prediction을 없앤 버전으로 일반 BERT보다 더 나은 성능을 보였습니다. SpanBERT의 경우 입력 문장의 일부분을 통째로 [MASK]처리하여 좀 더 어려운 예측 태스크를 수행합니다.
Pretraining encoder-decoders: what pretraining objective to use?
인코더-디코더의 경우 디코더가 있기 때문에 language modeling과 같은 방법으로 학습할 수 있습니다. 또한 인코더가 존재하기 때문에 인코더에 들어가는 문장을 일종의 prefix로 두어 언어를 생성할 수 있습니다.
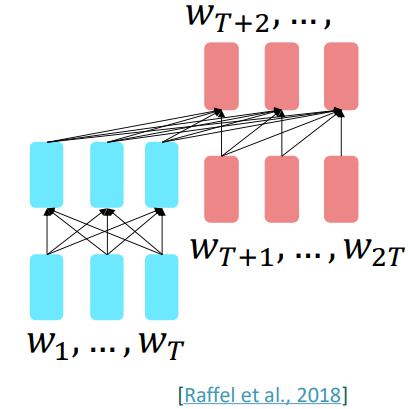
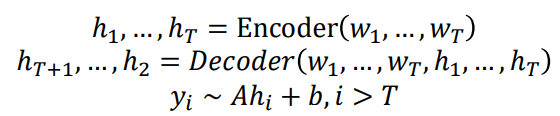
이에 대표적인 예가 T5입니다. T5는 Raffel et al., 2018에서 처음 등장했으며 salient span masking을 통한 언어 모델링을 이용했습니다. 즉, 입력의 특정 부분을 masking처리 한 후, masking된 부분을 디코더에서 언어 모델링 방식을 이용해 생성하는 것입니다.
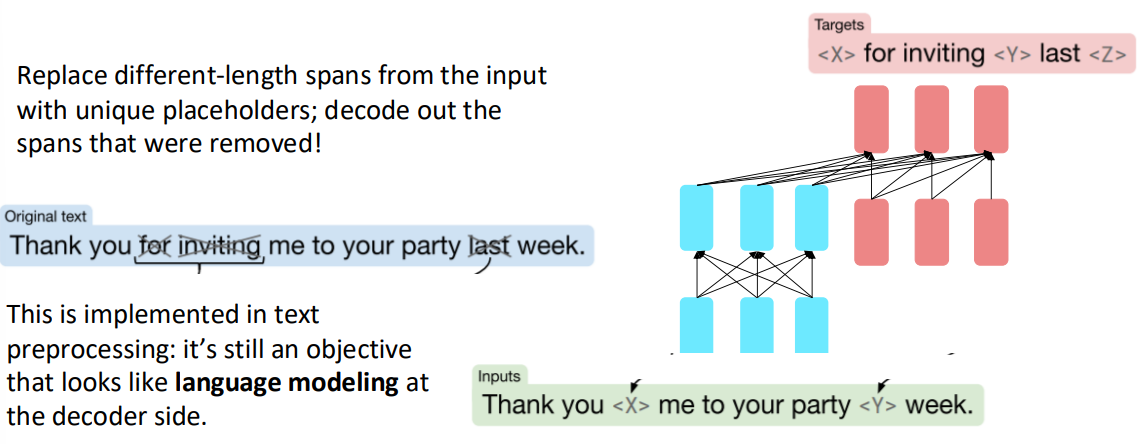
위 그림과 같이 원본 문장 Thank you for inviting me to your party last week 에서 for inviting 과 last 를 mask한 후, 입력에는 마스크된 입력을, 출력에서는 마스크된 부분을 맞추는 태스크를 통해 사전학습을 진행합니다.
이는 많은 task에서 우수한 성적을 보였습니다:
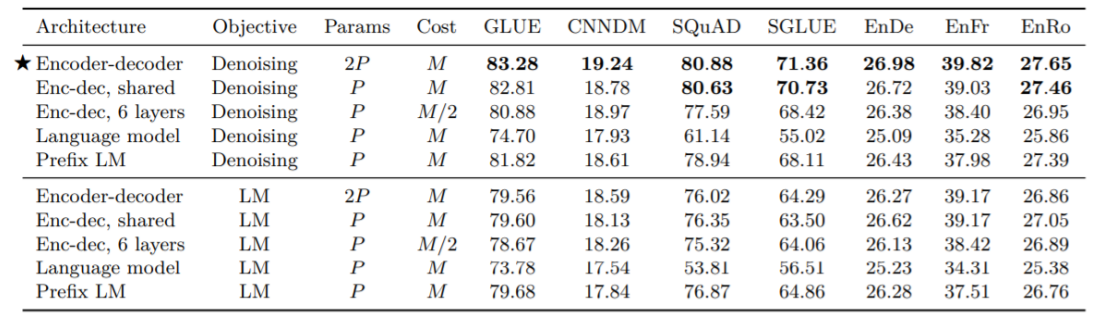
특이한 점은 T5는 QA를 fine-tuning할 수 있습니다:
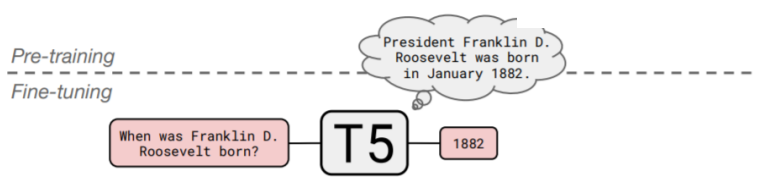
*하지만 뭐.. 성능이 그리 좋지는 않았습니다. 물론 초창기에는
Pretraining decoders
디코더를 사전학습하는 경우는 많이 봐왔습니다. 이전 입력들을 통해 다음 토큰을 예측하는 방식으로 사전학습이 이뤄집니다. 디코더를 이용하면 마지막 토큰의 출력을 이용해 분류 문제까지 풀 수도 있습니다:
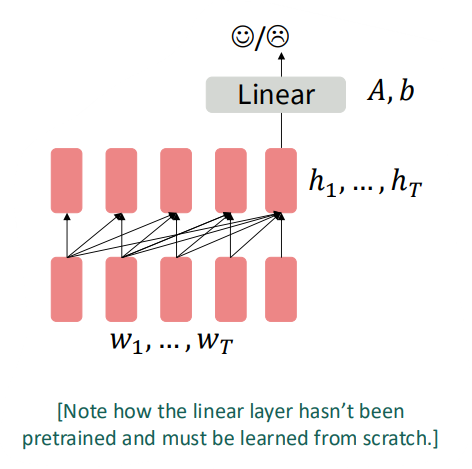
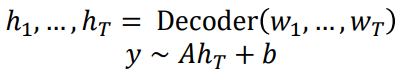
아니면 늘 그래왔듯, 언어 생성 태스크를 수행할 수도 있습니다.
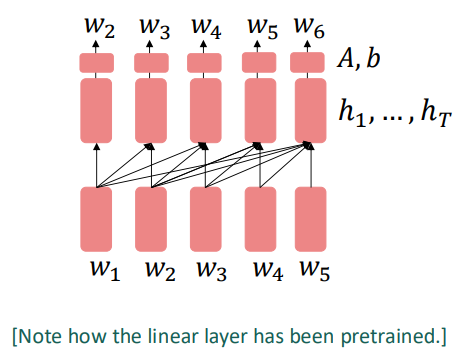
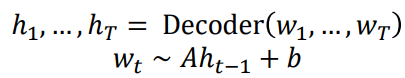
그리고 이를 통해서 dialogue나 summarization 태스크도 수행할 수 있습니다.
Generative Pretrained Transformer (GPT) [Radford et al., 2018]
GPT는 사전학습한 트랜스포머 디코더로 굉장한 성공을 이뤄냈습니다. 이는 12개의 layer와 117m params를 갖고 있으며, 768-dimensional hidden state, 3072-demensional feed-forward hidden layer를 가졌습니다.
GPT는 다음 토큰 생성 뿐만 아니라,
NLI (Natural Language Inference)를 포함하여, 여러 분류문제들 또한 매우 잘 풀어갔습니다.


Increasingly convincing generations (GPT2)
GPT-2는 GPT-1에 비해 1.5B params로 큰 모델입니다. 이를 통해 많은 양의 데이터를 학습하였고, 상대적으로 더 나은 성능을 보여주었습니다.

GPT-3, In-context learning, and very large models
지금까지는 prompt를 이용해서 조건부 확률의 조건이 되는 확률 분포를 조절하거나, fine-tune을 통해 태스크에 맞게 튜닝을 해주었지만, GPT-3의 in-context learning은 gradient step없이 downstream task에 맞게 튜닝할 수 있음을 보여주었습니다.
GPT-3는 매우 매우 큰 모델인데, T5의 경우 11B params를 갖는 반면, GPT-3의 경우 175B params를 갖고 있습니다. GPT-3는 in-context learning을 통해 입력의 일정한 패턴을 인식하여 문제를 해결할 수 있습니다:

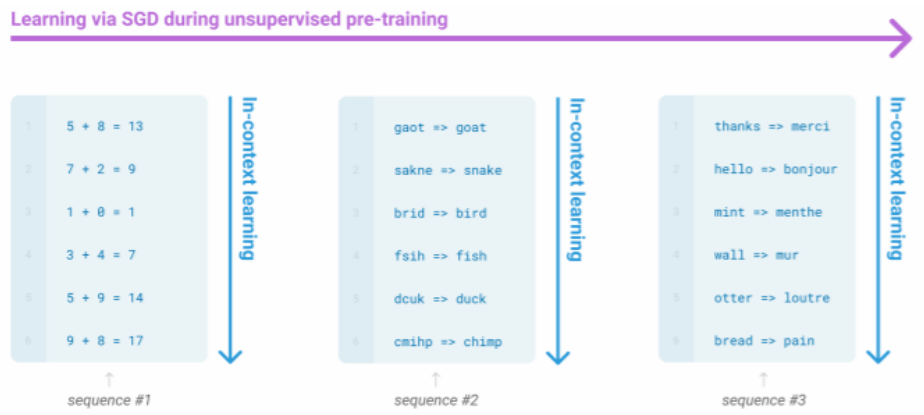
[Deep daiv.] NLP, 논문 리뷰 - Language Models are Few-Shot Learners (GPT-3)
https://arxiv.org/abs/2005.14165 Language Models are Few-Shot LearnersRecent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically tas
hw-hk.tistory.com
The prefix as task specification and scratch pad: chain-of-thought
in-context learning과 유사하게 prefix를 이용해 태스크를 특정짓고, 더 나아가 LLM이 이를 연습장처럼 사용할 수 있도록 하는 것이 chain-of-thought입니다.
[Deep daiv.] NLP, 논문 리뷰 - Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
https://arxiv.org/abs/2201.11903 Chain-of-Thought Prompting Elicits Reasoning in Large Language ModelsWe explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models t
hw-hk.tistory.com
Why scale? Scaling laws
그렇다면 왜 GPT-3에서는 175B까지 파라미터의 수를 늘렸을까요? 이는 scaling law때문입니다.
[Deep daiv.] NLP, 논문 리뷰 - Scaling Laws for Neural Language Models
https://arxiv.org/abs/2001.08361 Scaling Laws for Neural Language ModelsWe study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used
hw-hk.tistory.com
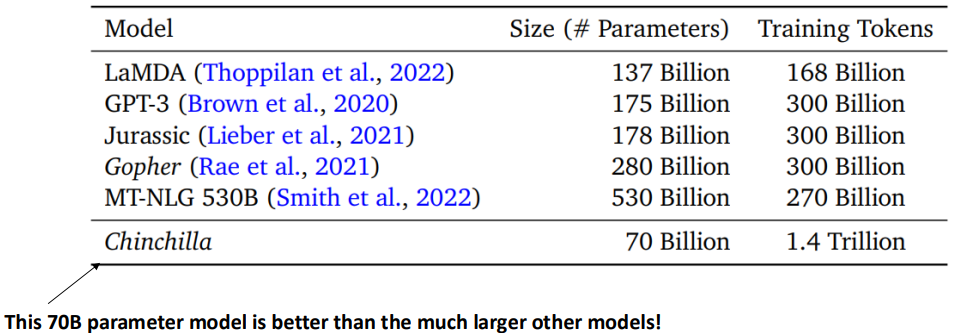
하지만 scale이 그냥 커진다고 무조건 성능이 좋아지는 것은 아닙니다. 즉 scaling efficiency가 존재합니다. 예를 들어 Chinchilla의 경우 70B 밖에 파라미터를 사용하지 않지만, 175B GPT-3 보다 더 나은 성능을 보입니다.